
In Stephen Covey’s masterful 7 Habits of Highly Effective People, the seventh habit is “sharpen the saw.” This refers to enhancing our assets to seek continuous improvement in our work. As Abe Lincoln said,
Give me eight hours to chop down a tree, and I will spend the first six sharpening the saw.
Better tools to structure, simplify, and broaden our Data Science work will make us more effective thinkers, decisionmakers, and practitioners.
In this article, we’ll explore how to sharpen our Data Science saws — and also investigate the unanswered question of who is handing out saws to so many motivational speakers.
Here are five tools for the practice of effortless Data Science.
#1 — Cookiecutter
Usecase: structure the repository of your Data Science project with this pre-built file structure setup.
Data scientists should be organized in order to gather insights through repeatable projects. Cookiecutter by DrivenData helps us share and execute Data Science tasks with an organized repository structure. To get started, simply run cookiecutter https://github.com/drivendata/cookiecutter-data-science from the command line. This creates the Cookiecutter file structure.
Beginners benefit from the expertise of the DrivenData team in building best practices into this repo structure. Experts can use this template as a flexible jump-start to their projects.

Ultimately, Cookiecutter promotes logical standardization. That makes it easy for you, your collaborators, and project stakeholders to find data, notebooks, reports, visualizations, etc. Cookiecutter promotes reproducibility and code quality. Setting up your Data Science experiment with Cookiecutter is fast and supremely useful.
Two additional tools referenced in the directory structure:
- Sphinx — documentation generator that will translate a set of plain text source files into various output formats, automatically generating cross-references
- Tox — virtualenv management and test command line tool to ensure that packages will install correctly with different Python versions and interpreters; it can also act as a frontend to Continuous Integration servers
How to use: start your next project with cookiecutter https://github.com/drivendata/cookiecutter-data-science.
#2 — Deon
Usecase: address ethical considerations of your Data Science project and document your findings.
Checklists are a proven way to limit blindspots and reduce errors. As an ethics checklist for responsible Data Science, Deon represents a promising starting point for any project. Teams should use this tool to evaluate considerations ranging from data collection through machine learning model deployment.
Running deon -o ETHICS.md from the root of your project file structure will generate a markdown file where you can document your review of the ethical considerations of your model.
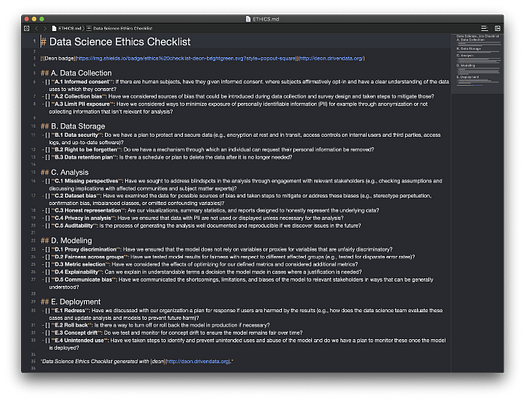
The nuanced discussions spurred by Deon can ensure that risks inherent to machine learning technology do not adversely impact the subjects of the model or the reputation of the organization. Read more:
3 Open Source Tools for Ethical AI
Before integrating artificial intelligence into your organization’s workflow, consider these tools to prevent machine…
How to use: add the checklist markdown file to your root folder by running deon -o ETHICS.md, then schedule conversations with your stakeholders to fill out the checklist.
#3 — PyCaret
Usecase: in just a few lines of code, exponentiate your potential with the PyCaret library for simplified Data Science.
Pycaret is great for beginners or seasoned coders looking to increase their efficiency. This library helps you implement the typical steps of a Data Science workflow in fewer lines of code.
How to use: leverage PyCaret’s functionality for preprocessing and modeling — e.g.
from pycaret.regression import *
exp_name = setup(data = boston, target = 'medv', train_size = 0.7)
#4 — ktrain
Usecase: a low-code wrapper for Keras that enshines machine learning best practices into the hyperparameter and model training pipeline.
Arun Maiya, a machine learning researcher and data science team lead, has compiled the recent advancements from arXiv into functions that can be effortlessly deployed across computer vision, natural language processing, and graph-based approaches.
How to use: simplify the training, inspection, and application of state-of-the-art machine learning models — e.g.
model = txt.text_classifier ('bert', trn , preproc = preproc)
#5 — MLFlow
Usecase: move your experiment tracking from manual Excel logs to this automated platform.
ML Flow enables the automatic tracking of parameters, code versions, metrics, and output files. The MlflowClient function creates and manages experiments, pipeline runs, and model versions. Log artifacts (e.g. datasets), metrics, and hyperparameters with mlflow.log_artifact, .log_metric() and .log_param().
You can easily view all metadata and results across experiments in a local host browser with the mlflow uicommand.
How to use: set up MLFlow with…
if __name__ == "__main__":
# Log a parameter (key-value pair)
log_param("param1", randint(0, 100))…then run existing projects with the mlflow run command, which runs a project from either a local directory or a GitHub URL.
Summary
Okay, I may have prevaricated slightly about Abe Lincoln’s pithy lumberjack quote, but I hope you still enjoyed the article. Having the right tool does make the task so much easier. Hopefully, you’re now well-equipped with some new means to connect data to strategic outcomes.
If you enjoyed this writeup, follow me on Medium, LinkedIn, YouTube, and Twitter for more ideas to improve your Data Science skills.
More resources
10 Underrated Python Skills
Up your Data Science game with these tips for improving your Python coding for better EDA, target analysis, feature…
5 Must-Read Data Science Papers (and How to Use Them)
Foundational ideas to keep you on top of the data science game.
10 Python Skills They Don’t Teach in Bootcamp
Ascend to new heights in Data Science and Machine Learning with this list of coding tips.
How to Future-Proof Your Data Science Project
5 critical elements of ML model selection & deployment
10 Python Skills for Beginners
Python is the fastest growing, most-beloved programming language. Get started with these Data Science tips.
Bio: Nicole Janeway Bills is Data Scientist with experience in commercial and federal consulting. She helps organizations leverage their top asset: a simple and robust Data Strategy. Sign up for more of her writing.
Original. Reposted with permission.
Related:
- Command Line Basics Every Data Scientist Should Know
- 10 Underrated Python Skills
- What I learned from looking at 200 machine learning tools