Machine Translation in a Nutshell
Marketing scientist Kevin Gray asks Dr. Anna Farzindar of the University of Southern California for a snapshot of machine translation. Dr. Farzindar also provided the original art for this article.
By Kevin Gray and Dr. Anna Farzindar
Kevin Gray: Briefly, what is machine translation?
Dr. Anna Farzindar: Machine translation is an automated software to translate text or speech from a source language (e.g., Persian) into a target language (e.g., English) without human intervention. Google translate, Microsoft Translator and Amazon translate are examples of Machine translation (MT) services where the user can select a language pair in translation task (Persian-English) and MT will render text or speech into another language.
The machine translation tools could meet demands for a high volume of information, involving the translation of millions of words, a high velocity of content translation, in a variety of domains dealing with multi-lingual communications. These capacities of translations could not be possible in a traditional way.
With exponential growth in data and recent advances in statistical machine translation (SMT) and neural machine translation (NMT), the quality of translation is significantly improved in terms of adequacy and fluency.
In many sensitive cases, such as legal or medical translation, the output of machines could serve human translators by adding a post editing step where a human can review the raw output of machine to increase the accuracy and clarify the ambiguous text.
KG: Could you give us a brief history of it?
AF: Machine translation is a sub-domain of Natural Language Processing which is its oldest application. The early days of machine translation back to the Second World War marked with the successes of code-breaking of the Georgetown IBM experiment of the mid-50’s allowing the U.S. track the Russians. The public live demo translated 49 sentences from Russian to English where the machine could translate 250 words and 6 grammatical rules. Also, this experience was important as the first non-numerical applications for computers. A short movie about the state of machine translation in 1954 showed how the researchers were optimist about completing this task over five years!
In the 50s & 60s, both governments and the industry started to invest a lot in exciting research in machine translation in the US and across the globe in the UK, Japan and Russia. This continued until the 70’s after spending huge amounts of money and efforts into several attempts of translations from Russian to English, where the final result was in fact disappointing with poor quality of translation. The scientists concluded that MT was an unsuccessful task and that machines were useless. In 1966, the Automatic Language Processing Advisory Committee (ALPAC) reported $20 million spent on translation in the US per year where there were not that many Russians and where money would be better spent teaching humans Russian!
The only success was the project entitled “Traduction Automatique de l’Université de Montréal” (TAUM) in Canada for English-French translation. The system translates the Météo weather forecasts which has been operating ever since. Again, in the 80’s the commercial market and MT research expanded with Ruled-based systems.
KG: What is the current state-of-the-art of machine translation?
AF: There are three main approaches to machine translation which developed in order of timeline:
- In the 80’s Rule-based systems (RbMT) were developed relying on build dictionaries and write transformation rules on the lexicon, grammar and syntax phraseology of a language. These methods were limited to translation within specific domains only and needed a big effort to expand to the new language. Examples of these approaches are Météo, for weather forecasts, and SYSTRAN.
- In the 90’s the Statistical systems (SMT) arrived as Corpus based methods and increased research in this field. To build a SMT, the method requires parallel corpora for sentence-aligned in language pairs (e.g., French-English) and monolingual corpora in target language (e.g., English) for translation (see below figure).
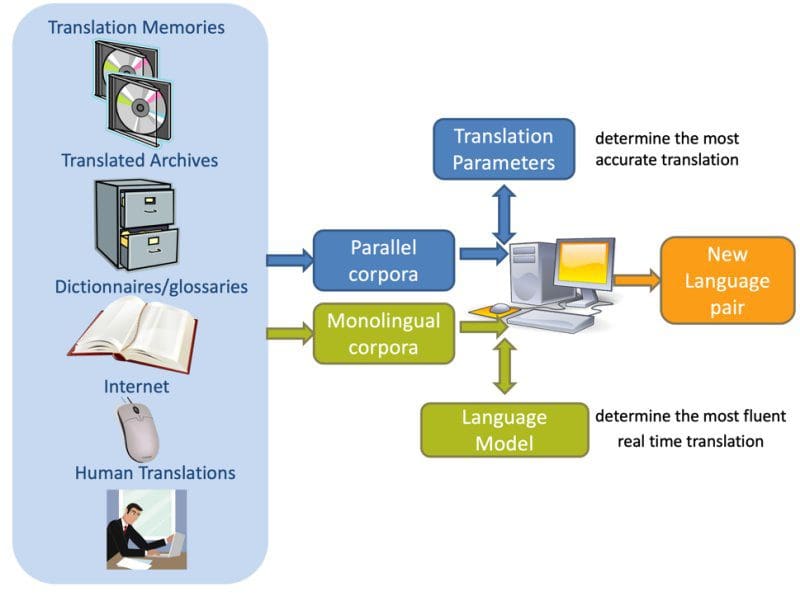
Figure 1: SMT learns from parallel and monolingual corpora to build a machine translation for a new language pair.
The SMT systems learned from Parallel Corpora in reference texts (e.g., translated documents by agencies) to build the translation parameters that are statistically most likely to be suitable. Also, it learned from Monolingual corpora the language model with the probability of seeing that target language string to determine the most fluent translation.
These systems train faster than ruled-based MT where there is enough existing language material to reference for building a new language pair or adapting for a new domain. A combination of ruled-based and SMT, called Hybrid MT, was used in some systems such as Systran to improve speed and high overall translation quality. Around 2010, the market reached the commercial viability and demand for machine translation systems.
From 2007 to 2017, I led a translation effort in my start up, NLP Technologies Inc. with the collaboration of University of Montreal for developing a robust technology for legal text translations of Canada's official languages, English and French. The system TRANSLI (Machine Translation of Legal Information) was very successful in Canada for translating French to English and vice versa. Later on we expanded the system for processing various government domains.
In this project we used Wikipedia monolingual corpora (20m-1.7b words available in 23 languages) for our language model and the following parallel corpora:
- French-English Legal Dataset from decisions by the Supreme Court, the Federal Court, the Tax Court and the Federal Court of Appeal of Canada.
- The Canadian Hansard Corpus including the debates from the Canadian Parliament, with 10 million words.
- Europarl Parliamentary Proceedings with 21-way parliamentary proceedings and 10 million to 50 million words per language.
Our new technologies allowed the creation of opportunities for the company where professional translators contribute to localization, post-editing, project management, and quality assessment to produce certified translation services in large scale. Follow this link for details.
Since 2010 Neural MT (NMT) uses a large artificial neural network to predict the likelihood of a sequence of words (e.g., entire sentences) in a single integrated model using the encoder-decoder architecture for recurrent neural networks (RNN); the Encode source language words as vectors that represent the relevant information and the Decode vectors into words preserving syntactic and semantic information in the target language. Deep neural machine translation is an extension of neural machine translation, which processes multiple neural network layers instead of just one.
In 2015 the Attention mechanism was proposed as a solution to the limitation of the Encoder-Decoder model specially for long sequences. The encoding processes the input sequence to one fixed length vector from which to decode each output time step. Attention was proposed as a method which learns to align and translate jointly.
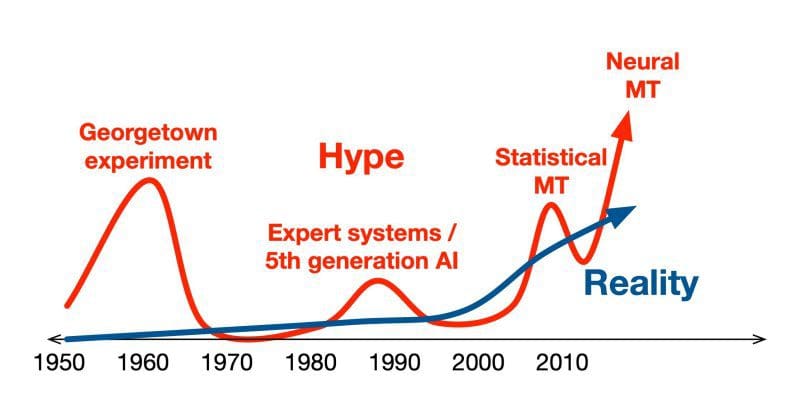
Figure 2: MT History: Hype vs. Reality, image by Philipp Koehn
KG: What are the key challenges it faces from a technical perspective?
AF: There are still several technical challenges for Machine Translation. One of the important aspects of modern MT systems is the availability of the amount of training data. There are many languages that we don’t have enough digital bilingual texts for applying machine learning. In this case, we should consider the low-resource scenarios such as machine translation for Somali, a spoken language in Africa.
Machine translation of very long or too short sentences is challenging. The systems have lower translation quality on sentence length of about 60 words or more. Machine translation for literature and fiction is still a challenge. The translation of very short sentences such as comments in social media is hard because of a lack of context and information. Some words in the sentence could be ambiguous (such as Apple; a fruit, a company or a nickname for New York City!).
To resolve the ambiguity, the context of surrounding sentences or paragraphs would be necessary. We conducted a study on machine translation of hashtags and unknown out-of-vocabulary words from social media (Gotti et al., 2014). For example, MT for English to French of #siliconvalley will be #siliconvalley. But what about the machine translation of #Goldvalley? Should it translation to #Vallée-de-l'Or or #Val-d'Or or remain #Goldvalley?
Recently some researchers intended to work on the data to help the COVID-19 pandemic as a collaborative project in 35 different languages. TICO-19: The Translation Initiative for Covid-19 aimed to improve the development of tools and resources to better access information about COVID-19. This project not only worked on high resources languages but also on the lesser resourced languages, in particular languages of Africa, South Asia where the populations may be the most vulnerable to the spread of the virus (Anastasopoulos et al. 2020)
KG: How can a layperson evaluate different machine translation software? How can we tell which one is best for our purposes?
AF: In machine translation, two kinds of errors are common: Fluency and Adequacy. In evaluation of Fluency of a translation, we should answer the following questions: Is this translation good in English (or another target language)? Is it grammatically, correct? Is it the right idiomatic word choices?
In evaluation of Adequacy, we consider: Did the meaning of the input get properly conveyed? Is there any information lost? Is there any extra information added to the original text?
Therefore, the machine translation output can be evaluated by human judges or automatically, using software. Human judges can compare the output of MT system and human reference translations, then give a score of one to five for Fluency and Adequacy.
The automatic metrics use the gold standard translation (human reference translations) to measure the degree of difference between human and machine translations. The methods like BLEU (bilingual evaluation understudy) and NIST are widely used in research and industry. The automatic evaluation allows testing of new features and models into developing the systems. It also provides a method for the automatic optimization of system parameters with no additional cost for evaluation in a timely manner.
The task-based evaluation metrics measure the effectiveness of MT output with respect to a specific task. For example, it can measure the post-editing time expected to modify the output of MT to bring it close to the references.
KG: Thinking about the future, where is machine translation heading?
AF: Machine translation is quickly becoming an important component for international businesses. These systems provide cost-effective ways to create, manage, and deliver a better globalization strategy with a balance of cost, time, quality, and consistency.
Machine translation could be integrated in different environments on any devices to break language barriers. Recently, Amazon launched a Live Translation feature for Echo devices owners that lets Alexa act as a live interpreter.
Virtual Meetings and online conferences could benefit from live translation. Google’s researchers work on the simultaneous translation problem. In addition, this technology could be used in live translated captions for audio or video.
Machine translation technologies are relevant for assisting health communication in the shortage of human interpreters. Machine translation represents a revolution in the legal field of intellectual property and patent system. Experts could get access to a vast amount of patent information on various languages during the different stages of patent prosecution and in searches for prior documents. These systems are trained on a large volume of patents documents and legal terminology. Some companies provide the machine translation services for patents in more than thirty languages.
KG: How can we learn more about machine translation?
AF: Here are a few sources for more information about this subject.
A history of machine translation from the Cold War to deep learning:
https://www.freecodecamp.org/news/a-history-of-machine-translation-from-the-cold-war-to-deep-learning-f1d335ce8b5/
AMTA is the North American component of the International Association for Machine Translation (IAMT):
https://amtaweb.org
Some interesting books about MT:
https://amtaweb.org/resources/#bookshelf
KG: Thank you, Anna!

The painting:
Title: Ethics of Technology
Technique: Ink and watercolor on handmade paper
Size: 37in x 25in
Year: 2020
Artist: Anna Farzindar
Kevin Gray is President of Cannon Gray, a marketing science and analytics consultancy.
Anna Farzindar, Ph.D. is a faculty member of the Department of Computer Science, Viterbi School of Engineering, University of Southern California.
Related: