Doing the impossible? Machine learning with less than one example
Machine learning algorithms are notoriously known for needing data, a lot of data -- the more data the better. But, much research has gone into developing new methods that need fewer examples to train a model, such as "few-shot" or "one-shot" learning that require only a handful or a few as one example for effective learning. Now, this lower boundary on training examples is being taken to the next extreme.

“Less-than-one-shot learning” enables machine learning algorithms to classify N labels with less than N training examples.
If I told you to imagine something between a horse and a bird—say, a flying horse—would you need to see a concrete example? Such a creature does not exist, but nothing prevents us from using our imagination to create one: the Pegasus.

The human mind has all kinds of mechanisms to create new concepts by combining abstract and concrete knowledge it has of the real world. We can imagine existing things that we might have never seen (a horse with a long neck—a giraffe), as well as things that do not exist in real life (a winged serpent that breathes fire—a dragon). This cognitive flexibility allows us to learn new things with few and sometimes no new examples.
In contrast, machine learning and deep learning, the current leading fields of artificial intelligence, are known to require many examples to learn new tasks, even when they are related to things they already know.
Overcoming this challenge has led to a host of research work and innovation in machine learning. And although we are still far from creating artificial intelligence that can replicate the brain’s capacity for understanding, the progress in the field is remarkable.
For instance, transfer learning is a technique that enables developers to finetune an artificial neural network for a new task without the need for many training examples. Few-shot and one-shot learning enable a machine learning model trained on one task to perform a related task with a single or very few new examples. For instance, if you have an image classifier trained to detect volleyballs and soccer balls, you can use one-shot learning to add basketball to the list of classes it can detect.
A new technique dubbed “less-than-one-shot learning” (or LO-shot learning), recently developed by AI scientists at the University of Waterloo, takes one-shot learning to the next level. The idea behind LO-shot learning is that to train a machine learning model to detect M classes, you need less than one sample per class. The technique, introduced in a paper published in the arXiv preprocessor, by Ilia Sucholutsky and Matthias Schonlau, is still in its early stages but shows promise and can be useful in various scenarios where there is not enough data or too many classes.
The k-NN classifier

The k-NN machine learning algorithm classifies data by finding the closest instances.
The LO-shot learning technique proposed by the researchers applies to the “k-nearest neighbors” machine learning algorithm. K-NN can be used for both classification (determining the category of an input) or regression (predicting the outcome of an input) tasks. But for the sake of this discussion, we’ll stick to classification.
As the name implies, k-NN classifies input data by comparing it to its k nearest neighbors (k is an adjustable parameter). Say you want to create a k-NN machine learning model that classifies handwritten digits. First, you provide it with a set of labeled images of digits. Then, when you provide the model with a new, unlabeled image, it will determine its class by looking at its nearest neighbors.
For instance, if you set k to 5, the machine learning model will find the five most similar digit photos for each new input. If, say, three of them belong to the class “7,” then it will classify the image as the digit seven.
k-NN is an “instance-based” machine learning algorithm. As you provide it with more labeled examples of each class, its accuracy improves, but its performance degrades because each new sample adds new comparisons operations.
In their LO-shot learning paper, the researchers showed that you could achieve accurate results with k-NN while providing fewer examples than classes. “We propose ‘less than one’-shot learning (LO-shot learning), a setting where a model must learn N new classes given only M < N examples, less than one example per class,” the AI researchers write. “At first glance, this appears to be an impossible task, but we both theoretically and empirically demonstrate feasibility.”
Machine learning with less than one example per class
The classic k-NN algorithm provides “hard labels,” which means for every input, it provides exactly one class to which it belongs. Soft labels, on the other hand, provide the probability that an input belongs to each of the output classes (e.g., there’s a 20% chance it’s a “2”, 70% chance it’s a “5,” and a 10% chance it’s a “3”).
In their work, the AI researchers at the University of Waterloo explored whether they could use soft labels to generalize the capabilities of the k-NN algorithm. The proposition of LO-shot learning is that soft label prototypes should allow the machine learning model to classify N classes with less than N labeled instances.
The technique builds on previous work the researchers had done on soft labels and data distillation. “Dataset distillation is a process for producing small synthetic datasets that train models to the same accuracy as training them on the full training set,” Ilia Sucholutsky, co-author of the paper, told TechTalks. “Before soft labels, dataset distillation was able to represent datasets like MNIST using as few as one example per class. I realized that adding soft labels meant I could actually represent MNIST using less than one example per class.”
MNIST is a database of images of handwritten digits often used in training and testing machine learning models. Sucholutsky and his colleague Matthias Schonlau managed to achieve above-90 percent accuracy on MNIST with just five synthetic examples on the convolutional neural network LeNet.
“That result really surprised me, and it’s what got me thinking more broadly about this LO-shot learning setting,” Sucholutsky said.
Basically, LO-shot uses soft labels to create new classes by partitioning the space between existing classes.

LO-shot learning uses soft labels to partition the space between existing classes.
In the example above, there are two instances to tune the machine learning model (shown with black dots). A classic k-NN algorithm would split the space between the two dots between the two classes. But the “soft-label prototype k-NN” (SLaPkNN) algorithm, as the OL-shot learning model is called, creates a new space between the two classes (the green area), which represents a new label (think horse with wings). Here we have achieved N classes with N-1 samples.
In the paper, the researchers show that LO-shot learning can be scaled up to detect 3N-2 classes using N labels and even beyond.
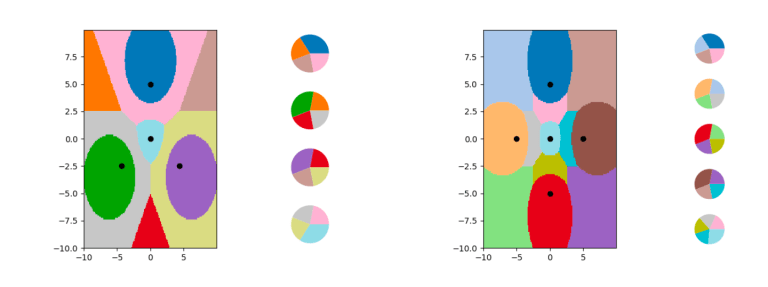
LO-shot learning can be extended to obtain multiple classes per instance. Left: 10 classes obtained from four instances. Right: 13 classes obtained from five instances.
In their experiments, Sucholutsky and Schonlau found that with the right configurations for the soft labels, LO-shot machine learning can provide reliable results even when you have noisy data.
“I think LO-shot learning can be made to work from other sources of information as well—similar to how many zero-shot learning methods do—but soft labels are the most straightforward approach,” Sucholutsky said, adding that there are already several methods that can find the right soft labels for LO-shot machine learning.
While the paper displays the power of LO-shot learning with the k-NN classifier, Sucholutsky says the technique applies to other machine learning algorithms as well. “The analysis in the paper focuses specifically on k-NN just because it’s easier to analyze, but it should work for any classification model that can make use of soft labels,” Sucholutsky said. The researchers will soon release a more comprehensive paper that shows the application of LO-shot learning to deep learning models.
New venues for machine learning research

“For instance-based algorithms like k-NN, the efficiency improvement of LO-shot learning is quite large, especially for datasets with a large number of classes,” Susholutsky said. “More broadly, LO-shot learning is useful in any kind of setting where a classification algorithm is applied to a dataset with a large number of classes, especially if there are few, or no, examples available for some classes. Basically, most settings where zero-shot learning or few-shot learning are useful, LO-shot learning can also be useful.”
For instance, a computer vision system that must identify thousands of objects from images and video frames can benefit from this machine learning technique, especially if there are no examples available for some of the objects. Another application would be to tasks that naturally have soft-label information, like natural language processing systems that perform sentiment analysis (e.g., a sentence can be both sad and angry simultaneously).
In their paper, the researchers describe “less than one”-shot learning as “a viable new direction in machine learning research.”
“We believe that creating a soft-label prototype generation algorithm that specifically optimizes prototypes for LO-shot learning is an important next step in exploring this area,” they write.
“Soft labels have been explored in several settings before. What’s new here is the extreme setting in which we explore them,” Susholutsky said. “I think it just wasn’t a directly obvious idea that there is another regime hiding between one-shot and zero-shot learning.”
Original. Reposted with permission.
Related: