How to Answer Data Science Coding Interview Questions
Use this checklist to make sure your answer to the data science coding interview questions is on the right track.

There’s no recipe for how you should answer data science coding interview questions. There’s no one approach that will always work. However, there are some guiding principles that, in most cases, will help you better answer the coding questions.
These guidelines are formed on the experience of going to the interviews and answering the coding questions. We divided these guidelines into four sections. You can use these guidelines as a checklist, especially if you’re not that experienced with data science coding interview questions. Later on, you’ll, of course, be able to find your own approach, maybe disregard some points or even include something that works for you better.
But no matter your experience, if you follow this checklist, you’re increasing your chances of giving a great answer to a coding question.
The Four-Part Checklist
The four parts of this checklist are:
- Question Analysis
- Approach to Solution
- Writing a Code
- Reviewing Your Code
Now that you have the checklist outline, we’ll look into every section and explain the checklist points it contains.
1. Question Analysis
The Question Analysis part of the checklist deals with taking a few minutes and thoroughly thinking about the question you just got. Like you will see when dealing with real business problems, it’s always better to first think about the problem and “lose” some time to see it from all perspectives. Remember, thinking is never a waste of time!
These few minutes will pay off later. If you immediately jump to writing the solution, the chances are high that you’ll have to start from scratch once you’ve realized your approach doesn’t lead to the desired solution. Or that you constantly have to change and rewrite your code.
The points that will help you practice thinking about the problem are:
- Understand the question
- Analyze the tables and data you are working with
- Think about the code result
i. Understand the Question
To make sure you understand the question, you’ll have to read the question very carefully. Read it slowly. And read it 2-3 times to make sure you didn’t miss anything. This applies to all data science interview questions, no matter how easy or hard they are. The point is, you won’t know if the question you got is hard or easy. Some of the questions can look deceptively simple, but they have some catch which is there exactly to eliminate those candidates who are not thorough enough and tend to be superficial.
If the question is not written, also feel free to ask the interviewer to repeat it if you didn’t catch something. In this case, it’s also advisable, once you understand the question, to repeat it back to the interviewer. That way, you’ll make sure you got it all right and allow the interviewer to correct themselves in case they didn’t give you all the necessary information.
ii. Analyze the Tables and Data You’re Working With
Once you understand the question, the next logical step is to analyze the tables you’re given. This means you need to analyze how many tables there are and how they are connected to each other (foreign key and primary key).
You’ll also want to see what data is in these tables. Meaning what columns are there in each table. What type of data is in every column. This is important because your code will depend on whether you’re handling string data, integer, money, or any other type of data. Maybe you’ll even need to convert one data type to another to get the desired result.
Besides the data type, it’s also important to understand how data is organized, ordered, and granulated. Meaning, are there duplicate values in the table? Is data presented on a, say, customer level, transaction level, etc.?
iii. Think About the Code Result
Before you start coding, you should know how you want your result to look like. This, of course, also depends on the question you want to answer.
But thinking about the result literary means, will it be only one value in one line or a table with several columns. If it’s a table, you again have to think about how your data will be aggregated and ordered, how many columns you have to show, etc.
Question Analysis – Example
To show you how this first section of the checklist should be applied, we’ll use the Dropbox coding question. The question goes like this:

“Write a query that calculates the difference between the highest salaries found in the marketing and engineering departments. Output just the difference in salaries.”
Link to the question: https://platform.stratascratch.com/coding/10308-salaries-differences
If you carefully read the question, you’ll realize that you’re required to find the highest salary. OK, but not the highest salary in every department but only in two departments: marketing and engineering. Once you find the highest salary in these two departments, you need to calculate the difference between them.
Now that you understand the question, you can analyze the tables and data in them. The tables you’ll work with are db_employee and db_dept. The table db_employee contains data about company employees. It has five columns:
| id | int |
| first_name | varchar |
| last_name | varchar |
| salary | int |
| department_id | int |
You see, the name columns are varchar data type, while salary is an integer. It could be important to know there are no decimals in the salary values. If you use the preview option you have available here, you’ll see this data is unique: every employee has only one salary value allocated to them. Also, an important thing to know; it could also be historical data where you’ll have all the previous salaries over the years for every employee. There’s a column department_id, which is a foreign key that links this table with the table db_dept:
| id | int |
| department | varchar |
Only two columns in this table. It’s only a list of departments, no duplicates, with six departments shown in the table.
Good, you’ve analyzed the data. Now, go back to the question and read the second sentence. Yes, this is instruction on what your solution needs to be. You don’t need to show the highest salary from one department in one column, then the highest salary from the other in the second column, and then the difference between them in the third column. No, the output will be only the difference:

There was no instruction on what this output column should be named. So it won’t be a mistake whatever you name it or if you don’t name it at all. The important thing is you get this result and nothing else.
With that, you have the foundations to write a quality code. Now is the time to time about the strategy: how will you write a code?
2. Approach to Solution
Before you start writing a code, it’s also important that you have a clear idea of what your code will look like. Coding should only be translating your (clear!) idea of the solution to the programming language.
When you think about how you should approach your solution (or write a code), consider the following:

- Are there several ways to write a code?
- State your assumptions
- Break down your solution into steps
- Start coding
i. Are There Several Ways to Write a Code?
When thinking about the solution, what first comes to mind is sometimes the best solution. And sometimes it is not. How could you know? Once you get the first idea, the trick is to think about whether there’s some other way of solving the problem. In programming languages, more times than not, there are several possible solutions.
Have this in mind. There are several reasons this is important. First, there could be some simple trick or function that easily solves something you think of solving with a lengthy code—for example, using window functions or CTEs instead of writing a code with endless subqueries.
Always go with what’s easier to write, with as few lines of code as possible. When you’re at the interview, you also have to manage time at your disposal. This is one of the ways.
Of course, if there are several more or less equally complex solutions, think about how the code will perform. On large amounts of data, different codes can take up much more time and memory to perform than others.
In short, you should think about code efficiency in two ways. One is personal efficiency, or how fast you can write a code. The second one is the code efficiency or how fast the code will perform what you want.
ii. State Your Assumptions
Stating your assumptions is important for several reasons. The first one is to say out loud and write them, which will help you see potential problems with your approach.
The second important reason is it invites your interviewer to communicate with you and even offer some help, which they usually do. If they don’t know what you want to do and why, they can’t help you. As we already mentioned, there are usually several solutions that return the same result. Communicating your assumptions allows the interviewer to steer you in the right direction based on the approach you chose. Or even steer you from the completely wrong assumptions that will mess up your solution.
The third reason is, sometimes the question could be intentionally set up to be vague. These questions are not that concerned with the right solution but with how you think. So if you state your assumptions, it will show the interviewer how you think, which they’re usually very interested in.
The fourth and final reason for stating your assumptions is even if you get the answer completely wrong but correct within the assumptions you stated, the chances are you’ll still get some points for that. The thinking, in this case, goes around these lines: OK, maybe the candidate completely misunderstood what was asked, but the solution is actually correct within the context of what they understood.
This all leads to making sure to give the right answer to an interview question.
iii. Break Down Your Solution Into Steps
This is also a helpful point that will make it easier for you to have a clear solution idea and, later on, write a clean code.
Breaking down, in this case, means writing down. Yes, write down all the key steps and functions of your solution. Think about whether you should join tables, how many tables, and which join you’ll use. Should you write a subquery or a CTE? Write down your choice. Think about what aggregate functions you’ll have to use, whether you’ll have to convert data types, should data be ordered in a specific way, should it be filtered and grouped, etc.
All these are distinct steps, so write them down, as well as the main keywords you’ll use in every step.
iv. Start Coding
This one’s an emergency point, in a way. If you did think about your approach to the solution, but you simply can’t see the complete solution before your eyes, then you should simply start writing a code.
The thinking behind this is even if you give an incomplete solution, it’s for sure worth more than not writing a single line of code. Also, some questions could be really difficult, and it’s hard even for the most experienced to see the whole solution immediately. Start coding, and there’s a chance you’ll come up with an idea along the way. And if not, again, you at least have something to show for.
One additional reason you should have in mind: some questions are not even intended to be answered. Some of them are simply (and intentionally!) too hard to solve in the time you’re given at the interview. Nobody solves them completely. The partial solution is the best anyone will get. So you will be marked on how far you got compared to the other incomplete solutions.
Approach to Solution – Example
Now that you know how you should think about your solution approach let’s use one interview question to demonstrate how it works in practice. We’ll use the Amazon coding interview question:

“Find the total cost of each customer's orders. Output customer's id, first name, and the total order cost. Order records by customer's first name alphabetically.”
Link to the question: https://platform.stratascratch.com/coding/10183-total-cost-of-orders
We’ll have to use data from two tables, table customers, and table orders with this question. We can write a code with subqueries to overcome this problem. However, you probably know that if the query and subquery are using data from multiple tables, then the solution could also be written using the JOIN. Having in mind the advice of writing as few lines of code as possible, it’s better to use JOIN.
What are the assumptions to this solution? One assumption could be that there may be customers who have zero orders. This means there could be customers in the table customers that will not show up in the table orders. The second assumption is that we will not show the customers with zero orders since the question did not explicitly say it.
Now, this already leads us to a solution breakdown. We have to output two already existing columns, so we’ll for sure use SELECT. We need to find the total of each customer’s orders. We’ll have to sum it using the SUM() aggregate function. OK, tables have to be joined. We’ll do that using the JOIN keyword. Why not some other join? Because our assumption says, we want only customers that have at least one order. Using JOIN will give us exactly that: it will join two tables and find only values (customers) that are in both tables. What next? I’ve used the aggregate function, so I’ll have to use the GROUP BY. And the result has to be ordered alphabetically, so I’ll use ORDER BY and ASC.
The resulting solution breakdown could then look like this:
- SELECT
- SUM (total_order_cost)
- JOIN
- GROUP BY
- ORDER BY ASC
In your case, this is not an emergency since you understood everything, so you can move on to the next checklist section. Or you can also find the most common SQL JOIN interview questions here.
3. Writing a Code
After assessing the question and laying out the strategy for your code, it’s time that you start writing it.
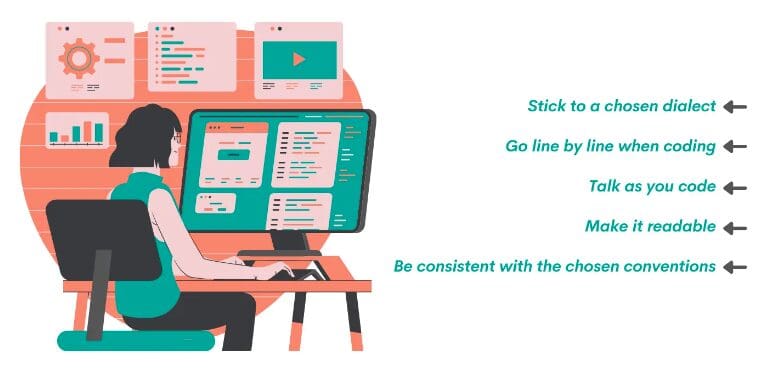
- Stick to a chosen dialect
- Go line by line when coding
- Talk as you code
- Make it readable
- Be consistent with the chosen conventions
i. Stick to a Chosen Dialect
This is especially important if you’re in the SQL coding interview. As you already know, there’s an ANSI/ISO SQL standard, and there are many SQL dialects. Virtually every RDBMS uses its own SQL dialect. Of course, you can’t know all of them. And the company you’re interviewing for is probably using one of those dialects.
If the interviewer doesn’t care which dialect you use, choose the one you’re most comfortable with. Don’t try to appeal to the interviewer by choosing the SQL dialect they use if you’re not very strong with coding in that dialect. It’s better to choose the dialect you know best and solve the problem than using some other dialect you don’t feel so sure about. If you choose the latter one, chances are you’ll be more nervous than necessary. Also, not being that familiar with the particular SQL dialect could make you mess up the solution.
Once you choose the SQL dialect, stick to it. For example, if you choose to write in PostgreSQL, don’t mix it up with T-SQL.
ii. Go Line by Line
Having a clear solution breakdown will help you check this point almost unnoticed. As you have the functions and sections of your code already outlined, you just need to remain calm and write a code systematically following the solution outline. Code is nothing more than a programming language version of your thoughts. If your thoughts and your solution outline are clear, your code will be too.
If you start jumping from one line to another, you’ll get yourself and the interviewer confused. Which will probably lead to not writing the correct code.
iii. Talk as You Code
As you write your code line by line, you should also talk about what you’re doing. This is important because when saying out loud what you’re doing, it’s easier for you to see if you’re doing something wrong. Everything could sound great in your head. But when you voice it out, the not-so-great ideas really stick out! This gives you the opportunity to correct the code as you go along. Otherwise, you could finish your code, not even realizing you did something wrong.
One of the reasons why it’s important to explain every line as you write it is it again invites the interviewer to participate in your solution. It makes it possible for them to understand what you’re doing and give you some hints. If you just write a code and keep to yourself what you’re doing, the interviewer will also probably shut down and simply wait for you to finish the code to let you know how you did.
iv. Make it Readable
Having a well-structured code is a joy to see simply from the aesthetic point of view. Not only that, but it makes it easier for you and for the interviewer to read your code.
The main thing that makes your code readable is mentioned in one of the points above: write it as simple as possible. However, some solutions can’t be simple. And even a few lines of code could be a nightmare to read if you don’t make an effort to make it readable.
One of the tips to keep in mind is to use space, tab, and enter. And use it a lot! These keys are there to separate your code into sections, making it easier to understand what the code does. Think of it like anything you say or write. Space, tab, and enter will make your code have commas, sentences, and paragraphs.
If possible, use aliases for tables. But try to make them self-explanatory. Avoid using single-letter aliases, but also don’t make aliases too verbose and descriptive. The same goes for the variable names.
While SQL is not case sensitive, it’s always better to write the SQL keywords in the upper case. This will also make them stick out in the code, especially if all the column and table names are written lowercase.
Check out our post "Best Practices to Write SQL Queries: How To Structure Your Code" which focuses on how your SQL queries can be improved, in particular when it comes to performance and readability.
v. Be Consistent With the Chosen Conventions
There are no rules that make you write in upper or lower case; there’s no prescribed naming convention, so it’s up to you and how you like it. But whatever you do, be consistent with it.
If you want to write all the new column names in lower case and separate words with underscores, please do so and keep it that way. Naming a column salary_per_employee looks rather good. But try to avoid naming one column salary_per_employee, the other one SalaryPerDepartment, the third one ‘Total Salary’, and the fourth one MAX_sALAryPerdeparment. You’ll hurt yourself when trying to read the code, especially with the last one.
The same goes when writing table names, using aliases, etc. Keeping consistency will also add to your code readability.
Speaking of consistency, we’ll show you how this checklist section works in practice.
Writing a Code – Example
Here’s a coding question by Facebook:
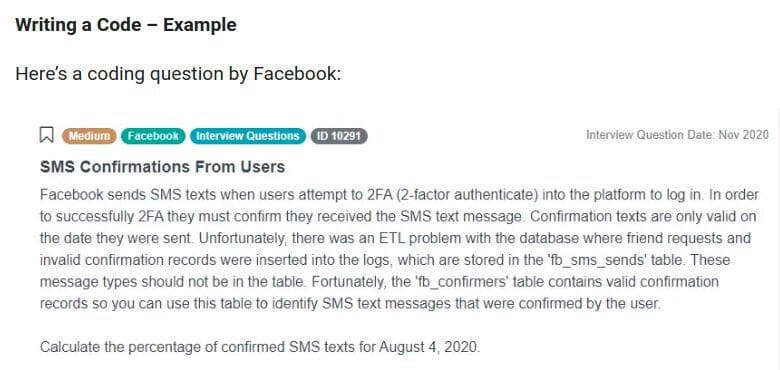
“Facebook sends SMS texts when users attempt to 2FA (2-factor authenticate) into the platform to log in. In order to successfully 2FA they must confirm they received the SMS text message. Confirmation texts are only valid on the date they were sent. Unfortunately, there was an ETL problem with the database where friend requests and invalid confirmation records were inserted into the logs, which are stored in the 'fb_sms_sends' table. These message types should not be in the table. Fortunately, the 'fb_confirmers' table contains valid confirmation records so you can use this table to identify SMS text messages that were confirmed by the user.
Calculate the percentage of confirmed SMS texts for August 4, 2020.”
Link to the question: https://platform.stratascratch.com/coding/10291-sms-confirmations-from-users
If you write a code like this, it will cover everything that we mentioned in this checklist section:
SELECT cust_id,
SUM(total_order_cost) AS revenue
FROM orders
WHERE EXTRACT('MONTH'
FROM order_date :: TIMESTAMP) = 3
AND
EXTRACT('YEAR'
FROM order_date :: TIMESTAMP) = 2019
GROUP BY cust_id
ORDER BY revenue DESC
Let’s imagine Facebook uses SQL Server, but it leaves it up to you which SQL dialect you’ll write your code in. You’re not familiar with T-SQL, so you decide to write in PostgreSQL.
For example, EXTRACT() and double colon (::) are functions typical for PostgreSQL. The first one extracts the part of the date from the datetime data type. It doesn’t exist in T-SQL! So if you said to the interviewer you’re writing in T-SQL and then use this function, you’d be making a mistake. In T-SQL, you should use the DATEPART() function. And you should know that this function in PostgreSQL is called DATE_PART(). One underscore could mean a difference between your code working and not working.
Similarly, double colon (::) in PostgreSQL is used for data type conversion. In T-SQL it doesn’t work; you’ll have to use either CAST() or CONVERT().
Having a solution breakdown for this code will make it easy for you to write it line by line. It’s easy, actually. First, you have to select some data from a table, filter it, group it, and finally order it. Don’t first write the WHERE clause, then go to SELECT statement, then to data type converting or any other bizarre way of approaching your code.
As you code, you could talk to the interviewer like this: I’m selecting the column cust_id using the SUM() function to calculate the revenue from table orders. Then I’m using the WHERE clause to filter data based on the month and year from the column order_date. After that, I’m grouping data on customer level and ordering the result in a descending order.
You see that there is indentation to this code, there is a new line for every key part of the code, and naming conventions are consistent. Do you want to see how the code could look like if we didn’t follow this? Here it is:
SELECT cust_id,SUM(total_order_cost) AS REVENUE FROM ORDERS WHERE EXTRACT('MONTH' FROM order_date :: TIMESTAMP) = 3 AND EXTRACT('YEAR' FROM order_date :: TIMESTAMP) = 2019
GROUP BY cust_id order BY Revenue DESC
Good luck with reading it!
4. Reviewing Your Code
After you’ve written the code, it’s time you review it before it becomes your final answer. If you’ve followed all the items on a checklist so far, it’ll be easy for you to review it.
Reviewing your code is, in a way, checking it against some points on your checklist:
- Check how much time you have left
- Check it against the required output
- Check it against the stated assumptions
- Check its readability
- Lead the interviewer through the solution
- Optimize your code
i. Check How Much Time You Have Left
All other points in this part of the checklist depend on this one. If you have no time left, then you can’t do anything. You did what you did, and your code is the answer you’ve got, like it or not.
Time management is important, so you should intentionally leave some time for reviewing a code. Ideally, you’ll have time to perform the three following checks.
ii. Check the Code Against the Required Output
You should go back to your question and see if your code really returns what is required. Did you forget to include some required columns? Did you really order the result like it’s requested? Those and other similar questions are you should ask yourself.
If you have time, correct the mistakes you made. If there’s no time, leave the code as it is, but write down what you did wrong.
iii. Check the Code Against the Stated Assumptions
You wrote your code based on some assumptions. Go back to your assumptions list and check if you followed them.
It would be perfect if you did. But when writing more complex code, it’s possible that you discarded some assumptions or introduced new ones. Write that down, too. If you didn’t follow all the assumptions, but you think you should have and you have time to change the code, do it. If not, leave it as it is.
iv. Check the Code Readability
Here you should check whether you understand what you just wrote. Go back to your code, check once again every line for its syntax and logic. As you go line by line, assess whether the code readability could be improved. Were you consistent in naming conventions? Are your aliases clear to understand? Is there any ambiguity? Is the code structured in a logical way and into logical parts?
Again, if you have time, improve the code readability. If there’s no time, try writing down or simply remembering what you could’ve done better.
v. Lead the Interviewer Through the Solution
If you did all the steps above, this one should just come naturally to you. The most important thing is that you’re honest when you explain your code.
Whatever mistakes you found in your code when reviewing it, state them explicitly. Don’t count on your interviewer not noticing them. Don’t try to hide them. Own your mistakes and show that you know what you did wrong. Everybody makes mistakes, but not everybody can realize they made them and admit to them. It shows you know what you’re doing even though you made a mistake. Speaking of mistakes, here are the most common ones people make in data science interviews.
If you included an unnecessary column in your output, say so and continue explaining the output you have. You strayed away from your initial assumptions or included new ones? Say so and explain why. If you did it by mistake, say it wasn’t intentional, but you see that your solution should include some additional assumptions. State what they should be for your code to work. The same goes with readability: if you see you could make your code better, explain how.
By doing all this, you’ll not only show your coding ability but also how fast you think, that you’re accountable and honest. These are all very highly regarded characteristics by all companies.
vi. Optimize Your Code
The last question in the coding interview is usually the one that asks you to optimize your code. That way, the interviewer will test your SQL theory knowledge. For example, if you know that JOINs can be computationally time-consuming? You’ll be asked to find out if there’s a way to eliminate JOIN or a subquery. For example, you can usually remove a subquery in the WHERE clause with some function, such as ranking function, if trying to find the maximum value.
Or if you know how fast operations are performed on certain data types. For example, string comparison is slow than integer comparison, so maybe there’s a way to do it on string data?
Conclusion
All this sums up to this: writing a code should almost be a technicality if you structure your approach well. The accent is more on thinking and less on coding. And writing a code should be done in a very organized way.
You should think through the question, the data you have in front of you, the possible solution(s), your assumptions, and the functions you’ll need. Only after that, you should start coding. Once you start coding, you should be able to include the interviewer in what you’re doing and let them know every step you make. Like in real life, you’ll have to check and optimize your code before you start using it in production. This interview is your production; manage your time so that you can review your solution.
These are the things you should do. There are also more preparation tips in our post: 5 Tips to Prepare for a Data Science Interview.
All this is not easy. It requires experience and practice; nobody can fake this. But following this checklist will for sure add a solid structure to your thinking and interview performance, no matter your experience. It can only make you perform better.
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Connect with him on Twitter: StrataScratch or LinkedIn.
Original. Reposted with permission.