MathWorks Deep learning workflow: tips, tricks, and often forgotten steps
Getting started in deep learning – and adopting an organized, sustainable, and reproducible workflow – can be challenging. This blog post will share some tips and tricks to help you develop a systematic, effective, attainable, and scalable deep learning workflow as you experiment with different deep learning models, datasets, and applications.
By Oge Marques, Ph.D., professor of computer science and engineering in the College of Engineering and Computer Science at Florida Atlantic University
Deep learning is here to stay and has significantly impacted a number of areas (computer vision, speech recognition, natural language processing, and game playing, among others) and tasks (image classification, object detection, automatic image captioning, language translation, and many more) in the past few years.
Getting started in deep learning – and adopting an organized, sustainable, and reproducible workflow – can be challenging. This is a highly interactive and iterative process which consists, to a certain degree, in working on a trial-and-error basis (but not quite… there is a "method to the madness").
In this blog post, I will share some tips and tricks to help you develop a systematic, effective, attainable, and scalable deep learning workflow as you experiment with different deep learning models, datasets, and applications. In my experience as professor and researcher, these recommendations may provide valuable assistance to those who are trying to get up to speed in deep learning, from developers and practitioners writing code for training deep neural networks to managers and executives in charge of leading development teams and defining strategies for use of Artificial Intelligence solutions in their products and services.
A traditional deep learning workflow (Figure 1) consists of four main steps:
- Prepare the data
- Define the network
- Train the network
- Deploy the trained model

These are essential steps, which usually take a substantial time (from both human and computers) to get right. They do not represent, however, the entire picture. In this blog post, I’d like to propose a more comprehensive deep learning workflow that teams should consider adopting to deliver the best possible results for their project.
The proposed deep learning workflow (inspired by [1] and [2]) includes five additional steps (indicated in dark gray in Figure 2) that are often forgotten but are, nonetheless, extremely important. This blog post will give special attention to those steps and show how they integrate with the deep learning workflow as a cohesive whole.
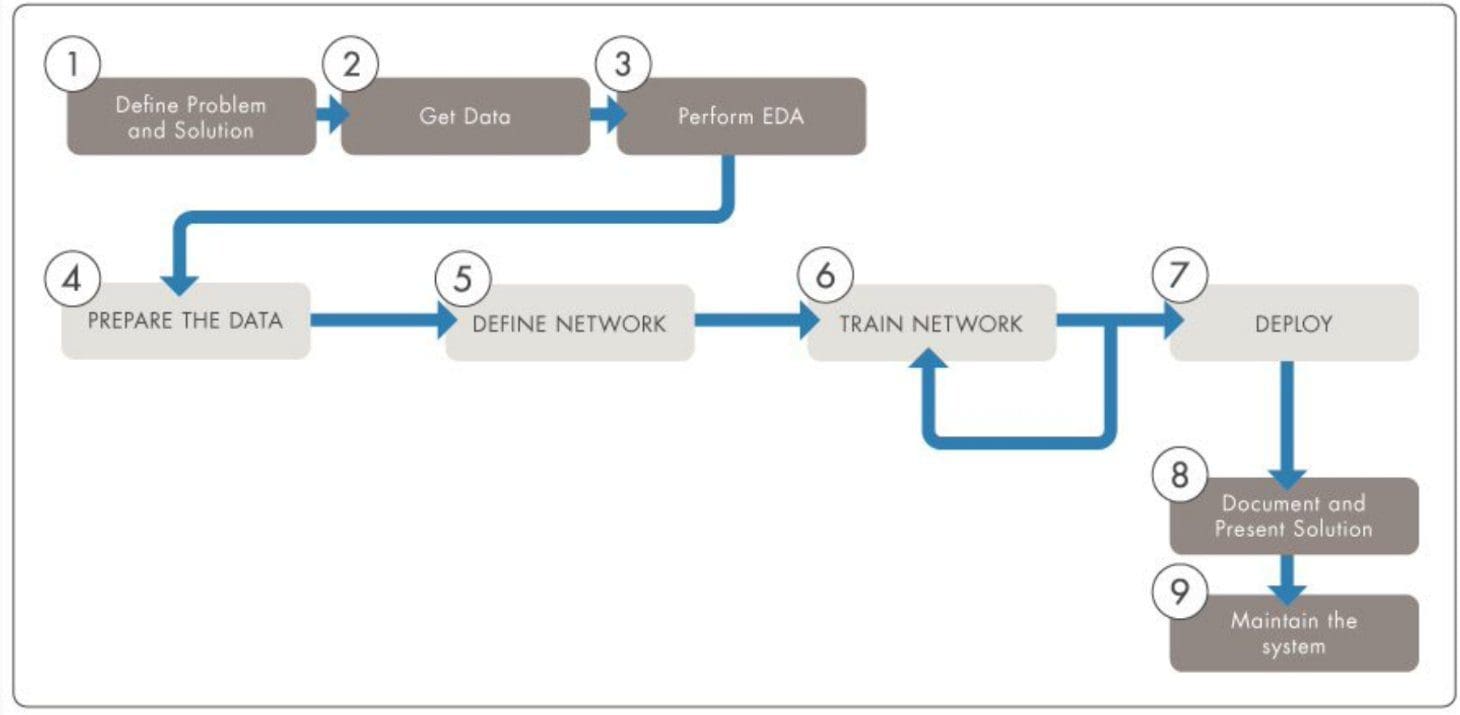
Let's explore the improved deep learning workflow in more detail.
1. Define the problem and write down what a successful solution looks like
No deep learning project (except, perhaps, for "toy problems" and purely exploratory experimentation) occurs in a vacuum. As you begin a new project – before rushing to collect data, select candidate models, and enter the time-consuming process of several rounds of training your neural networks – you should take the time to fully understand the problem at hand.
Speak with the right constituencies (your boss, customer, colleagues) and ask as many questions as needed to clearly frame the problem, picture the "ideal" solution, and contextualize the problem in terms of the company's business objectives. In the case of academic projects, try to understand how the problem at hand related to the lab's research agenda and goals, as well as the promises and deliverables associated with ongoing grants and contracts.
Once you understand the problem, invest time searching the scientific literature and prior art, checking to see what the existing solutions are, how they have been documented, and what are their limitations.
Next, select a performance measure that is compatible with the project's goals and aligned with the business objectives, check to see if human expertise in the problem (to advise the deep learning team) will be available along the way, write down any assumptions you (or others) have made, and verify those assumptions, if possible.
At the end of this step you should have a clearly documented vision of the problem, desired solution, candidate evaluation metrics and benchmarks, as well as the context and expectations of the interested constituencies.
2. Get data
Once the problem has been clearly specified (step 1), it’s time to collect the appropriate type and amount of data for the task. For real-world applications, this step may involve complex legal, financial, and system administration operations (to get authorizations, acquire, and store the data). When designing and running early experiments and proof-of-concept solutions, however, this step may be as simple as selecting a publicly available dataset that might be suitable for the task at hand.
There are a few common mistakes and traps you should try to avoid at this stage:
- Not collecting enough data. This is trickier than it appears at first glance, since, after all, the answer to the question "How much data do I need for this?" varies tremendously between one project and the next, and so does the availability of data (e.g., images of dogs and cats are much easier to find than specialized medical images depicting rare pathologies).
- Underestimating (or overlooking altogether) the important aspect of the quality of the data. Since most deep learning solutions operate under the supervised learning paradigm, it is essential that the annotations (labels) associated with the data samples be as accurate as possible.
- Believing that acquiring enormous amounts of data, by itself, will be enough to ensure the project's success. This belief can backfire in several ways, including the cost of acquiring such data, the additional overhead required to store, clean up, and organize the data, and the unwarranted sense of confidence that "now that we have all this data, all the remaining steps will be trivial."
During this step, you should also ensure that any sensitive information (e.g., patient's protected health information (PHI) in medical deep learning solutions) has been de-identified, deleted or protected somehow. Overlooking these aspects may lead to serious problems in terms of public image, consumer trust, as well as legal and financial consequences.
At the end of this step you should have acquired enough high-quality data to enable training, validating, and testing your deep learning models. You should also have performed the necessary format conversions to make the data manageable for analysis and exploration (step 3).
3. Perform exploratory data analysis (EDA) to gain insights
This step, also referred to as data wrangling, is absolutely crucial to the success of the entire workflow. It involves cleaning up the data, understanding its structure and attributes, studying possible correlations between attributes, and visualizing the data so as to extract human-level insight on its properties, distribution, range, and overall usefulness. Visualization is a fundamental step in EDA. In the words of the late and great Hans Rosling: “The world cannot be understood without numbers. And it cannot be understood with numbers alone.” [6]
There is a common misconception in deep learning: the notion that the deep neural networks' (remarkable, to be sure!) ability to extract patterns and rules from data eliminates the need for human exploration of the data and its properties. In my experience, nothing replaces spending quality time with your data, understanding and trusting it, before moving any further. I advise you to invest as much time as you can exploring your data. To be clear, we are not trying to explore the data in the hope that human-derived (and easy to code in a traditional, rule-based, approach of the 1980s AI) patterns will emerge from the data; if that was the case, we probably wouldn't need a deep learning approach to begin with! What we want is to get a clear sense of what the data at hand warrants in terms of pattern finding and how much we can trust the data.
At the end of this step you should be convinced that you understand and trust your data for your deep learning project.
4. Prepare the data for your deep learning algorithm
Once your data has been acquired, sanitized, and explored manually, it’s time to prepare it to be used by your deep neural network of choice. The traditional tasks at this step involve setting aside a test set (to be used in step 7) and using the rest of the data for training and validation. Note that the details of how to prepare and preprocess your data might depend on your choice of architecture (step 5), which reinforces the iterative/cyclical nature of this process.
Moreover, especially if your dataset is small, you should consider using data augmentation, a process used to augment the existing dataset in a way that is more cost-effective than further data collection. In the case of image classification applications, for example, data augmentation is usually accomplished using simple geometric transformation techniques randomly applied to the original images, such as cropping, rotating, resizing, translating, and flipping.
At the end of this step you should have defined training, validation and test sets and ensured that your data is formatted in accordance to the input size and format required by the deep neural network selected for your project.
5. Define network
- Select candidate architecture
This step looks easy on the surface, since there are relatively few (families of) architectures to consider for a certain task: e.g., convolutional neural networks (CNNs or ConvNets) for image classification or recurrent neural networks (RNNs) with long short-term memory (LSTM) cells for text and sequence data types of applications. The choice of baseline architecture is often dictated by the model that is currently considered the most useful by the scientific community at large, e.g., YOLO (You Only Look Once) for object detection or BERT (Bidirectional Encoder Representations from Transformers) [7] for natural language processing (NLP).The flipside of the apparent simplicity of this step will appear in steps 6 and 7, since there are usually several different ways to go about training a deep neural network for a certain task and the iterative process of trying different combinations of (hyper)parameters that might lead to the best performance is significantly more time-consuming than in the conventional machine learning case, where most algorithms have few parameters to select and fine-tune.
- Transfer Learning or not? That's the question.
At this step you should consider whether the transfer learning paradigm might apply to your problem. Transfer learning, essentially, consists of using a deep neural network that has been pre-trained in a large dataset of similar nature to the problem you are trying to solve. This is usually accomplished by retraining some of its layers (while freezing the rest) in a way that achieves "the best of both worlds" – by leveraging the knowledge encoded in the model and adapting it to the new problem in a way that takes a fraction of the time (and the amount of data) that would be required to train the same network architecture from scratch.Transfer learning has been successfully used in image classification – using neural network architectures pretrained on ImageNet (a large dataset of more than 1 million images in more than 1,000 categories) – as well as other application areas, such as natural language processing (NLP) and speech recognition.
At the end of this step you should have selected your neural network architecture and decided whether transfer learning can be used (and how) to solve the problem at hand.
6. Train and fine-tune your model
This is one of the most critical and time-consuming steps in the entire workflow. It consists of training your model and fine-tuning it to achieve a desired level of performance in the validation set. It includes a number of highly technical decisions, such as choice of: optimizer and its hyperparameters (batch size, learning rate), cost function, number of epochs, and regularization strategies to prevent overfitting, to name just a few. These are rather involved topics, about which many deep learning courses, tutorials, scientific papers, and entire books have been written.
At the end of this step you should have a trained model whose performance on the validation set suggests that it solves the original problem satisfying an agreed-upon metric of success.
7. Test and deploy your model
Once you're confident (based on the performance evaluation on the validation set) that you have a model that meets the expectations and requirements set forth in step 1, it is time to bring up the test set and evaluate the model's performance on the test set, which will provide a measure of the model's ability to generalize to previously unseen data.
At the end of this step you should have a model whose performance on the test set satisfies an agreed-upon metric of success and is ready for deployment.
Document and present your solution
This is the time to document everything you have done and present it to the same constituencies in step 1, explaining why your solution achieves the business objective established then. You should highlight the big picture first, abstract complex low-level details, use compelling visuals, and indicate the strengths and limitations of your approach.
At the end of this step you should have produced a high-level, visually attractive, technically rich (and yet not intimidating) presentation that should serve as a reference for decision makers who will eventually greenlight your solution.
Maintain the system
Once approved, your model is now ready for production. At this stage you will be involved with many engineering and system integration tasks. Your primary concerns will include: scalability, systematic testing/monitoring of the model's behavior, and periodic retraining of the model using fresh data. If you're working on a research lab, this step may be optional. For industry projects, it is not only required, but significantly more involved and time-consuming than it might appear at a first glance [3] [4].
Choosing a language/platform/framework
In my research work and in the courses that I teach in the fields of data science (DS), machine learning (ML), and deep learning (DL), I have extensively used three ecosystems:
- MATLAB, with Statistics and Machine Learning Toolbox and Deep Learning Toolbox (among others).
- R, with selected DS and ML packages, and the Keras interface for DL [5].
- Python, with the popular numpy, scikit-learn, pandas, matplotlib, seaborn, and scipy packages for ML/DS as well as popular DL frameworks such as TensorFlow, Keras, and PyTorch.
All of them allow for interactive and iterative explorations that are crucial when creating, fine-tuning, evaluating, and deploying machine learning and deep learning solutions. They also support inline documentation, which helps promote best practices and improve readability of the code, understanding of the solution, and reproducibility of results. This can be accomplished using, respectively: (1) MATLAB Live Editor, (2) RStudio, and (3) iPython and Jupyter notebooks.
Concluding remarks
Developing a deep learning project can be overwhelming at first. I hope that the proposed workflow and the discussions around it have given you a better understanding of the process.
To summarize, this blog post has shown how to structure deep learning projects in a way that follows a step-by-step procedure and is consistent with the best practices in the field. The references below provide links to materials to learn more details.
References
- Aurélien Géron. “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow. 2nd ed.”, O'Reilly, 2019.
- A. Ng, "Machine Learning Yearning" https://www.deeplearning.ai/machine-learning-yearning/
- The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction. https://research.google/pubs/pub46555/
- Production ML systems. https://developers.google.com/machine-learning/crash-course/production-ml-systems
- F. Chollet with J. J. Allaire. "Deep Learning with R", Manning, 2018.
- Hans Rosling et al., Factfulness: Ten Reasons We’re Wrong about the World—And Why Things Are Better Than You Think (New York: Flatiron Books, 2018).
- Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
About the Author
Oge Marques is a Professor of Computer Science and Engineering in the College of Engineering and Computer Science and, by courtesy, a Professor of Information Technology in the College of Business at Florida Atlantic University (FAU) (Boca Raton, FL). He received his PhD in Computer Engineering from FAU in 2001 and a Master’s in Electronic Engineering from Philips International Institute (the Netherlands). His work is in the area of intelligent processing of visual information, which encompasses the fields of image processing, computer vision, human vision, artificial intelligence (AI) and machine learning. His current research focuses on applying AI to healthcare, particularly radiology. He is the author of ten technical books, one patent, and more than a hundred scientific articles in his fields of expertise. He has more than 30 years of teaching experience in different countries (USA, Austria, Brazil, Netherlands, Spain, France, and India). He is a Senior Member of both the IEEE (Institute of Electrical and Electronics Engineers) and the ACM (Association for Computing Machinery). He is also a Tau Beta Pi Eminent Engineer and a member of the honor societies of Sigma Xi, Phi Kappa Phi and Upsilon Pi Epsilon. Dr. Marques is Sigma Xi Distinguished Lecturer and Fellow of the Leshner Leadership Institute of the American Association for the Advancement of Science (AAAS).