10 Things You Didn’t Know About Scikit-Learn
Check out these 10 things you didn’t know about Scikit-Learn... until now.
By Rebecca Vickery, Data Scientist

Scikit-learn is one of the most widely used Python machine learning libraries. It has a standardized and simple interface for preprocessing data and model training, optimisation and evaluation.
The project began life as a Google Summer of Code project developed by David Cournapeau and had its first public release in 2010. Since its creation, the library has evolved into a rich ecosystem for the development of machine learning models.
Over time the project has developed many handy functions and capabilities that enhance its ease of use. In this article, I will cover 10 of the most useful features that you might not know about.
1. Scikit-learn has built-in data sets
The Scikit-learn API has a variety of both toy and real-world datasets built-in. These can be accessed with a single line of code and are extremely useful if you are either learning or just want to quickly try out a new bit of functionality.
You can also easily generate synthetic data sets using the generators for regression make_regression() , clustering make_blobs() and classification make_classification().
All the loading utilities provide the option to return the data already split into X (features) and y (target) so that they can be used directly to train a model.
2. Third-party public data sets are also easily available
If you want to access a greater variety of publically available data sets directly through Scikit-learn there is a handy function that enables you to import data directly from the openml.org website. This website contains over 21,000 varied data sets for use in machine learning projects.
3. There are ready-made classifiers to train baseline models
When developing a machine learning model for a project it is sensible to create a baseline model first. This model should be in essence a ‘dummy’ model such as one that always predicts the most frequently occurring class. This provides a baseline on which to benchmark your ‘intelligent’ model so that you can ensure that it is performing better than random results for example.
Scikit-learn includes a DummyClassifier() for classification tasks and a DummyRegressor() for regression-based problems.
4. Scikit-learn has its own plotting API
Scikit-learn has a built-in plotting API which allows you to visualise model performance without importing any other libraries. The following plotting utilities are included; partial dependence plots, confusion matrix, precision-recall curves and the ROC curve.
import matplotlib.pyplot as plt from sklearn import metrics, model_selection from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import load_breast_cancer X,y = load_breast_cancer(return_X_y = True) X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, random_state=0) clf = RandomForestClassifier(random_state=0) clf.fit(X_train, y_train) metrics.plot_roc_curve(clf, X_test, y_test) plt.show()
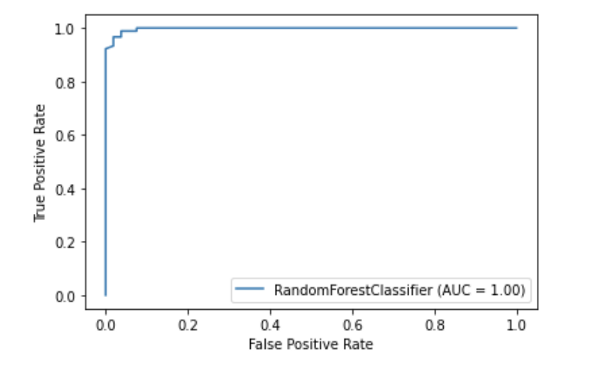
5. Scikit-learn has built-in feature selection methods
One technique to improve model performance is to train a model using only the best set of features or by removing redundant features. This process is known as feature selection.
Scikit-learn has a number of functions to perform feature selection. One example is known as SelectPercentile(). This method selects the top-performing X percentile features based on a chosen statistical method for scoring.
6. Pipelines allow you to chain together all the steps in a machine learning workflow
In addition to making available a wide range of algorithms for machine learning, Scikit-learn also has a range of functions for preprocessing and transforming data. To facilitate reproducibility and simplicity in the machine learning workflow, Scikit-learn created pipelines that allow you to chain together numerous preprocessing steps with the model training stage.
The pipeline stores all the steps in the workflow as a single entity which can be called via the fit and predict methods. When you call the fit method on a pipeline object the preprocessing steps and model training are performed automatically.
7. With the ColumnTransformer you can apply different preprocessing to different features
In many data sets, you will have different types of features that will require different preprocessing steps to be applied. For example, you may have a mix of categorical and numeric data, where you may want to convert the categorical data to numeric via one-hot encoding and scale the numeric variables.
The Scikit-learn pipeline has a function called ColumnTransformer which allows you to easily specify which columns to apply the most appropriate preprocessing to either via indexing or by specifying the column names.
8. You can easily output an HTML representation of your pipeline
Pipelines can often get quite complex particularly when working with real-world data. It is therefore very handy that Scikit-learn provides a method to output an HTML diagram of the steps in your pipeline.
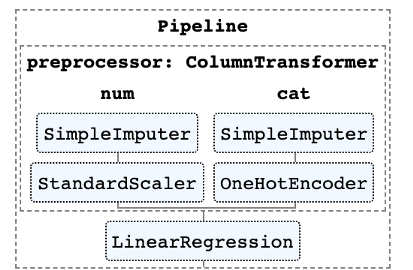
9. There is a plotting function to visualise trees
The plot_tree() function allows you to create a diagram of steps present in a decision tree model.
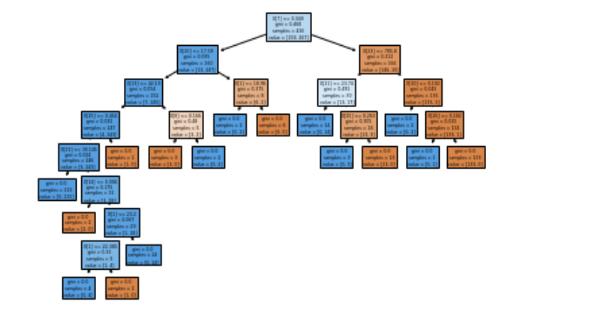
10. There are many third-party libraries that extend the features of Scikit-learn
Many third-party libraries are available that work with Scikit-learn and extend its features.
Two examples include the category-encoders library, which provides a greater range of preprocessing methods for categorical features, and the ELI5 package for greater model explainability.
Both of these packages can be also be used directly within a Scikit-learn pipeline.
Thanks for reading!
Bio: Rebecca Vickery is learning data science through self study. Data Scientist @ Holiday Extras. Co-Founder of alGo.
Original. Reposted with permission.
Related:
- Python Libraries for Interpretable Machine Learning
- Five Command Line Tools for Data Science
- Command Line Basics Every Data Scientist Should Know