Backcasting: Building an Accurate Forecasting Model for Your Business
This article will shed some light on processes happening under the roof of ML-based solutions on the example of the business case where the future success directly depends on the ability to predict unknown values from the past.
By Lena Boichuk, Data Scientist at Competera
We often talk about machine learning for price management from the business point of view while leaving the technical part out. This article is quite unique. Our data science team will shed some light on processes happening under the roof of ML-based solutions on the example of the business case where the future success directly depends on the ability to predict unknown values from the past.
Introduction
Let’s imagine that you are a retailer who wants to implement machine learning algorithms for pricing. There can be many reasons for this:
- Process automation saves labor and time.
- It helps to avoid errors caused by human factors.
- Modern technologies allow you to quickly and dynamically process large amounts of data, making your decisions faster than any human can.
The benefits sound promising, but you are a smart business, so before implementing a new approach, you need to make sure it is effective compared to existing processes. The easiest way is to carry out an A/B test with a test and control group with similar goods. The first group will use a new approach and the second will use the old one. You take a test, analyze the results and see if the proposed approach is statistically better than the existing one. Everything looks like a fairly simple task in theory, but you will probably have to deal with the specifics of your business, so the running of the A/B test would be complicated.
For one of Competera's customers, Balsam Brands, the specifics are that 80% of annual sales happens during the last 3 months of the year, so conducting a traditional A/B test today means scaling the new approach to price management in the next year. In such cases, you can check the accuracy of the algorithms by so-called backcasting or “a planning method that involves the prediction of the unknown values of the independent variables that might have existed, in order to explain the known values of the dependent variable”.
Step 1: Building your predictive model
To prove the effectiveness of an ML-based solution you need two things: the model and the data to feed in it. The client provided us with:
- Transaction data
- Price lists
- Promotional calendars
- Product references
- Stocks
- Data on marketing activities
Although the Balsam brands case took place in 2020, complete historical data covered two sales seasons (2017-2018), and transactional data were presented for 2008-2018 years. Our task was to forecast sales for the 2019 season, despite the fact that the data about actual sales for this period were already known to the retailer, but wasn’t sent to us due to the backcasting requirements. In other words, our model had to make a forecast as if it was launched not in 2020, but in early 2019.
The main evaluation criteria for the Balsam Brands sales forecasting model was the accuracy of sales and revenue forecast for the aggregate test period (8 weeks of high season sales) at the category level – separately for one category (~ 30% of total assortment, ~ 75% of total revenue) and aggregated for the rest of assortment. It can be described by formula:

The percentage error was evaluated using the following calculation:
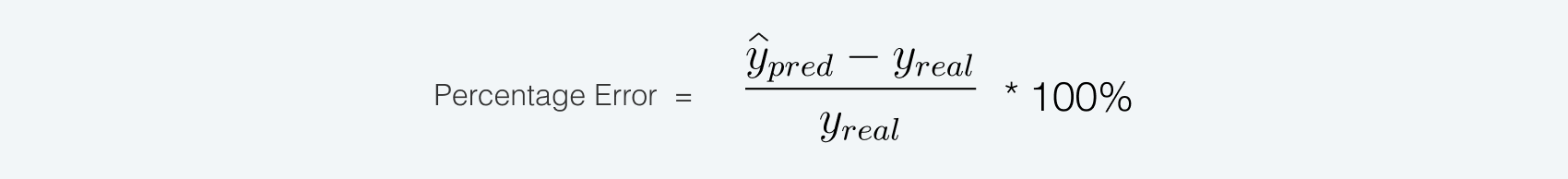
How to hit the accuracy threshold
In order to achieve high accuracy according to the given criteria, you can build a statistical autoregressive model for each of the two categories at the weekly level. After the model training, you should be able to aggregate the forecast for 8 weeks of the test period and get the final result. Moreover, historical transaction data contains observations of over 10 years, which is sufficient to study seasonality.
So, we built the SARIMA model for forecasting. After getting the real sales data, we tested the accuracy of this model and got high results: for each of the categories the APE error value on the test was < 5%. But while the results were good, this model was unsuitable for real business.
Why SARIMA is not enough
In this case, an optimal price recommendation solution was the result of successful backcasting. That is, the model should not only meet the requirements for accuracy, but also be useful for price optimization.
Type of the mentioned model does not take into account the impact of price and can make predictions only at the category level, i.e. does not allow you to estimate the change in sales at the level of individual SKUs. Of course, you can build a separate model at the level of each product, but firstly, it will be inefficient, and secondly, it will prevent a particular model from using the knowledge encapsulated in other models and cross-dependencies of the product range.
Now assume that you‘re running price optimization using the mentioned demand forecasting model. You set the price limits on +- 50% of the current product`s price and your goal is to optimize revenue. As your model can’t estimate the change in sales on SKU level it predicts unchanged sales for increased prices. To maximize revenue it will increase all product prices to the upper boundaries. Probably, you’ve already guessed the result of such optimization.
This example is not as hyperbolized as it might seem at first. Similar problems often occur even when the demand forecasting model uses price features. If they have low impact on model predictions (low feature importance), price elasticities would be close to zero and the quality of price optimization will be low.
The ideal predictive model
The model which is simultaneously accurate and suitable for business challenges, must meet a number of requirements:
- the model has to make accurate forecasts for the long term, so you can manage long-term strategies;
- the forecast must be accurate at the product level because it allows you to operate the strategy at any given level;
- the model must be able to forecast at the level of the repricing time period (for instance, 1 week);
- it should take into account the cross-product relations, e.g., problems of substitutes and complementary goods;
- it should consider the absolute and relative price characteristics (for example, the price of the product, its change over time, etc.). The more accurately your model estimates the impact of price characteristics, the more optimal price recommendations would be.
Classical approaches to time series forecasting
Apart from SARIMA, there are other autoregressive models that meet the specified requirements. For example, with (S)ARIMAX you can take into account the influence of exogenous factors (e.g., prices or promo). VARMA(X) models allow you to assess the interconnections between products. Finally, classical statistical approaches are well-founded mathematically and easy to interpret. You can read more about them here.
However, such approaches have a number of disadvantages. They are non-adaptive, so you need to regularly retrain the model. They are sensitive to the input data format (stationary condition, etc.). They are suboptimal when working with a large number of different but dependent time series (parameterization problem). They don’t work for new time series predictions (the problem of "cold start") and not optimal for forecasting over the long term (MA component fades). Also, you need to retrain the model every time a new assortment appears.
Recurrent Forecasting approach
The transition (“relaxation”) from the task of predicting time series to the construction of regression can solve these problems. The characteristics of the temporal axis (such as autocorrelation) are encoded by directly transmitting the lags of time variables to the model, while time characteristics are transmitted in the form of features.
The forecast for several periods ahead can be obtained using the Recurrent Forecasting approach. That is, the basic model forecasts for one period ahead, while to forecast for several periods recurrent previous forecasts are used.
The baseline model can be based on conventional linear regression, neural network, or regression-based gradient boosting, which is currently best suited for heterogeneous (tabular) data. More details here.
We’ve implemented several boosting frameworks, which allow users to work with skipped values, categorical variables, as well as utilize custom target functions: LightGBM, XGBoost, CatBoost. The Recurrent Forecasting approach is easy to implement, but requires dynamic recalculation of the dataset (a feature from the future) when forecasting. It is also difficult to detect implicit time dependencies.
RNN models
An alternative to the Recurrent Forecasting approach is to use RNN models. They better detect time dependencies, and also allow you to build a forecast several points ahead (seq2seq models).
The target for the forecast may be, for example:
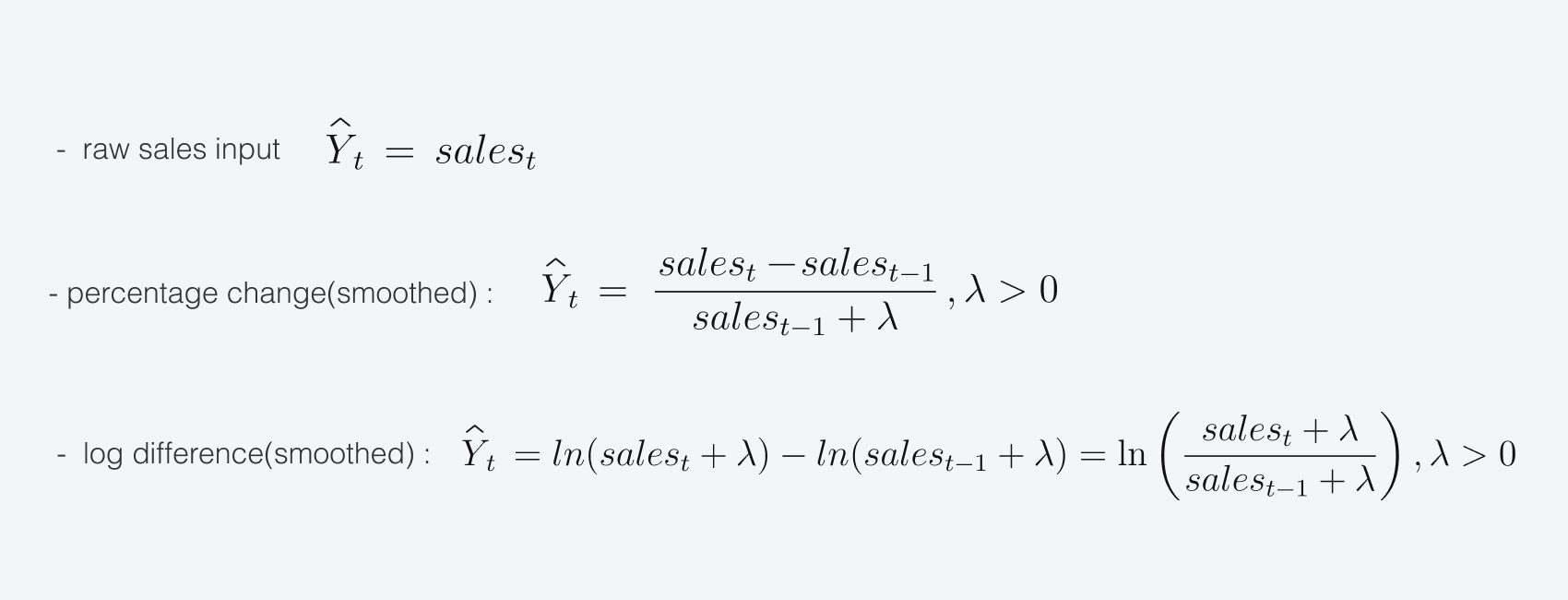
More detailed information regarding pros and cons of these approaches to target transformation and using seq2seq models can be found here.
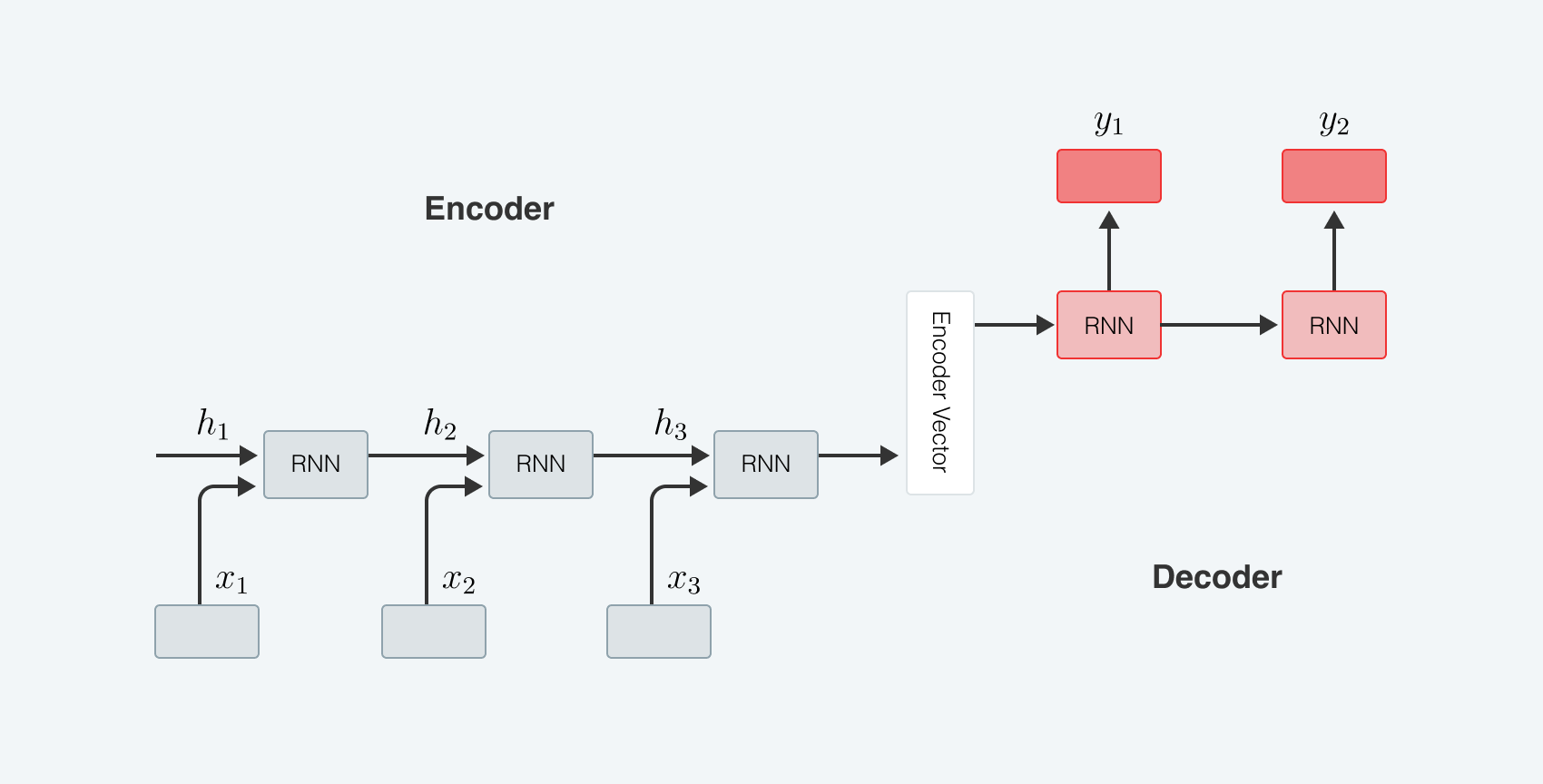
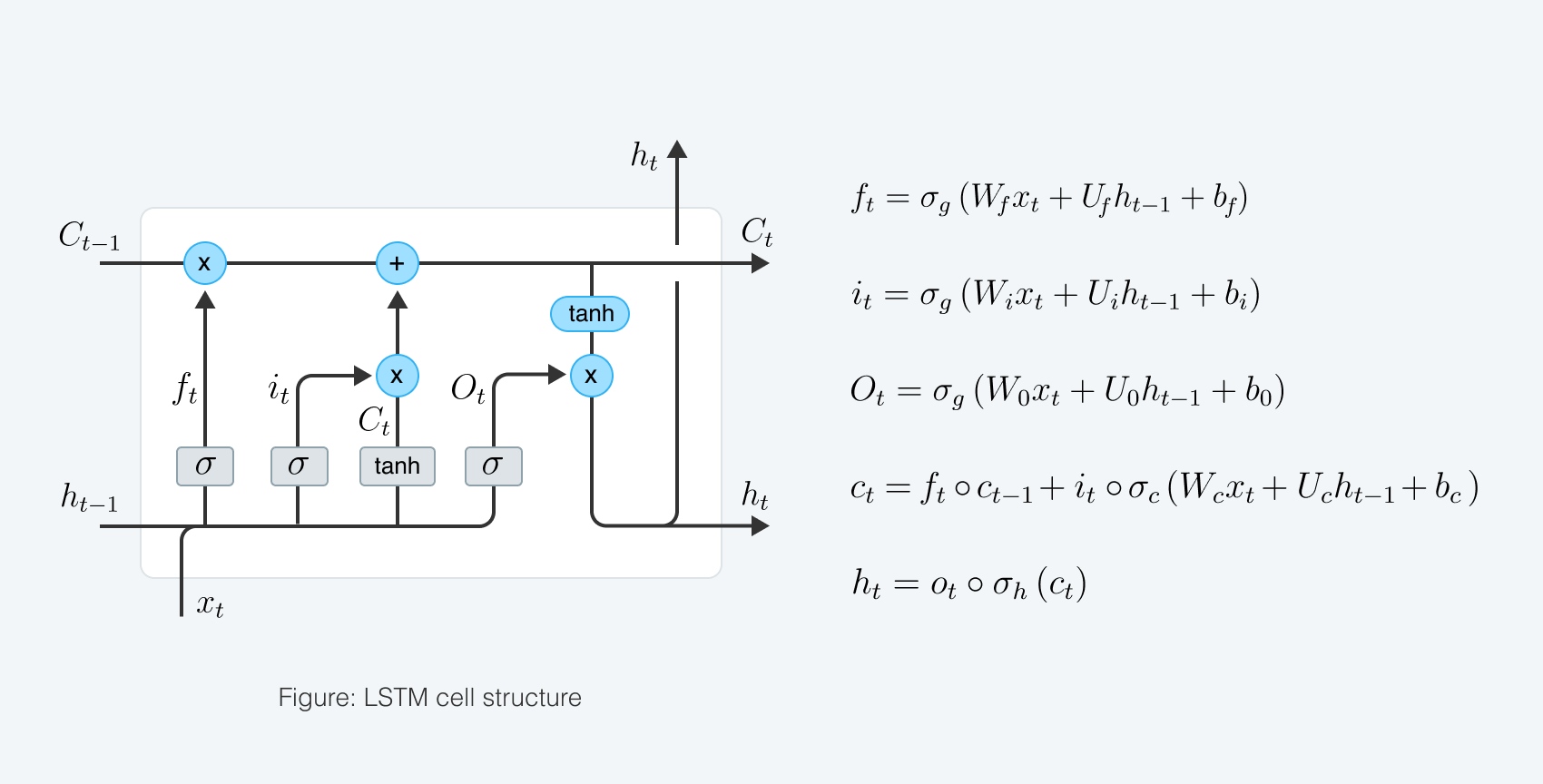
We’ve built a seq2seq LSTM model with Luong attention mechanism for predicting log difference in sales data.
To capture category-level dependencies impact we used static category embeddings. Time features such as week and month number were fitted to the model as dynamic temporal embeddings, which significantly increased model accuracy due to high seasonality factor present in the data. Accumulated Local Effects for time features reflect initial sales data distribution.
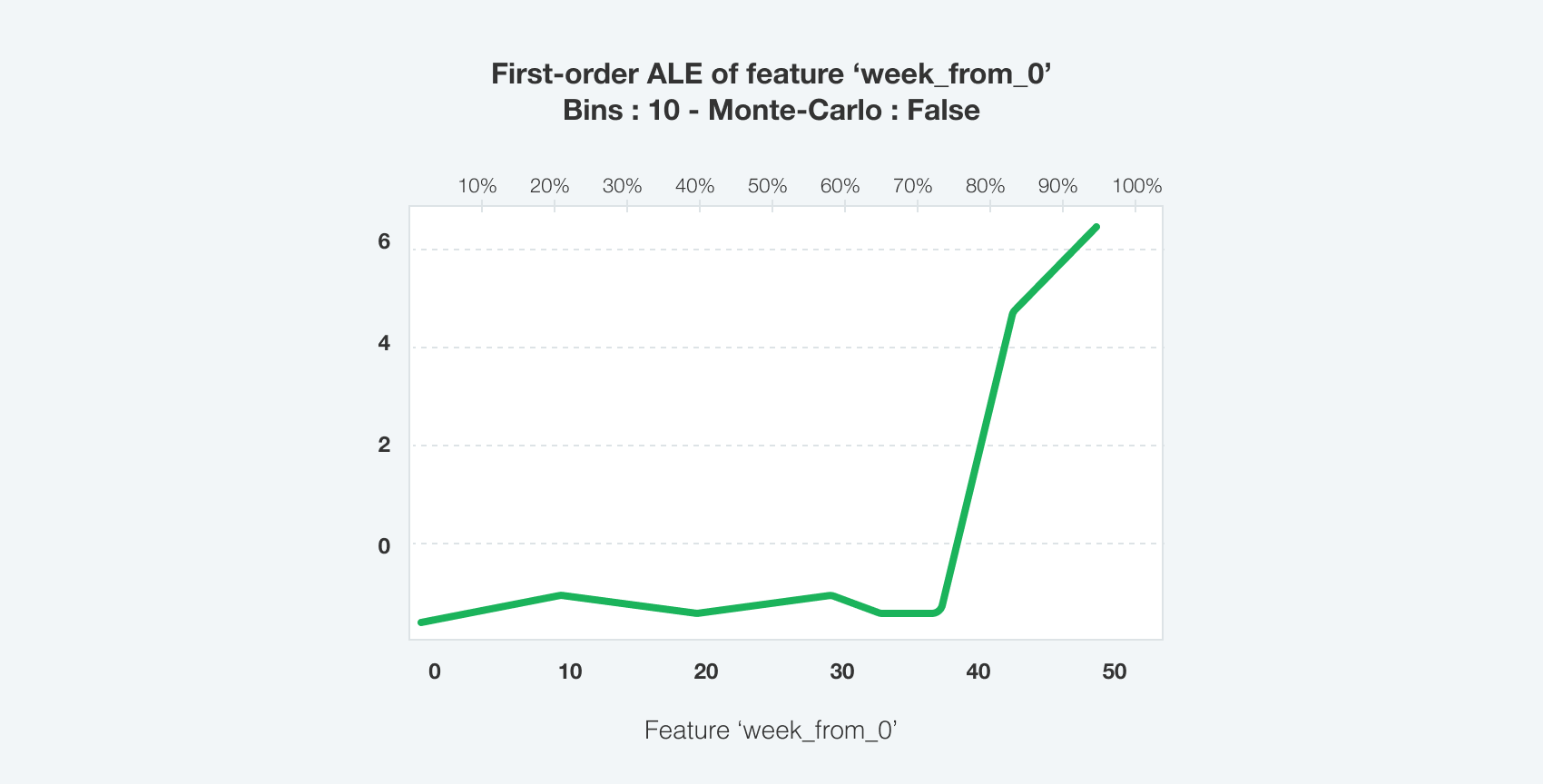
(Detailed: Apley, Daniel W., and Jingyu Zhu. 2016. Visualizing the Effects of Predictor Variables in Black Box Supervised Learning Models. https://arxiv.org/abs/1612.08468; Molnar, Christoph. 2020. Interpretable Machine Learning. https://christophm.github.io/interpretable-ml-book/)
To better adapt the model for business needs we used sample weights, depending on product`s prices, sales dynamics and time period. This allowed us to get more accurate predictions on A-segment assortment during high season.
Final results
Model forecasts hit the 96.0% accuracy on total revenue predictions and 99.6% on trees category revenue prediction on test period. So, the final metrics are:
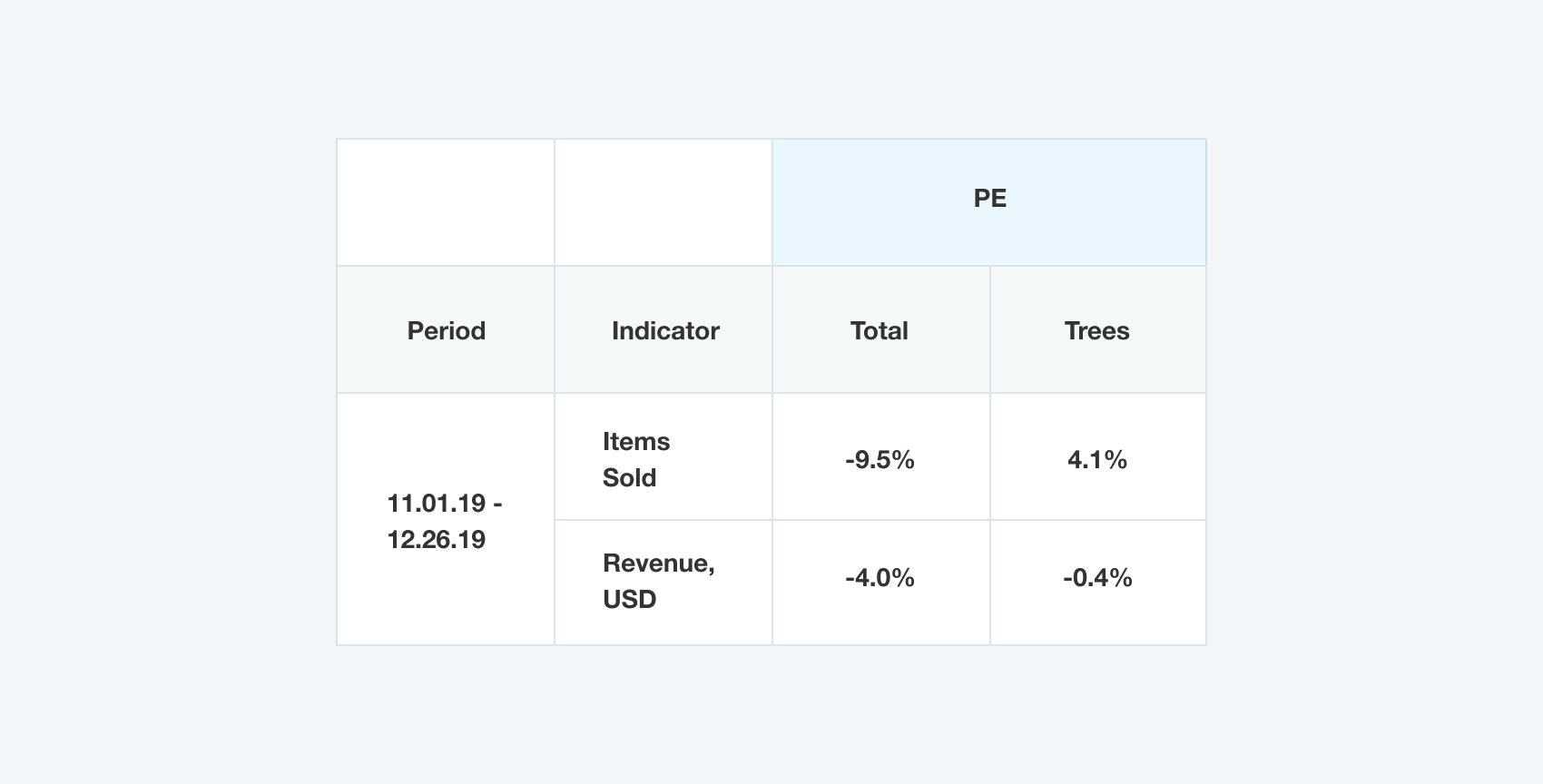
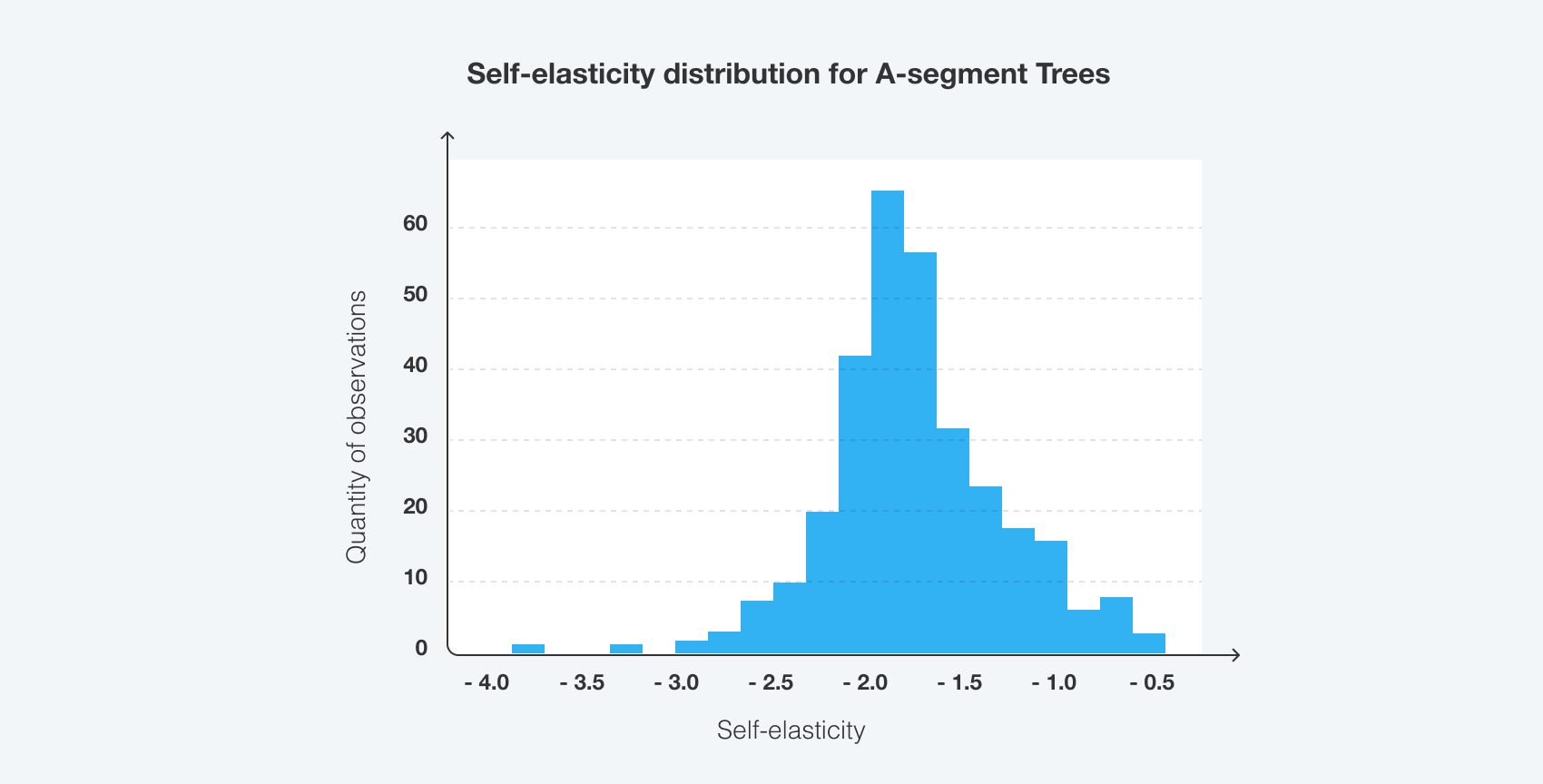
The model showed its accuracy on product- and week level. Overall WAPE on the holdout dataset is 66.7%. That allows algorithms to accurately restore products' own elasticities as well as cross-elasticities and operate pricing strategies on product and week level to hit global goals. You can see the example of own elasticities calculated for A-segment trees on the image below:
Findings described in this article will be primarily of interest to data scientists and analytics alike. If you want to get a better grasp of how neural networks can deliver optimal prices to your consumers don’t hesitate to drop us a line.
Bio: Lena Boichuk is a Data Scientist at Competera.
Original. Reposted with permission.
Related:
- Production Machine Learning Monitoring: Outliers, Drift, Explainers & Statistical Performance
- Forecasting Stories 3: Each Time-series Component Sings a Different Song
- Forecasting Stories 4: Time-series too, Causal too