Unpopular Opinion – Data Scientists Should Be More End-to-End
Can a do-it-all Data Scientist really be more effective at delivering new value from data? While it might sound exhausting, important efficiencies can exist that might bring better value to the business even faster.
By Eugene Yan, Applied Science at Amazon, Writer & Speaker.

Recently, I came across a Reddit thread on the different roles in data science and machine learning: data scientist, decision scientist, product data scientist, data engineer, machine learning engineer, machine learning tooling engineer, AI architect, etc.
I found this worrying. It’s difficult to be effective when the data science process (problem framing, data engineering, ML, deployment/maintenance) is split across different people. It leads to coordination overhead, diffusion of responsibility, and lack of a big picture view.
IMHO, I believe data scientists can be more effective by being end-to-end. Here, I’ll discuss the benefits and counter-arguments, how to become end-to-end, and the experiences of Stitch Fix and Netflix.
From start (identify the problem) to finish (solve it)
You may have come across similar labels and definitions, such as:
- Generalist: Focused on roles (PM, BA, DE, DS, MLE); some negative connotation
- Full-stack: Focused on tech (Spark, Torch, Docker); popularized by full-stack devs
- Unicorn: Focused on mythology; believed not to exist
I find these definitions to be more prescriptive than I prefer. Instead, I have a simple (and pragmatic) definition: An end-to-end data scientist can identify and solve problems with data to deliver value. To achieve the goal, they’ll wear as many (or as little) hats as required. They’ll also learn and apply whatever tech, methodology, and process that works. Throughout the process, they ask questions such as:
- What is the problem? Why is it important?
- Can we solve it? How should we solve it?
- What is the estimated value? What was the actual value?
Data Science Processes
Another way of defining end-to-end data science is via processes. These processes are usually complex and I’ve left them out of the main discussion. Nonetheless, here are a few in case you’re curious:
- CRISP-DM: Cross-Industry Standard Process for Data Mining (1997).
- KDD: Knowledge Discovery in Databases.
- TDSP: Team Data Science Process, proposed by Microsoft in 2018.
- DSLP: Data Science Lifecycle Process.
Don’t worry if these processes seem heavy and overwhelming. You don’t have to adopt them wholesale—start bit by bit, keep what works and adapt the rest.
.
More context, faster iteration, greater satisfaction
For most data science roles, being more end-to-end improves your ability to make a meaningful impact. (Nonetheless, there are roles that focus on machine learning.)
Working end-to-end provides increased context. While specialized roles can increase efficiency, it reduces context (for the data scientist) and leads to suboptimal solutions.
The trick to forgetting the big picture is to look at everything close-up. – Chuck Palahniuk
It’s hard to design a holistic solution without the full context of the upstream problem. Let’s say conversion has decreased, and a PM raises a request to improve our search algorithm. However, what’s causing the decrease in the first place? There could be various causes:
- Product: Is fraudulent/poor quality products reducing customer trust?
- Data pipelines: Has data quality been compromised, or are there delays/outages?
- Model refresh: Is the model not refreshing regularly/correctly?
More often than not, the problem—and solution—lies outside of machine learning. A solution to improve the algorithm would miss the root cause.
Similarly, it’s risky to develop a solution without awareness of downstream engineering and product constraints. There’s no point:
- Building a near-real time recommender if infra and engineer cannot support it
- Building an infinite scroll recommender if it doesn’t fit in our product and app
By working end-to-end, data scientists will have the full context to identify the right problems and develop usable solutions. It can also lead to innovative ideas that specialists, with their narrow context, might miss. Overall, it increases the ability to deliver value.
Communication and coordination overhead is reduced. With multiple roles comes additional overhead. Let’s look at an example of a data engineer (DE) cleaning the data and creating features, a data scientist (DS) analysing the data and training the model, and a machine learning engineer (MLE) deploying and maintaining it.
What one programmer can do in one month, two programmers can do in two months. – Frederick P. Brooks
The DE and DS need to communicate on what data is (and is not) available, how it should be cleaned (e.g., outliers, normalisation), and which features should be created. Similarly, the DS and MLE have to discuss how to deploy, monitor, and maintain the model, as well as how often it should be refreshed. When issues occur, we’ll need three people in the room (likely with a PM) to triage the root cause and next steps to fix it.
It also leads to additional coordination, where schedules need to be aligned as work is executed and passed along in a sequential approach. If the DS wants to experiment with additional data and features, we’ll need to wait for the DE to ingest the data and create the features. If a new model is ready for A/B testing, we’ll need to wait for the MLE to (convert it to production code) and deploy it.
While the actual development work may take days, the communication back-and-forth and coordination can take weeks, if not longer. With end-to-end data scientists, we can minimize this overhead as well as prevent technical details from being lost in translation.
(But, can an end-to-end DS really do all that? I think so. While the DS might not be as proficient in some tasks as a DE or MLE, they will be able to perform most tasks effectively. If they need help with scaling or hardening, they can always get help from specialist DEs and MLEs.)
The Cost of Communication and Coordination
Richard Hackman, a Harvard psychologist, showed that the number of relationships in a team is N(N-1) / 2, where N is the number of people. This leads to exponential growth in links, where:
- A start-up team of 7 has 21 links to maintain
- A group of 21 (i.e., three start-up teams) has 210 links
- A group of 63 has almost 2,000 links.
In our simple example, we only had three roles (i.e., six links). But as a PM, BA, and additional members are included, this leads to greater than linear growth in communication and coordination costs. Thus, while each additional member increases total team productivity, the increased overhead means productivity grows at a decreasing rate. (Amazon’s two-pizza teams are a possible solution to this.)
Iteration and learning rate is increased. With greater context and lesser overhead, we can now iterate, fail (read: learn), and deliver value faster.
This is especially important for developing data and algorithmic products. Unlike software engineering (a far more mature craft), we can’t do all the learning and design before we start building—our blueprints, architectures, and design patterns are not as developed. Thus, rapid iteration is essential for the design-build-learn cycle.
There’s greater ownership and accountability. Having the data science process split across multiple people can lead to diffusion of responsibility, and worse, social loafing.
A common anti-pattern observed is “throw over the wall.” For example, the DE creates features and throws a database table to the DS, the DS trains a model and throws R code over to the MLE, and the MLE translates it to Java to production.
If things get lost-in-translation or if results are unexpected, who is responsible? With a strong culture of ownership, everyone steps up to contribute in their respective roles. But without it, work can degenerate into ass-covering and finger-pointing while the issue persists and customers and the business suffers.
Having the end-to-end data scientist take ownership and responsibility for the entire process can mitigate this. They should be empowered to take action from start to finish, from the customer problem and input (i.e., raw data) to the output (i.e., deployed model) and measurable outcomes.
Diffusion of Responsibility & Social Loafing
Diffusion of responsibility: We are less likely to take responsibility and act when there are others present. Individuals feel less responsibility and urgency to help if we know that there are others also watching the situation.
One form of this is the Bystander effect, where Kitty Genovese was stabbed outside the apartment building across the street from where she lived. While there were 38 witnesses who saw or heard the attack, none called the police or helped her.
Social loafing: We exert less effort when we work in a group vs. working alone. In the 1890s, Ringelmann made people pull on ropes both separately and in groups. He measured how hard they pulled and found that members of a group tended to exert less effort in pulling a rope than did individuals alone.
For (some) data scientists, it can lead to increased motivation and job satisfaction, which is closely tied to autonomy, mastery, and purpose.
- Autonomy: By being able to solve problems independently. Instead of waiting and depending on others, end-to-end data scientists are able to identify and define the problem, build their own data pipelines, and deploy and validate a solution.
- Mastery: In the problem, solution, outcome from end-to-end. They can also pick up the domain and tech as required.
- Purpose: By being deeply involved in the entire process, they have a more direct connection with the work and outcomes, leading to an increased sense of purpose.
But, we need specialist experts too
Being end-to-end is not for everyone (and every team) though, for reasons such as:
Wanting to specialize in machine learning, or perhaps a specific niche in machine learning such as neural text generation (read: GPT-3 primer). While being end-to-end is valuable, we also need such world-class experts in research and industry who push the envelope. Much of what we have in ML came from academia and pure research efforts.
No one achieves greatness by becoming a generalist. You don’t hone a skill by diluting your attention to its development. The only way to get to the next level is focus. – John C. Maxwell
Lack of interest. Not everyone is keen to engage with customers and businesses to define the problem, gather requirements, and write design documents. Likewise, not everyone is interested in software engineering, production code, unit tests, and CI/CD pipelines.
Working on large, high leverage systems where 0.01% improvement has giant impact. For example, algorithmic trading and advertising. In such situations, hyper-specialization is required to eke out those improvements.
Others have also made arguments for why data scientists should specialize (and not be end-to-end). Here are a few articles to provide balance and counter-arguments:
- Why You Shouldn’t Be A Data Science Generalist
- Why Every Data Scientist Needs to Specialize
- Want a Job in Data Science? Here’s Why You Should Specialize
The best way to pick it up is via learning by doing
If you’re still keen on becoming more end-to-end, we’ll now discuss how to do so. Before that, without going into specific technologies, here are the buckets of skills that end-to-end data scientists commonly use:
- Product: Understand customer problems, define and prioritize requirements
- Communication: Facilitate across teams, get buy-in, write docs, share results
- Data engineering: Move and transform data from point A to B
- Data analysis: Understand and visualize data, A/B testing & inference
- Machine learning: The usual plus experimentation, implementation, and metrics
- Software engineering: Production code practices including unit tests, docs, logging
- Dev Ops: Basic containerization and cloud proficiency, build and automation tools
(This list is neither mandatory nor exhaustive. Most projects don’t require all of them.)
Here are four ways you can move closer to being an end-to-end data scientist:
Study the right books and courses. (Okay, this is not learning by doing, but we all need to start somewhere). I would focus on courses that cover tacit knowledge rather than specific tools. While I’ve not come across such materials, I’ve heard good reviews about Full Stack Deep Learning.
Do your own projects end-to-end to get first-hand experience of the entire process. At the risk of oversimplifying it, here are some steps I would take with their associated skills.
I hear and I forget. I see and I remember. I do and I understand. – Confucius
Start with identifying a problem to solve and determining the success metric (product). Then, find some raw data (i.e., not Kaggle competition data); this lets you clean and prepare the data and create features (data engineering). Next, try various ML models, examining learning curves, error distributions, and evaluation metrics (data science).
Assess each model’s performance (e.g., query latency, memory footprint) before picking one and writing a basic inference class around it for production (software engineering). (You might also want to build a simple user interface). Then, containerise and deploy it online for others to use via your preferred cloud provider (dev ops).
Once that’s done, go the extra mile to share about your work. You could write an article for your site or speak about it at a meetup (communication). Show what you found in the data via meaningful visuals and tables (data analysis). Share your work on GitHub. Learning and working in public is a great way to get feedback and find potential collaborators.
Volunteer through groups like DataKind. DataKind works with social organizations (e.g., NGOs) and data professionals to address humanitarian issues. By collaborating with these NGOs, you get the opportunity to work as part of a team to tackle real problems with real(ly messy) data.
While volunteers may be assigned specific roles (e.g., PM, DS), you’re always welcome to tag along and observe. You’ll see (and learn) how PMs engage with NGOs to frame the problem, define solutions, and organize the team around it. You’ll learn from fellow volunteers how to work with data to develop working solutions. Volunteering in hackathon-like DataDives and longer-term DataCorps is a great way to contribute to the data science process end-to-end.
Join a startup-like team. Note: A startup-like team is not synonymous with a startup. There are big organizations that run teams in a startup-like manner (e.g., two-pizza teams) and startups made up of specialists. Find a lean team where you’re encouraged, and have the opportunity, to work end-to-end.
End-to-end in Stitch Fix and Netflix
Eric Colson of Stitch Fix was initially “lured to a function-based division of labour by the attraction of process efficiencies” (i.e., the data science pin factory). But over trial and error, he found end-to-end data scientists to be more effective. Now, instead of organizing data teams for specialization and productivity, Stitch Fix organizes them for learning and developing new data and algorithmic products.
The goal of data science is not to execute. Rather, the goal is to learn and develop new business capabilities. … There are no blueprints; these are new capabilities with inherent uncertainty. … All the elements you’ll need must be learned through experimentation, trial and error, and iteration. – Eric Colson
He suggests that data science roles should be made more general, with broad responsibilities agnostic to technical function and optimized for learning. Thus, his team hires and grows generalists who can conceptualize, model, implement, and measure. Of course, this is dependent on a solid data platform that abstracts away the complexities of infra setup, distributed processing, monitoring, automated failover, etc.
Having end-to-end data scientists improved Stitch Fix’s learning and innovation capabilities, enabling them to discover and build more business capabilities (relative to a specialist team).
Netflix Edge Engineering initially had specialized roles. However, this created inefficiencies across the product life cycle. Code releases took more time (weeks instead of days), deployment problems took longer to detect and resolve, and production issues required multiple back-and-forth communications.
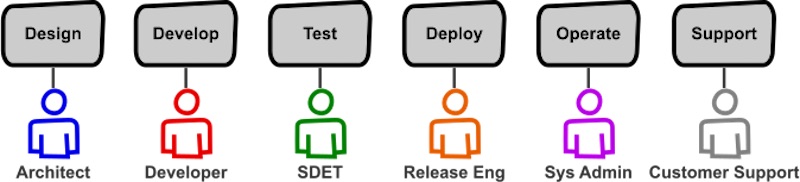
At the extreme, each function area/product is owned by 7 people (source).
To address this, they experimented with Full Cycle Developers who were empowered to work across the entire software life cycle. This required a mindset shift—instead of just considering design and development, devs also had to consider deployment and reliability.
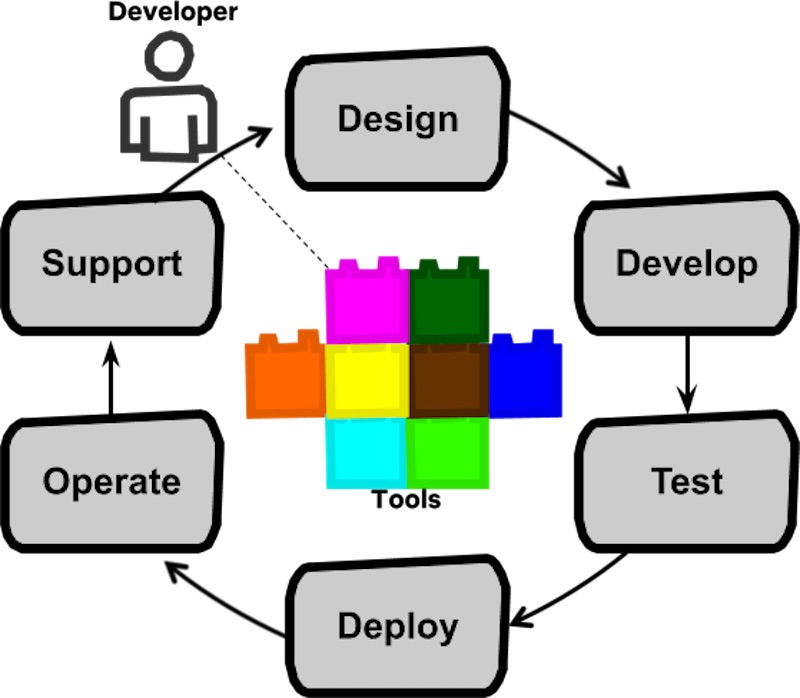
Instead of multiple roles and people, we now have the full cycle dev (source).
To support full cycle devs, centralized teams built tooling to automate and simplify common development processes (e.g., build and deploy pipelines, monitoring, managed rollbacks). Such tooling is reusable across multiple teams, acts as a force multiplier, and helped devs be effective across the entire cycle.
With the full cycle developer approach, Edge Engineering was able to iterate quicker (instead of coordinating across teams), with faster and more routine deployments.
Did it work for me? Here are a few examples
At IBM, I was on a team that created job recommendations for staff. Running the entire pipeline took a very long time. I thought we could halve the time by moving the data prep and feature engineering pipelines into the database. But, the database guy didn’t have time to test this. Being impatient, I ran some benchmarks and reduced overall run time by 90%. This allowed us to experiment 10x faster and save on compute costs in production.
While building Lazada’s ranking system, I found Spark necessary for data pipelines (due to the large data volume). However, our cluster only supported the Scala API, which I was unfamiliar with. Not wanting to wait (for data engineering support), I chose the faster—but painful—route of figuring out Scala Spark and writing the pipelines myself. This likely halved dev time and gave me a better understanding of the data to build a better model.
After a successful A/B test, we found that business stakeholders didn’t trust the model. As a result, they were manually picking top products to display, decreasing online metrics (e.g., CTR, conversion). To understand more, I made trips to our marketplaces (e.g., Indonesia, Vietnam). Through mutual education, we were able to address their concerns and reduce the amount of manual overwriting and reap the gains.
In the examples above, going out of the regular DS & ML job scope helped with delivering more value, faster. In the last example, it was necessary to unblock our data science efforts.
Try it out
You may not be end-to-end now. That’s okay—few people are. Nonetheless, consider its benefits and stretching closer towards it.
Which aspects would disproportionately improve your ability to deliver as a data scientist? Increased engagement with customers and stakeholders to design more holistic, innovative solutions? Building and orchestrating your own data pipelines? Greater awareness of engineering and product constraints for faster integration and deployments?
Unpopular view: Data scientists should be more end-to-end.
While this is frowned upon (too generalist!), I've seen it lead to more context, faster iteration, greater innovation—more value, faster.
More details and Stitch Fix & Netflix's experience ???? https://t.co/aOBjuBSsSz
— Eugene Yan (@eugeneyan) August 12, 2020
Original. Reposted with permission.
Bio: Eugene Yan (@eugeneyan) works at the intersection of consumer data and tech to build machine learning systems that help customers. Eugene also writes about how to be effective in data science, learning, and career. Currently, Eugene is an Applied Scientist at Amazon helping users read more, and get more out of reading.
Related: