Top 38 Python Libraries for Data Science, Data Visualization & Machine Learning
This article compiles the 38 top Python libraries for data science, data visualization & machine learning, as best determined by KDnuggets staff.
It has been some time since we last performed a Python libraries roundup, and as such we have taken the opportunity to start the month of November with just such a fresh list.
How We Built This List of 38 Python Libraries for Data Science
Last time we at KDnuggets did this, editor and author Dan Clark split up the vast array of Python data science related libraries up into several smaller collections, including data science libraries, machine learning libraries, and deep learning libraries. While splitting libraries into categories is inherently arbitrary, this made sense at the time of previous publication.
This time, however, we have split the collected on open source Python data science libraries in two. This first post (this) covers "data science, data visualization & machine learning," and can be thought of as "traditional" data science tools covering common tasks. The second post, to be published next week, will cover libraries for use in building neural networks, and those for performing natural language processing and computer vision tasks.
Again, this separation and classification is arbitrary, in some instances more than others, but we have done our best to group tools together by intended use case, hoping this is most useful for readers.
We Organized Python Libraries for Data Science Into 6 Categories:
The categories included in this post, which we see as taking into account common data science libraries — those likely to be used by practitioners in the data science space for generalized, non-neural network, non-research work — are:
- Data - libraries for the management, manipulation, and other processing of data
- Math - while many libraries perform mathematical tasks, this small collection does so exclusively
- Machine learning - self explanatory; excludes libraries primarily meant for building neural networks or for automating machine learning processes
- Automated machine learning - libraries that primarily function to automate processes related to machine learning
- Data visualization - libraries that primarily serve a function related to visualizing data, as opposed to modeling, preprocessing, etc.
- Explanation & exploration - libraries primarily for exploring and explaining models or data
Our list is made up of libraries that our team decided together by consensus was representative of common and well-used Python data science libraries. Also, to be included a library must have a Github repository. The categories are in no particular order, and neither are the libraries included within each. We contemplated constructing an ordering arbitrarily by stars or some other metric, but decided against it in order not explicitly stray from placing any perceived value or importance of the libraries within. Their listing here, then, is purely random. Library descriptions are directly from the Github repositories, in some form or another.
Thanks to Ahmed Anis for contributing to the collection of this data, and to the rest of the KDnuggets staff for their inputs, insights, and suggestions.
Note that visualization below, by Gregory Piatetsky, represents each library by type, plots it by stars and contributors, and its symbol size is reflective of the relative number of commits the library has on Github.
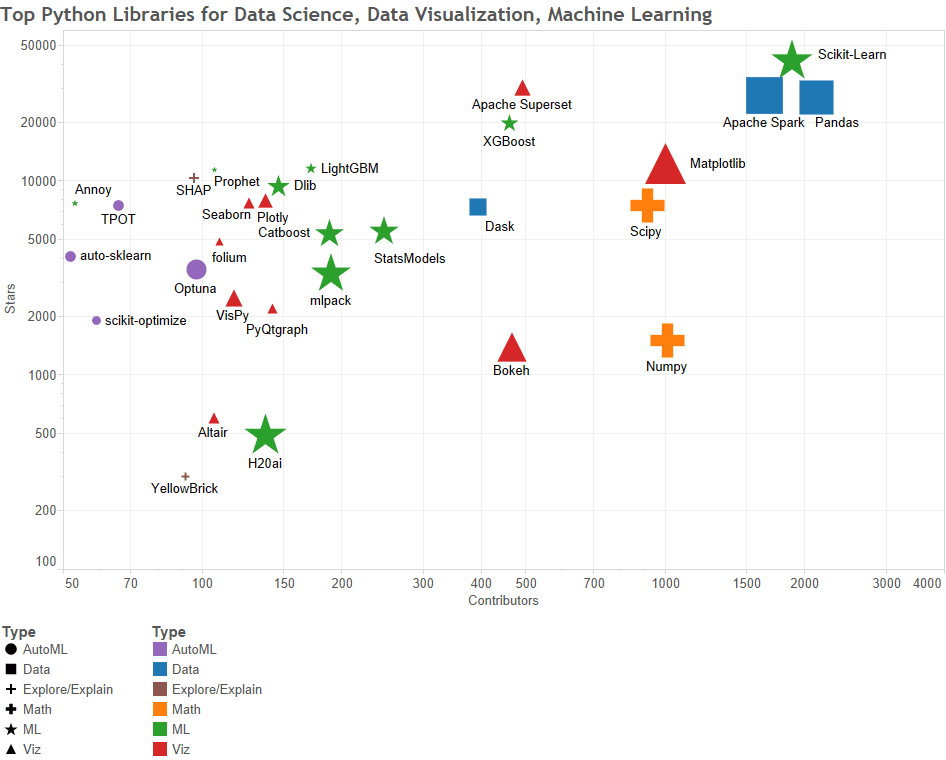
Plotted by number of stars and number of contributors; relative size by number of contributors
And, so without further ado, here are the 38 top Python libraries for data science, data visualization & machine learning, as best determined by KDnuggets staff.
Best Python Libraries for: Data
1. Apache Spark
Stars: 27600, Commits: 28197, Contributors: 1638
Apache Spark - A unified analytics engine for large-scale data processing
2. Pandas
Stars: 26800, Commits: 24300, Contributors: 2126
Pandas is a Python package that provides fast, flexible, and expressive data structures designed to make working with "relational" or "labeled" data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real world data analysis in Python.
3. Dask
Stars: 7300, Commits: 6149, Contributors: 393
Parallel computing with task scheduling
Best Python Libraries For: Math
4. Scipy
Stars: 7500, Commits: 24247, Contributors: 914
SciPy (pronounced "Sigh Pie") is open-source software for mathematics, science, and engineering. It includes modules for statistics, optimization, integration, linear algebra, Fourier transforms, signal and image processing, ODE solvers, and more.
5. Numpy
Stars: 1500, Commits: 24266, Contributors: 1010
The fundamental package for scientific computing with Python.
Best Python Libraries For: Machine Learning
6. Scikit-Learn
Stars: 42500, Commits: 26162, Contributors: 1881
Scikit-learn is a Python module for machine learning built on top of SciPy and is distributed under the 3-Clause BSD license.
7. XGBoost
Stars: 19900, Commits: 5015, Contributors: 461
Scalable, Portable and Distributed Gradient Boosting (GBDT, GBRT or GBM) Library, for Python, R, Java, Scala, C++ and more. Runs on single machine, Hadoop, Spark, Flink and DataFlow
8. LightGBM
Stars: 11600, Commits: 2066, Contributors: 172
A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.
9. Catboost
Stars: 5400, Commits: 12936, Contributors: 188
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
10. Dlib
Stars: 9500, Commits: 7868, Contributors: 146
Dlib is a modern C++ toolkit containing machine learning algorithms and tools for creating complex software in C++ to solve real world problems. Can be used with Python via dlib API
11. Annoy
Stars: 7700, Commits: 778, Contributors: 53
Approximate Nearest Neighbors in C++/Python optimized for memory usage and loading/saving to disk
12. H20ai
Stars: 500, Commits: 27894, Contributors: 137
Open Source Fast Scalable Machine Learning Platform For Smarter Applications: Deep Learning, Gradient Boosting & XGBoost, Random Forest, Generalized Linear Modeling (Logistic Regression, Elastic Net), K-Means, PCA, Stacked Ensembles, Automatic Machine Learning (AutoML), etc.
13. StatsModels
Stars: 5600, Commits: 13446, Contributors: 247
Statsmodels: statistical modeling and econometrics in Python
14. mlpack
Stars: 3400, Commits: 24575, Contributors: 190
mlpack is an intuitive, fast, and flexible C++ machine learning library with bindings to other languages
15. Pattern
Stars: 7600, Commits: 1434, Contributors: 20
Web mining module for Python, with tools for scraping, natural language processing, machine learning, network analysis and visualization.
16. Prophet
Stars: 11500, Commits: 595, Contributors: 106
Tool for producing high quality forecasts for time series data that has multiple seasonality with linear or non-linear growth.
Best Python Libraries For: Automated Machine Learning
17. TPOT
Stars: 7500, Commits: 2282, Contributors: 66
A Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming.
18. auto-sklearn
Stars: 4100, Commits: 2343, Contributors: 52
auto-sklearn is an automated machine learning toolkit and a drop-in replacement for a scikit-learn estimator.
19. Hyperopt-sklearn
Stars: 1100, Commits: 188, Contributors: 18
Hyperopt-sklearn is Hyperopt-based model selection among machine learning algorithms in scikit-learn.
20. SMAC-3
Stars: 529, Commits: 1882, Contributors: 29
Sequential Model-based Algorithm Configuration
21. scikit-optimize
Stars: 1900, Commits: 1540, Contributors: 59
Scikit-Optimize, or skopt, is a simple and efficient library to minimize (very) expensive and noisy black-box functions. It implements several methods for sequential model-based optimization.
22. Nevergrad
Stars: 2700, Commits: 663, Contributors: 38
A Python toolbox for performing gradient-free optimization
23. Optuna
Stars: 3500, Commits: 7749, Contributors: 97
Optuna is an automatic hyperparameter optimization software framework, particularly designed for machine learning.
Best Python Libraries For: Data Visualization
24. Apache Superset
Stars: 30300, Commits: 5833, Contributors: 492
Apache Superset is a Data Visualization and Data Exploration Platform
25. Matplotlib
Stars: 12300, Commits: 36716, Contributors: 1002
Matplotlib is a comprehensive library for creating static, animated, and interactive visualizations in Python.
26. Plotly
Stars: 7900, Commits: 4604, Contributors: 137
Plotly.py is an interactive, open-source, and browser-based graphing library for Python
27. Seaborn
Stars: 7700, Commits: 2702, Contributors: 126
Seaborn is a Python visualization library based on matplotlib. It provides a high-level interface for drawing attractive statistical graphics.
28. folium
Stars: 4900, Commits: 1443, Contributors: 109
Folium builds on the data wrangling strengths of the Python ecosystem and the mapping strengths of the Leaflet.js library. Manipulate your data in Python, then visualize it in a Leaflet map via folium.
29. Bqplot
Stars: 2900, Commits: 3178, Contributors: 45
Bqplot is a 2-D visualization system for Jupyter, based on the constructs of the Grammar of Graphics.
30. VisPy
Stars: 2500, Commits: 6352, Contributors: 117
VisPy is a high-performance interactive 2D/3D data visualization library. VisPy leverages the computational power of modern Graphics Processing Units (GPUs) through the OpenGL library to display very large datasets. Applications of VisPy include:
31. PyQtgraph
Stars: 2200, Commits: 2200, Contributors: 142
Fast data visualization and GUI tools for scientific / engineering applications
32. Bokeh
Stars: 1400, Commits: 18726, Contributors: 467
Bokeh is an interactive visualization library for modern web browsers. It provides elegant, concise construction of versatile graphics, and affords high-performance interactivity over large or streaming datasets.
33. Altair
Stars: 600, Commits: 3031, Contributors: 106
Altair is a declarative statistical visualization library for Python. With Altair, you can spend more time understanding your data and its meaning.
Best Python Libraries For: Explanation & Exploration
34. eli5
Stars: 2200, Commits: 1198, Contributors: 15
A library for debugging/inspecting machine learning classifiers and explaining their predictions
35. LIME
Stars: 800, Commits: 501, Contributors: 41
Lime: Explaining the predictions of any machine learning classifier
36. SHAP
Stars: 10400, Commits: 1376, Contributors: 96
A game theoretic approach to explain the output of any machine learning model.
37. YellowBrick
Stars: 300, Commits: 825, Contributors: 92
Visual analysis and diagnostic tools to facilitate machine learning model selection.
38. pandas-profiling
Stars: 6200, Commits: 704, Contributors: 47
Create HTML profiling reports from pandas DataFrame objects