Predicting Heart Disease Using Machine Learning? Don’t!
I believe the “Predicting Heart Disease using Machine Learning” is a classic example of how not to apply machine learning to a problem, especially where a lot of domain experience is required.
By Venkat Raman, Data Scientist at True Influence
I was recently invited to judge a Data Science competition. The students were given the 'heart disease prediction' dataset, perhaps an improvised version of the one available on Kaggle. I had seen this dataset before and often come across various self-proclaimed data science gurus teaching naïve people how to predict heart disease through machine learning.
I believe the “Predicting Heart Disease using Machine Learning” is a classic example of how not to apply machine learning to a problem, especially where a lot of domain experience is required.
Let me unpack the various problems in applying machine learning to this data set.
Dive straight into the problem syndrome – Well this is the first mistake many people make. Jumping straight into the problem and thinking which Machine learning algorithm to apply. Doing EDA et all as part of this process is not *thinking* about the problem. Rather it is a sign that you have already accepted the notion that the problem needs a data science solution. Instead one of the pertinent questions that needs to be asked before starting any analysis is, “Is this problem even predictable through application of machine learning?”.
Blind faith in Data – This is an extension of the first point. Diving straight into the problem means you have blind faith in the data. People assume the data to be true and do not make an effort to scrutinize the data. For example, the dataset only provided systolic blood pressure. If you spoke to any doctor or even a paramedic, they would tell you that systolic blood pressure alone does not give the full picture. Reporting of diastolic level is important too. Many don't even ask the question "are the features enough to predict the outcome or more features are needed".
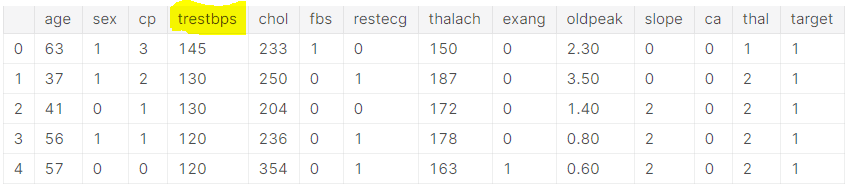
Not enough data per patient: Let’s take a look at the data set above. If you notice, there is only one data point under each feature for a patient. The fundamental problem here is that features like blood pressure, cholesterol, heart beat are not static. They range. Blood pressure of a person varies hour to hour and on a daily basis, so does heat beat. So when it comes to prediction problem there is no telling weather 135 mm hg blood pressure was one of the factors to cause the heart disease or was it 140, all while the data set might be reporting 130 mm hg. Ideally, multiple measurements need to be had for each feature for a patient.
Now let’s come to the crux of the matter
Applying algorithm without domain experience - One of the reasons for high failure rate of data science application in health care is that the data scientists applying the algorithm do not have adequate medical knowledge.
Secondly, in healthcare, causality is taken very seriously. Many rigorous clinical and statistical tests are conducted to infer causality.
In the case study, any machine learning algorithm is just trying to map the input to the output while reducing some error metric. Also, the machine learning algorithm by themselves are not classifiers, we make them as classifiers by setting some cut-off or threshold. Again, this cut off is not decided to deduce causality but just to get "favorable metrics".
Aggravating this problem is the usage of low code libraries. This case study is a case in point example why low code libraries can be dangerous. Low code libraries fit a dozen or more algorithms. Most are not even aware how some of these algorithms work! They just pick the 'best' algorithm based on metrics like F1, Precision, Recall and Accuracy.
The low code libraries that fixate on accuracy metrics lead to 'Goodhart's law' -"When a measure becomes a target, it ceases to be a good measure."

If you are predicting, you are implying a causation. In healthcare, mere prediction is not enough, one needs to prove causation. Machine learning classifier algorithms do not answer the ‘causation’ part.
Believing they have solved a real healthcare problem – Last but not the least, many believe that by fitting a ML algorithm to a *healthcare* data set and getting some accuracy metrics, they have solved a real healthcare problem. Nothing can be further from truth than this, especially when it pertains to healthcare domain.
In conclusion:
There are perhaps thousands of business problems that genuinely warrant data science / machine learning solutions. But at the same time, one should not fall into the trap of “To a person with hammer, everything looks like a nail”. Seeing everything as a nail (data science problem) and machine learning algorithms as (hammer) can be very counterproductive. Much of 80% failure rate in data science application to business problem could be attributed to this.
Good data scientists are like Good doctors. Good doctors suggest conservative treatments first before prescribing heavy dosage medicines or surgery. Similarly, a good data scientist should ask certain pertinent questions first before blindly applying a dozen ML algorithms to the problem.
Doctor: Surgery :: Data Scientist : Machine learning
Your comments and opinions are welcome.
Bio: Venkat Raman is a Data Scientist with business acumen. He helps businesses thrive through data science. He has a proven track record of innovating and applying Data Science techniques to business problems. He is a perpetual knowledge seeker and believes in giving best effort for any task.
Original. Reposted with permission.
Related:
- How AI will transform healthcare (and can it fix the US healthcare system?)
- Artificial Intelligence for Precision Medicine and Better Healthcare
- AI in Healthcare: A review of innovative startups