AI Infinite Training & Maintaining Loop
Productizing AI is an infrastructure orchestration problem. In planning your solution design, you should use continuous monitoring, retraining, and feedback to ensure stability and sustainability.
By Roey Mechrez, Ph.D., CTO and co-founder of BeyondMinds.
If you’ve ever tried to launch an AI solution for your business, you’ll probably be familiar with the following scenario: you’ve been working on collecting data to train your AI model on, spending weeks cleaning it, augmenting it, and enhancing it. You then explored several open-source models and architectures which could fit the problem that your AI solution tries to tackle. Next, you’ve probably used several tools to accelerate the development process and create a pipeline that will help wrap the solution, tune the parameters, and compare hundreds of training alternatives. Classic data science lab work, right? Searching for the perfect model – and developing a state-of-the-art solution that addresses the problem that AI can help solve.
If all goes well, the training goes smoothly, and your model achieves a 95% accuracy rate on the test dataset. It takes some more software magic and working on weekends to tie all the loose ends together, but you finally get to the finish line: launching your model in production – meeting the aggressive Q3 deadline.
Fast forward three months. Winter came. The model is not working well. The people on the business side that interact with your model are unhappy. The results they’re getting from your AI don’t make sense. One cold morning you’re getting an email from someone in the upper ranks with an unmistakable subject line: “your AI is not working."
That is not an anecdote. In fact, it’s a painful reality for many companies, especially when it comes to mission-critical or operational sensitive applications, such as defect detection, claim automation, fraud detection, customer onboarding, KYC, AML, predictive maintenance, or credit scoring.
Training your AI model with real-world data
While many factors and components can lead to the failure of an AI solution in production, the root problem lies deep in the basic design of this process. The somber reality is that the vast majority of AI models that work seamlessly in the controlled lab environment – fail when facing a real-world environment, in which data tends to be noisy, dynamic, and unlabeled. The most effective way to deal with this disparity is to have your AI model face production data as soon as possible, even while it’s still in the lab training phase.
The key here is to keep improving and fine-tuning the model while it’s already in production. This type of design will enable the model to progress gradually, gaining incremental improvements as it receives real-time feedback from users. Sounds pretty straightforward, right? Instead of first building an AI model then productizing it – keep a continuous build-productize-re-build loop. Unfortunately, creating this continuous design cycle is extremely complex. It involves research, orchestration, and a deep combination of software and research.
This loop should start with data labeling, followed by training, evaluation, and deployment. Once deployed in production, the loop progresses into the critical steps of monitoring and feedback collection from human users. At this point, the loop completes a full circle. It now can start over again, using the data that it gained throughout the previous steps to keep improving in the re-training step. As illustrated by this infinity-shaped loop, production deployment is no longer the finish line but the starting point for adding stability and sustainability to the model:
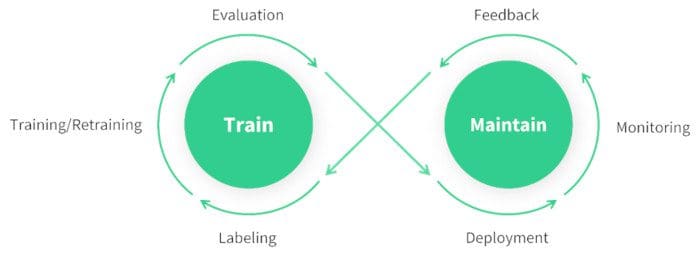
The Train & Maintain AI Infinity Loop
Avoiding maintenance pitfalls
In the product development lifecycle, system maintenance is oftentimes overlooked – with potentially catastrophic implications on the future of the system at hand. In many cases, maintenance can be a serious barrier to scaling up the system within the organization, preventing it from reaching widespread usage and impact.
When it comes to machine learning and AI, maintenance is a huge burden that can cause TCO to spiral out of control, risking the profitability of the entire use case. In recent years, AI technology has matured and become more accessible, tempting enterprises across industries to try and harvest value from AI solutions. However, the somber reality is that about 90% of enterprises fail to reach ROI-positive AI projects. Maintenance of AI solutions, and particularly the maintenance barriers in scaling up a given AI solution, plays a big part in this failure rate. This is just another reason why companies that consider delving into the AI domain should embrace the learn and maintain loop as a fundamental building block for any system they launch.
Lesson learned: evergreen AI is possible
Let’s go back to where we started off: the model you were patiently training in the lab and reached results you were happy with. What’s the main lesson learned from crashing and burning in production? The answer: aim for designing a system that identifies when data is changing (drifting away from the original data set that used to train the data in the first place), collecting ongoing feedback from human users, and retraining and deploying new and better models.
Here are some tough questions you should ask yourself before spending the first dollar on AI:
- Will I be able to detect when the data changes?
- Will I be able to detect when the model could be wrong?
- How will I collect feedback from users?
- Are proper defense mechanisms used to protect my model from the noise that can throw it off?
- What’s the process of retraining the model with new data, replacing the old, depredated model?
- How will I split the data between samples that forgo automatic processing and samples that require human inspection?
In other words, productizing AI is an infrastructure orchestration problem. In planning your solution design, you should use continuous monitoring, retraining, and feedback to ensure stability and sustainability. Succeeding in doing so will help your company deliver the desired value from AI.
Related: