Data Validation and Data Verification – From Dictionary to Machine Learning
In this article, we will understand the difference between data verification and data validation, two terms which are often used interchangeably when we talk about data quality. However, these two terms are distinct.
By Aditya Aggarwal, Advanced Analytics Practice Lead, and Arnab Bose, Chief Scientific Officer, Abzooba
Quite often, we use data verification and data validation interchangeably when we talk about data quality. However, these two terms are distinct. In this article, we will understand the difference in 4 different contexts:
- Dictionary meaning of verification and validation
- Difference between data verification and data validation in general
- Difference between verification and validation from software development perspective
- Difference between data verification and data validation from machine learning perspective
1. Dictionary meaning of verification and validation
Table 1 explains dictionary meaning of the words verification and validation with a few examples.

To summarize, verification is about truth and accuracy, while validation is about supporting the strength of a point of view or the correctness of a claim. Validation checks the correctness of a methodology while verification checks the accuracy of the results.
2. Difference between data verification and data validation in general
Now that we understand the literal meaning of the two words, let's explore the difference between "data verification" and "data validation".
- Data verification: to make sure that the data is accurate.
- Data validation: to make sure that the data is correct.
Let us elaborate with examples in Table 2.

3. Difference between verification and validation from software development perspective
From a software development perspective,
- Verification is done to ensure the software is of high quality, well-engineered, robust and error-free without getting into its usability.
- Validation is done to ensure software usability and capacity to fulfill the customer needs.
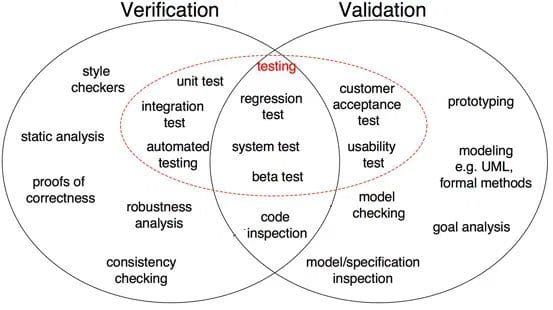
Fig 1: Differences between Verification and Validation in software development (Source)
As shown in Fig 1, proof of correctness, robustness analysis, unit tests, integration test and others are all verification steps where tasks are oriented to verify specifics. Software output is verified against desired output. On the other hand, model inspection, black box testing, usability testing are all validation steps where tasks are oriented to understand if software meets the requirements and expectations.
4. Difference between data verification and data validation from machine learning perspective
The role of data verification in machine learning pipeline is that of a gatekeeper. It ensures accurate and updated data over time. Data verification is made primarily at the new data acquisition stage i.e. at step 8 of the ML pipeline, as shown in Fig. 2. Examples of this step are to identify duplicate records and perform deduplication, and to clean mismatch in customer information in field like address or phone number.
On the other hand, data validation (at step 3 of the ML pipeline) ensures that the incremental data from step 8 that is added to the learning data is of good quality and similar (from statistical properties perspective) to the existing training data. For example, this includes finding data anomalies or detecting differences between existing training data and new data to be added to the training data. Otherwise, any data quality issue/statistical differences in incremental data may be missed and training errors may accumulate over time and deteriorate model accuracy. Thus, data validation detects significant changes (if any) in incremental training data at an early stage that helps with root cause analysis.
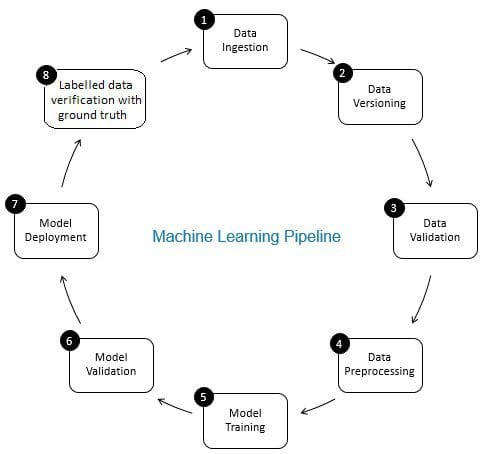
Fig 2: Components of Machine Learning Pipeline
Aditya Aggarwal serves as Data Science – Practice Lead at Abzooba Inc. With more than 12+ years of experience in driving business goals through data-driven solutions, Aditya specializes in predictive analytics, machine learning, business intelligence & business strategy across a range of industries.
Dr. Arnab Bose is Chief Scientific Officer at Abzooba, a data analytics company and an adjunct faculty at the University of Chicago where he teaches Machine Learning and Predictive Analytics, Machine Learning Operations, Time Series Analysis and Forecasting, and Health Analytics in the Master of Science in Analytics program. He is a 20-year predictive analytics industry veteran who enjoys using unstructured and structured data to forecast and influence behavioral outcomes in healthcare, retail, finance, and transportation. His current focus areas include health risk stratification and chronic disease management using machine learning, and production deployment and monitoring of machine learning models.
Related:
- MLOps – “Why is it required?” and “What it is”?
- My machine learning model does not learn. What should I do?
- Data Observability, Part II: How to Build Your Own Data Quality Monitors Using SQL