Popular Machine Learning Interview Questions, part 2
Get ready for your next job interview requiring domain knowledge in machine learning with answers to these thirteen common questions.
By Mo Daoud, Works in technology, AI enthusiast.
This article is part 2 of my Popular Machine Learning Interview questions.
Here I feature more questions I usually see asked during interviews. I shall note that this isn’t an interview prep guide nor a conclusive list of all questions. Rather, you should use this article as a refresher for your Machine Learning knowledge. I suggest reading the question then try to answer it yourself before reading the answer. This way, you will validate your knowledge and learn where are your skill gaps. Let’s get started.

Photo by Gabrielle Henderson on Unsplash.
Q1. What’s the difference between ANN, CNN, and RNN?
ANN stands for Artificial Neural Networks , which is the basis of deep learning. In ANN, we have layers, neurons, activation functions, weights, and backpropagation. You should be familiar with all these terms. If not, then read Neurons, Activation Functions, Back-Propagation, Epoch, Gradient Descent: What are these?
I usually find good candidates drawing during interviews to illustrate their ideas and confirm their knowledge. Drawing the below diagram will help you further explain ANN and how it learns.
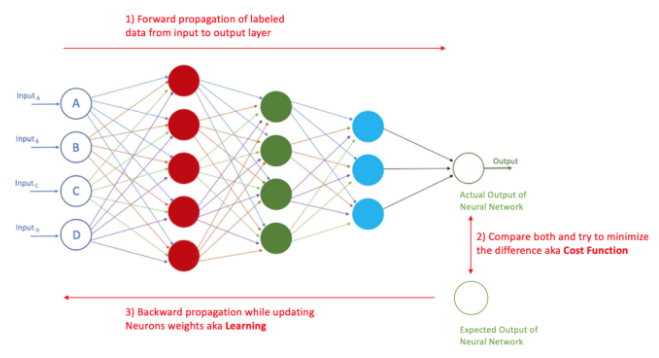
Artificial Neural Network: Learning Steps. Image by Author.
CNN is a Convolution Neural Network with its main application in computer vision and video analytics in general. CNN deals with the issue of how to enter an image in an ANN, how to capture the important features of an image and convert it into a format that can be fed in the neural network.
CNN takes an image and passes it through the below steps
1 - Convolution
The image is converted into 0’s and 1’s and then multiplied by a feature detector to produce a feature map. The main reason for this step is to reduce the size of the input image. Some information might get lost, but the main features of the image will get captured. Usually, the image is multiplied by multiple feature detectors to produce multiple feature maps. These feature maps go through a function, usually, ReLU, to ensure non-linearity in the image.
2 - Pooling
There are several pooling operations, but the most common is max pooling. It teaches the network spatial variance. In simple words, the ability to recognize the image features even if the image is upside down, tilted, or the image is taken from far or close, etc. The output of this operation is a pooled feature map.
3 - Flattening
The purpose of this operation is to be able to input the pooled feature map into the neural network.
The below image shows the entire CNN operation.
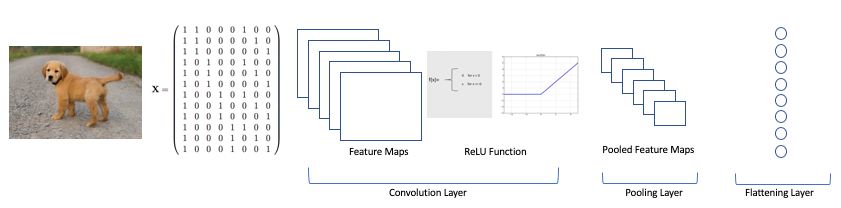
Convolution Neural Network. Image by Author.
As you can see, the flattened output of the CNN has the image features and is in a format that can be input to the ANN.
RNN is Recurrent Neural Networks that is mainly used for time series problems like stock market forecasting. They are famous for LSTM (Long Short-Term Memory). Similar to ANN, there are input and output layers along with multiple layers of neurons in between, but the main difference is that RNN neurons have a sort of short-term memory. This short-term memory provides the neurons with the possibility to remember what was in this neuron previously. This is the reason RNN is good for time series problems and translation since the network will need to know the previous translated word in order to create a coherent sentence rather than just translate each word on its own.
This question is one of my all-time favorites because it shows a general overview understanding of the main concept of neural networks.
Q2. What’s the difference between AI, ML, and DL?
This is a simple one, yet many people get it wrong. The main thing to know is that AI is the general term, then give some examples.
Artificial Intelligence is the science of making computers behave like humans in terms of making decisions, text processing, translation, etc. AI is a big umbrella with Machine Learning and Deep Learning under it.
Every Machine Learning algorithm is considered AI but not every AI algorithm is considered Machine Learning.
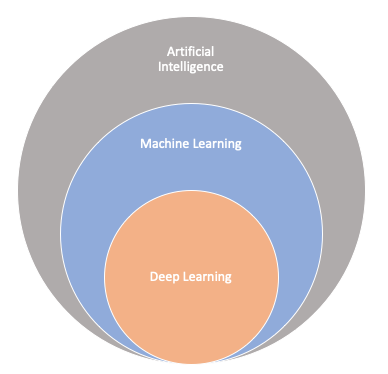
The relation between AI, ML, and DL. Image by Author.
Machine Learning: You select the model to train and manually perform feature extraction for the model to learn.
Deep Learning: You design the architecture of the Neural Network, and features are automatically extracted from the fed labeled training data.
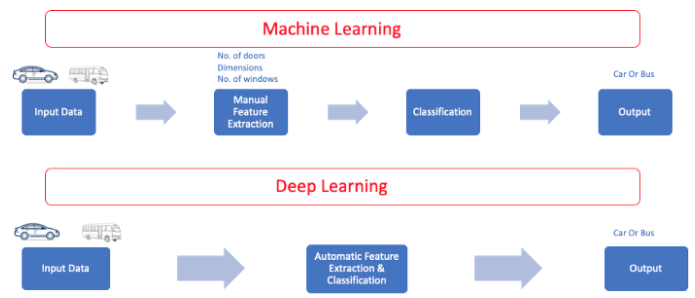
Difference between ML and DL. Image by Author.
Q3. What are factorization machine algorithms, and what are they used for?
Factorization Machines can be used for classification or regression and are much more computationally efficient on large sparse data sets than traditional algorithms like linear regression. This property is why Factorization Machines are widely used for recommendation. Factorization Machines are supervised learning algorithms, and their main use is handling spare data. However, they don’t perform dimensionality reduction. An example of Factorization Machines use is ad click prediction and item recommendation.
Q4. How can you create a model with a very unbalanced dataset? For example, working with credit card fraud data and there are very few real fraud cases while the majority of the cases are non-fraudulent.
Creating a model with an unbalanced dataset will yield bad results in terms of favoring more training data, in our case, the non-fraudulent transactions. You should never create a model with an unbalanced dataset. The answer should be around trying to gather more balanced data and, if not possible, then oversample your data using SMOTE (Synthetic Minority Over Sampling) or Random Over Sampling (ROS).
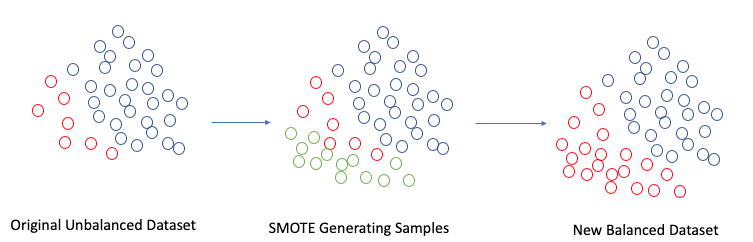
SMOTE Techniques to Balance Datasets. Image by Author.
The SMOTE technique creates new observations of the underrepresented class, in this case, the fraudulent observations. These synthetic observations are almost identical to the original fraudulent observations. This technique is expeditious, but the types of synthetic observations it produces are not as useful as the unique observations created by other oversampling techniques.
Q5. What’s regularization, and what’s the difference between L1 and L2 regularization?
Regularization in machine learning is the process of regularizing the parameters that constrain, regularizes, or shrinks the coefficient estimates towards zero. In other words, this technique discourages learning of a more complex or flexible model, avoiding the risk of overfitting. Regularization basically adds the penalty as model complexity increases, which can help avoid overfitting.
L1 effectively removes features that are unimportant, and doing this too aggressively can lead to underfitting. L2 weighs each feature instead of removing them entirely, which can lead to better accuracy. Briefly, L1 removes features while L2 doesn’t, and L2 regulates their weights instead.
Q6. What’s transfer learning? How it’s useful?
Transfer Learning allows you to start with an existing trained model, usually off the shelf from a source like GitHub. You take the existing trained model and apply it to your different but closely aligned observations. This saves you time deploying and operationalizing your machine learning solution since you are starting from a pre-trained model.
In Transfer Learning, the network is initialized with pre-trained weights, and just the top fully connected layer is initialized with random weights. Then, the whole network is fine-tuned with new data. In this mode, training can be achieved even with a smaller dataset. This is because the network is already trained and therefore, can be used in cases without sufficient training data.
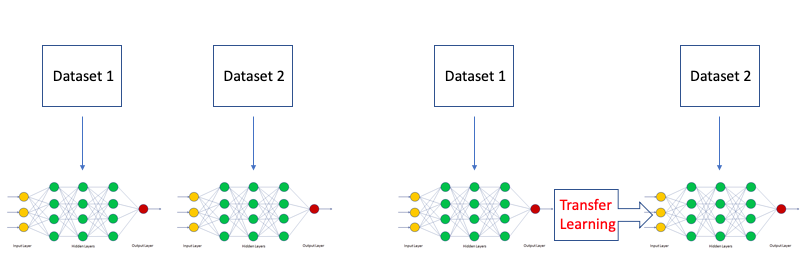
Full Learning vs. Transfer Learning. Image by Author.
Q7. What’s the LDA algorithm? Give an example.
LDA (Latent Dirichlet Allocation) algorithm is an unsupervised learning algorithm that attempts to describe a set of observations as a mixture of distinct categories. LDA is most commonly used to discover a user-specified number of topics shared by documents within a text corpus, i.e., topic modeling.
Q8. What’s the difference between Linear Regression and Logistic Regression?
Linear Regression is used to predict a continuous variable and is mainly used to solve regression problems. Linear regression finds the best fit line by which the numerical output value can be predicted.
Logistic Regression is used to predict categorical values and is mainly used in classification problems. Logistic regression produces an S curve that classifies, and the output is binary or categories.
Q9. What’s Bag of Words used for?
Bag-of-Words is an NLP (Natural Language Processing) algorithm that creates tokens of the input document text and outputs a statistical depiction of the text. The statistical depiction, such as a histogram, shows the count of each word in the document.
Q10. How can you identify a high bias model? How can you fix it?
A High Bias model is due to a simple model and can be easily identified when you see:
- High training error
- Validation error or test error is the same as training error
To fix a High Bias model, you can:
- Add more input features
- Add more complexity by introducing polynomial features
- Decrease the regularization term
Q11. How to identify a high variance model? How do you fix it?
A High Variance model is due to a complex model and can be easily identified when you see:
- Low training error
- High validation error or high test error
To fix a high variance model, you can:
- Get more training data
- Reduce input features
- Increase the regularization term
Q12. What are some common tools to evaluate regression models?
The first thing that comes to my mind when I hear regression model evaluation is RMSE (Root Mean Square Error) because it’s the most simple and common metric for regression evaluation. RMSE can easily tell if the model is overestimating or underestimating.
RMSE is the gap between the predicted numerical target and the true numerical answer (i.e., true numerical value). The smaller the value of RMSE, the better the prediction accuracy of the model. If the model’s prediction is correct, its RMSE will be 0.
Q13. What’s ROC and AUC? What are they used for?
A ROC (Receiver Operating Characteristic) curve, or ROC curve, is a graphical plot that illustrates the diagnostic ability of a binary classifier system as its discrimination threshold is varied.
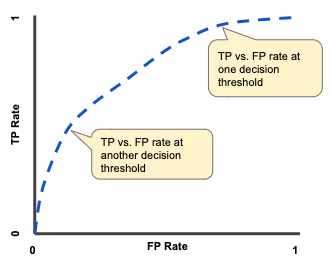
ROC Curve. Source.
This curve plots two parameters:
- True Positive Rate
- False Positive Rate
ROC curve plots True Positive Rate vs. False Positive Rate at different classification thresholds. Lowering the classification threshold classifies more items as positive, thus increasing both False Positives and True Positives.
Area Under the ROC Curve (AUC) measures the entire two-dimensional area underneath the ROC curve. AUC is used to compare/evaluate machine learning classification models against each other and measures the entire two-dimensional area underneath the entire ROC curve.

AUC. Source.
AUC provides an aggregate measure of performance across all possible classification thresholds. One way of interpreting AUC is the probability that the model ranks a random positive example more highly than a random negative example.
Good luck with any upcoming interview you may have. There are a lot of Machine Learning and AI information online, and there are many sources you can gain knowledge from. I encourage you to utilize free sources, courses, and articles like this to learn more about Machine Learning. ML and AI will affect your job no matter what line of work you’re in, so arm yourself with the required knowledge.
Original. Reposted with permission.
Related: