 Why the Future of ETL Is Not ELT, But EL(T)
Why the Future of ETL Is Not ELT, But EL(T)
 Why the Future of ETL Is Not ELT, But EL(T)
Why the Future of ETL Is Not ELT, But EL(T)The well-established technologies and tools around ETL (Extract, Transform, Load) are undergoing a potential paradigm shift with new approaches to data storage and expanding cloud-based compute. Decoupling the EL from T could reconcile analytics and operational data management use cases, in a new landscape where data warehouses and data lakes are merging.
By John Lafleur, Co-Founder, Airbyte.io.

How we store and manage data has completely changed over the last decade. We moved from an ETL world to an ELT world, with companies like Fivetran pushing the trend. However, we don’t think it is going to stop there; ELT is a transition in our mind towards EL(T) (with EL decoupled from T). And to understand this, we need to discern the underlying reasons for this trend, as they might show what’s in store for the future.
This is what we will be doing in this article. I’m the co-founder of Airbyte, the new upcoming open-source standard for data integrations.
What are the problems with ETL?
Historically, the data pipeline process consisted of extracting, transforming, and loading data into a warehouse or a data lake. There are serious disadvantages to this sequence.
Inflexibility
ETL is inherently rigid. It forces data analysts to know beforehand every way they are going to use the data, every report they are going to produce. Any change they make can be costly. It can potentially affect data consumers downstream of the initial extraction.
Lack of visibility
Every transformation performed on the data obscures some of the underlying information. Analysts won’t see all the data in the warehouse, only the one that was kept during the transformation phase. This is risky, as conclusions might be drawn based on data that hasn’t been properly sliced.
Lack of Autonomy for Analysts
Last but not least, building an ETL-based data pipeline is often beyond the technical capabilities of analysts. It typically requires the close involvement of engineering talent, along with additional code to extract and transform each source of data.
The alternative to a complex engineering project is to conduct analyses and build reports on an ad hoc, time-intensive, and ultimately unsustainable basis.
What changed and why ELT is way better
Cloud-based Computation and Storage of Data
The ETL approach was once necessary because of the high costs of on-premises computation and storage. With the rapid growth of cloud-based data warehouses such as Snowflake and the plummeting cost of cloud-based computation and storage, there is little reason to continue doing transformation before loading at the final destination. Indeed, flipping the two enables analysts to do a better job in an autonomous way.
ELT Supports Agile Decision-making for Analysts
When analysts can load data before transforming it, they don’t have to determine beforehand exactly what insights they want to generate before deciding on the exact schema they need to get.
Instead, the underlying source data is directly replicated to a data warehouse, comprising a “single source of truth.” Analysts can then perform transformations on the data as needed. Analysts will always be able to go back to the original data and won’t suffer from transformations that might have compromised the integrity of the data, giving them a free hand. This makes the business intelligence process incomparably more flexible and safe.
ELT Promotes Data Literacy Across the Whole Company
When used in combination with cloud-based business intelligence tools such as Looker, Mode, and Tableau, the ELT approach also broadens access to a common set of analytics across organizations. Business intelligence dashboards become accessible even to relatively non-technical users.
We’re big fans of ELT at Airbyte, too. But ELT is not completely solving the data integration problem and has problems of its own. We think EL needs to be completely decoupled from T.
What’s changing now and why EL(T) is the future
Merging of Data Lakes and Warehouses
There was a great analysis by Andreessen Horowitz about how data infrastructures are evolving. Here is the architecture diagram of the modern data infrastructure they came up with after a lot of interviews with industry leaders.
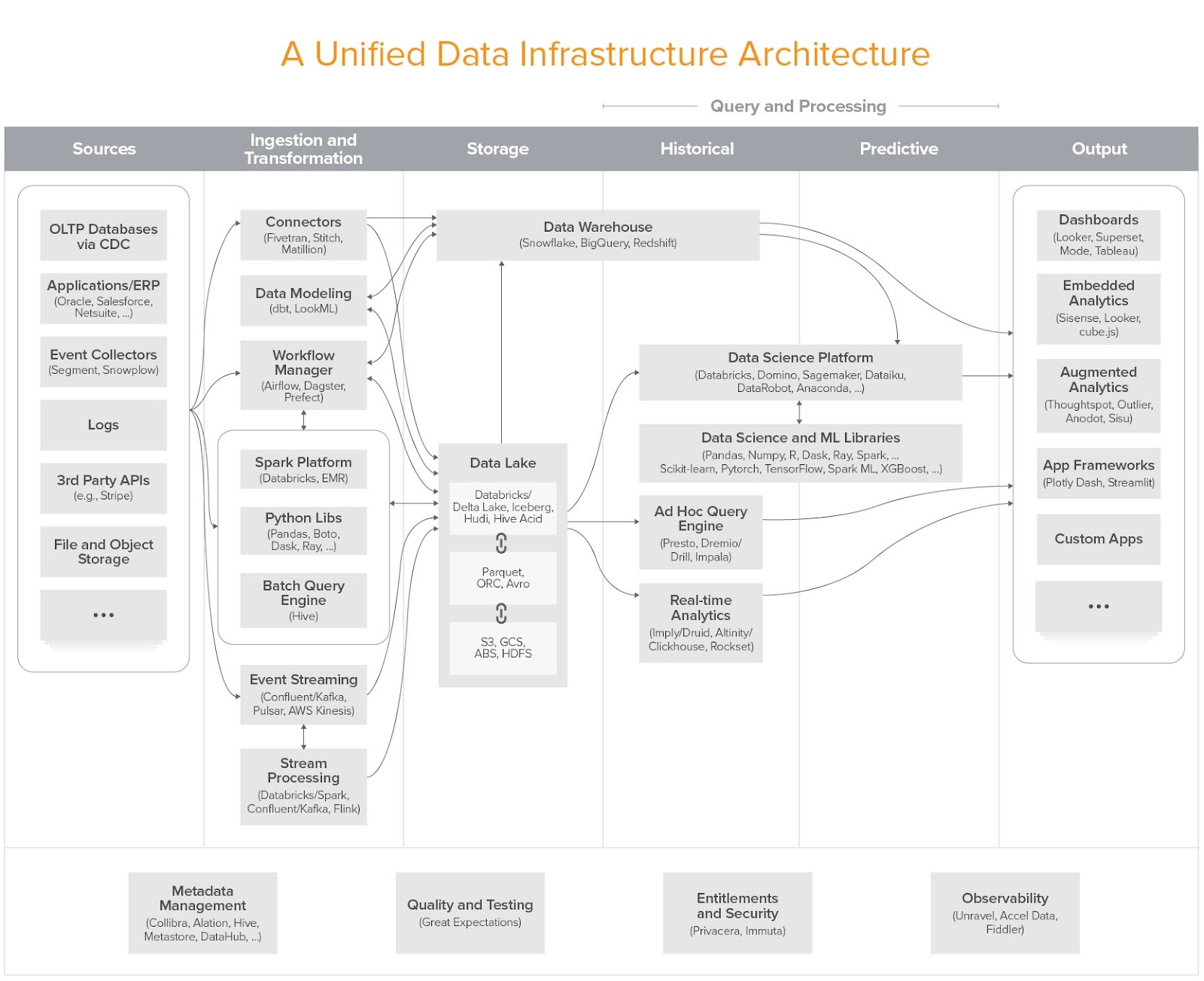
Data infrastructure serves two purposes at a high level:
- Helps business leaders make better decisions through the use of data - analytic use cases
- Builds data intelligence into customer-facing applications, including via machine learning - operational use cases
Two parallel ecosystems have grown up around these broad use cases.
The data warehouse forms the foundation of the analytics ecosystem. Most warehouses store data in a structured format. They are designed to generate insights from core business metrics, usually with SQL (although Python is growing in popularity).
The data lake is the backbone of the operational ecosystem. By storing data in raw form, it delivers the flexibility, scale, and performance required for applications and more advanced data processing needs. Data lakes operate on a wide range of languages, including Java/Scala, Python, R, and SQL.
What’s really interesting is that modern data warehouses and data lakes are starting to resemble one another – both offering commodity storage, native horizontal scaling, semi-structured data types, ACID transactions, interactive SQL queries, and so on.
So you might be wondering if data warehouses and data lakes are on a path toward convergence. Will they become interchangeable in a stack? Will data warehouses also be used for the operational use case?
EL(T) Supports Both Use Cases: Analytics and Operational ML
EL, in contrast to ELT, completely decouples the Extract-Load part from any optional transformation that may occur.
The operational use cases are all unique in the way incoming data is leveraged. Some might use a unique transformation process; some might not even use any transformation.
In regards to the analytics case, analysts will need to get the incoming data normalized for their own needs at some point. But decoupling EL from T would let them choose whichever normalization tool they want. DBT has been gaining a lot of traction lately among data engineering and data science teams. It has become the open-source standard for transformation. Even Fivetran integrates with them to let teams use DBT if they’re used to it.
EL Scales Faster and Leverages the Whole Ecosystem
Transformation is where all the edge cases lie. For every specific need within any company, there is a schema normalization unique to it, for each and every one of the tools.
Decoupling EL from the T enables the industry to start covering the long tail of connectors. At Airbyte, we’re building a “connector manufacturing plant” so we can get to 1,000 pre-built connectors in a matter of months.
Furthermore, as mentioned above, it would help teams leverage the whole ecosystem in an easier way. You start to see an open-source standard for every need. In a sense, the future data architecture might look like this:

In the end, extract and load will be decoupled from transformation. Do you agree with us?
Original. Reposted with permission.
Bio: John Lafleur is a co-founder of Airbyte, the new open-source standard for data integrations. I’m also an author at SDTimes, Linux.com, TheNewStack, Dzone… and a happy husband and dad :)
Related: