Models Are Rarely Deployed: An Industry-wide Failure in Machine Learning Leadership
In this article, Eric Siegel summarizes the recent KDnuggets poll results and argues that the pervasive failure of ML projects comes from a lack of prudent leadership. He also argues that MLops is not the fundamental missing ingredient – instead, an effective ML leadership practice must be the dog that wags the model-integration tail.

The latest KDnuggets poll reconfirms today's dire industry buzz: Very few machine learning models actually get deployed. In this article, I'll summarize the poll results and argue that this pervasive failure of ML projects comes from a lack of prudent leadership. I’ll also argue that MLops is not the fundamental missing ingredient – instead, an effective ML leadership practice must be the dog that wags the model-integration tail.
Considering the growing chatter about ML’s failure to launch, there's been relatively little concrete industry research – especially when it comes to surveys on model deployment in particular rather than ROI in general – so I proposed this poll to Gregory Piatetsky and Matthew Mayo of KDnuggets. They helped me formulate and wordsmith it.
The results are dismal, but there's an optimistic slant: In most cases, the only missing ingredient for achieving deployment that drives real value is the right leadership practice – along with some pretty rudimentary executive ramp-up. That is, the excitement about ML is deserved. The problem is that this excitement currently focuses almost entirely on the core technology itself, rather than its launch into production.
FIRST POLL QUESTION: What percentage of machine learning models (created by you or your colleagues with the intention of being deployed) have actually been deployed?
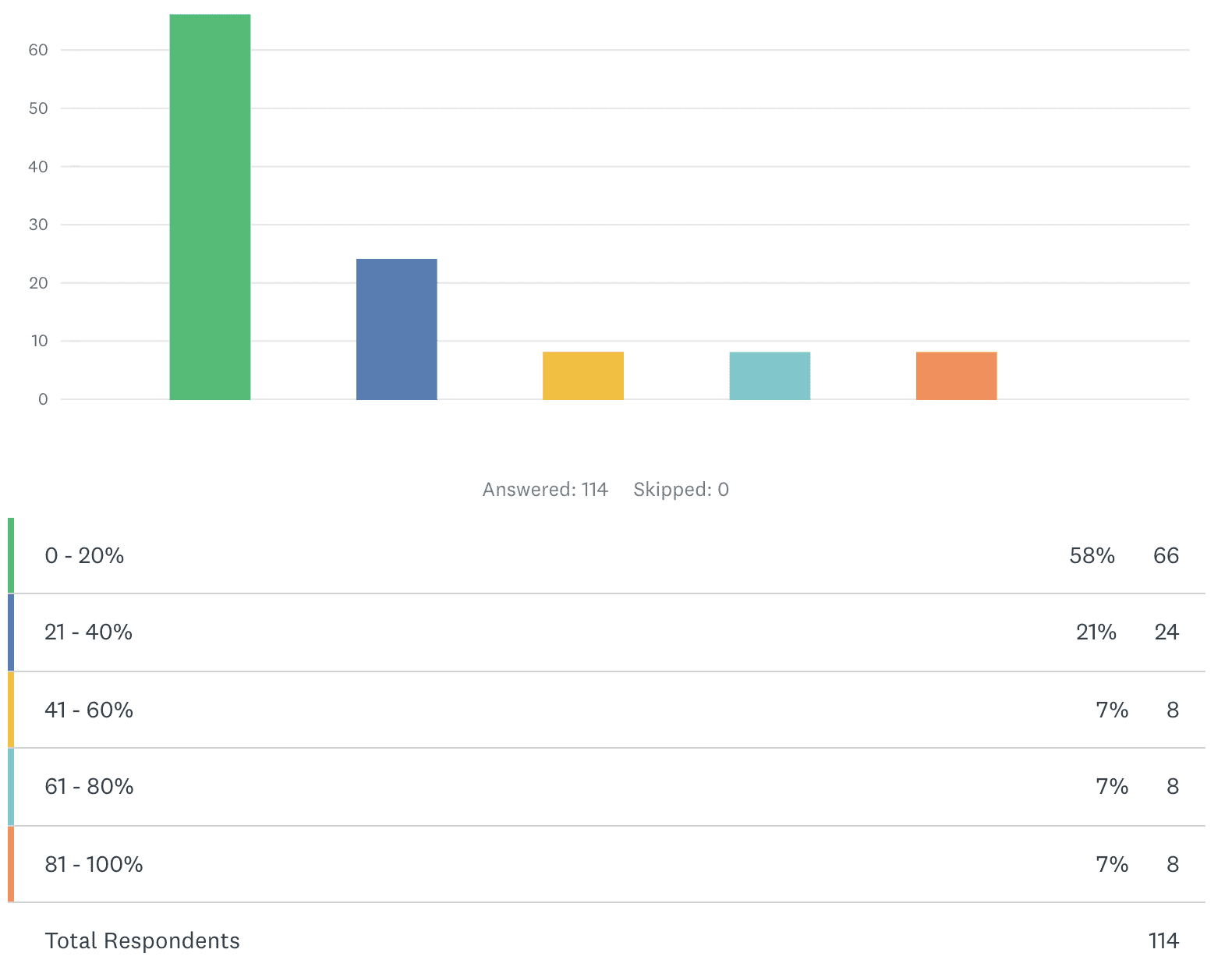
The majority of data scientists say that only 0 to 20% of models generated to be deployed have gotten there. In other words, most say that 80% or more of their projects stall before deploying an ML model.
This astonishingly low success rate is consistent with previous industry research. See Thomas Davenport and Katie Malone's article for a well-presented overview of the track record, which includes results from Rexer Analytics' survey of data scientists showing that, several years ago, only 13% said their models are always deployed (in the more recent 2020 survey, this dropped to 11%, Karl Rexer told me). Managers follow suit, indicating that "only 10% of companies obtain significant financial benefits from AI technologies," according to research from MIT Sloan Management. One Gartner analyst also estimated that close to 85% of big data projects fail. Plus, "the average return on all AI investments by company is only 1.3%" and "only 20% of AI projects are in widespread deployment," according to a 2020 survey of senior executives by ESI ThoughtLab.
ML Leadership to the Rescue
Here's the root of the problem: We fetishize the core ML methods that generate models rather than the thing we should be more excited about – actually using those models in the field. If we were to truly prioritize model deployment, we'd aggressively lead in that direction by rigorously planning for it from the get-go, before any hands-on work had even begun.
Let me put it another way. Today's hype about the number crunching capability itself – with relatively little focus on achieving deployment – is like being more excited about the building of a rocket than its launch.
The data scientist's impulse is to go "hands on" with modeling as soon as possible. This applies just as well to newcomers, who jump almost exclusively into hands-on courses and books that presume the training data is already prepared. This forms a glaringly false narrative in which the first step of an ML project is to load the data into the modeling software.
This erroneous presumption, that the data is already in place, is a glaring symptom of the ML industry's collective "Missing the Point" syndrome. It reveals that we're not training practitioners to have their eye on the ball: deployment. After all, even before you can begin preparing the data, its requirements – most notably, the dependent variable's definition – depend heavily on a well-scoped, informed, socialized, and ultimately greenlit project designed to achieve deployment. Deployment means radical change to existing operations. You can't presume that the decision makers will easily buy in. Deeply collaborating with them is more central than generating a model.
Deep learning, with all its promise and importance, only magnifies the problem, increasing the hype-to-achieved-value ratio. Such projects are even more likely to be speculative and exploratory – more on the R&D side with a wider distance to traverse before any eventual possibility of deployment. Deep learning projects often introduce new operations and capabilities, such as with image-processing models that suggest diagnoses to doctors or drive autonomous vehicles. This stands in contrast to more established business applications of what are typically simpler modeling methods, which only enhance existing operations, such as for fraud detection and credit scoring. Further, the complexity of deep learning models also means the integration challenges are that much more likely to be underestimated and not sufficiently planned for.
"AI" hype skews the focus from practical deployment even more notoriously. When you move to pursuing "intelligence", you stop solving a particular problem with predictive scores. Instead, you're pursuing a fallacy. Intelligence is an objective that cannot be defined in a meaningful way in the context of engineering. See Richard Heimann's new book, Doing AI, which exposes AI's false narrative: its claim to be – or at least soon be – the ultimate one-size-fits-all solution, a silver bullet capable of solving all problems. And for more on this, I've made a short series of videos about why legitimizing AI as a field incurs great cost to business.
The right ML leadership practice bridges a divide that’s greater than most realize. It forges a viable path to deployment, which includes achieving buy-in from key business leaders – who often provide input that changes the data scientist’s original conception of a project. Without being proactively engaged, these folks will typically stand in the way of deployment.
For a deeper dive, see my articles on ML leadership in KDnuggets, Harvard Business Review, and Analytics Magazine (INFORMS), plus my online ML course (see the video on why data scientists need to learn the business side of ML) and the operationalization conference track of Machine Learning Week. Speaking of which, the host of that conference track, consultant James Taylor, is a leading authority in this area. He has published many articles on the topic, such as one on the basics of operationalizing ML and one on why organizations struggle with becoming data-driven.
The Problems Caused by a Lack of ML Leadership
The second poll question explored the kinds of problems that stand in the way of deployment.
SECOND POLL QUESTION: In your experience, what is the main impediment to model deployment?
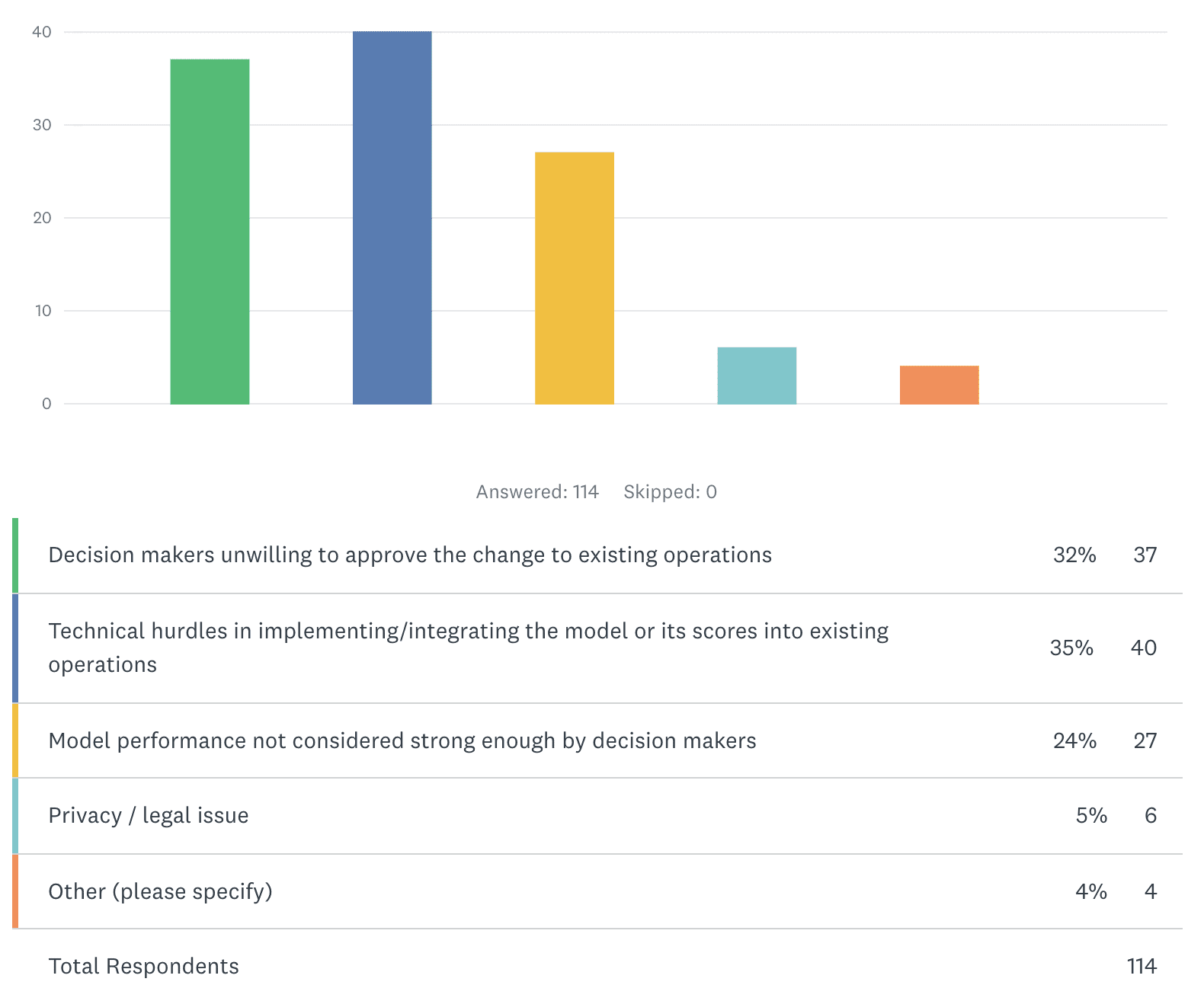
It's a lack of leadership that most often impedes deployment. Among the top three responses, which together make up 91%, only one alludes to a possible failure in modeling rather than a failure in project planning: "performance not considered strong enough by decision makers." However, you can bet this often stems from poorly managing the expectations of supervisors as to whether models will be "highly accurate" (most will not be) and whether more realistic models would be valuable if deployed nonetheless (most would be). ML leadership must ramp up decision makers accordingly.
Integration challenges (35%) actually reflect a failure of leadership rather than a failure of tech or a lack of MLops, in most cases. After all, with deployment the objective set forth from the inception of an ML project, assessing the technical integration requirements – and planning for their fulfillment – must be equal in priority to the modeling itself. MLops may be a key part of that fulfillment, but it isn’t a deployment cure-all. The greatest bottleneck for deployment is usually gaining buy-in from human decision makers, even if the integration challenges are also impressive. In any case, leadership is the fundamental that tackles all obstacles, whereas MLops is only one of many tools at leadership’s disposal. If it turns out that MLops is the main missing ingredient, that’s due to a failure of leadership, not an argument that MLops is the singular solution to our deployment woes in general.
The lower-ranked "privacy/legal" issues could also stem from a lack of foresight and planning – although such issues can arise unexpectedly. Given the great importance of and widespread attention given to these matters, it's notable that they aren't more often ranked as the main impediment. It could be that ML projects simply don't get far enough to face these issues, stalling earlier due to the other issues.
More Signs of the ML Deployment Crisis
This poll received 114 responses, far fewer than many KDnuggets polls. It may be that the question of deployment simply doesn't apply for many data scientists, who aren't yet at the point of generating predictive models meant for deployment – or who aren't even headed in that direction, instead employing “descriptive” analytics methods other than ML. But there may too be adverse self-selection among those who don't really want to mentally confront this particular lack of success. It can be frustrating when you find out the hard way, over time, that what seems like a "no-brainer" value proposition isn't so readily apparent to the powers that be, who instead err on the side of caution in light of the potential pitfalls they envision should they greenlight model deployment. After all, KDnuggets focuses almost exclusively on the hands-on technical process, only rarely publishing articles focused on the business deployment. Its readers compose a community of technically-savvy experts who focus much more on the number crunching than its operationalization. If it's the case that these frustrated data scientists held back from participating in this survey, then the situation is even more dire than what's reflected in these survey results.
Given the low count, there's little to nothing to conclude via cross-tabs. In any case, here's the full dataset in case you'd like to dig in.
Finally, the responses to the last of this three-question poll further confirm its pertinence:
THIRD POLL QUESTION: What is your employer type?
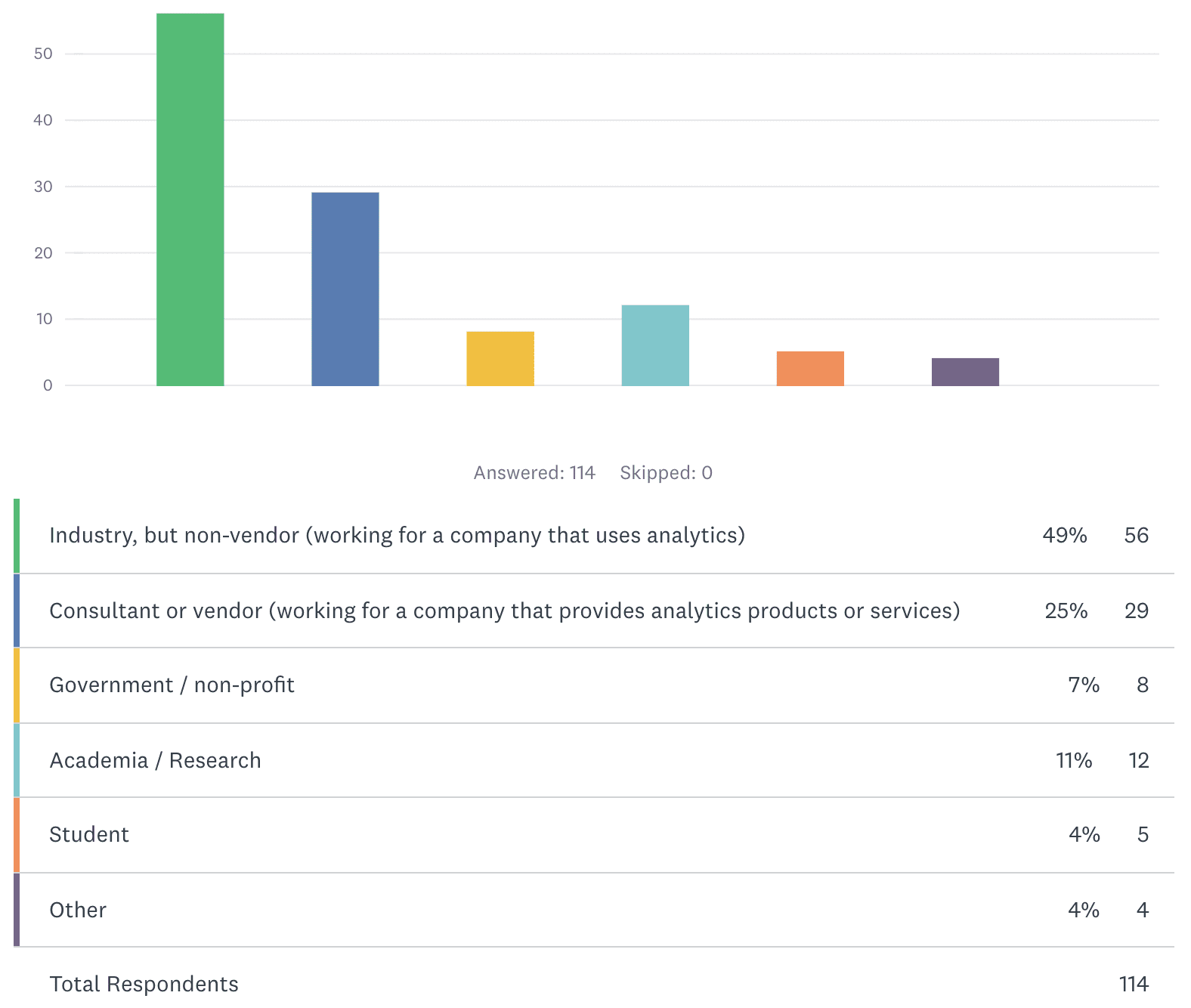
The majority of respondents are industry practitioners, which is where deployment ultimately counts. We can expect vendors to have a bias toward reporting less failure; their tools enable the analysis and, in some cases, the technical integration side of deployment, but the leadership practice needed to achieve deployment is a human rather than software endeavor. They don’t sell that. Counterbalancing that possible bias, academics and students are much less likely to be working toward industrial deployment in the first place. These suppositions do appear to pan out in the numbers, but the separate segments are too small to draw conclusions.
Finally, the four who selected "Other" for the second question (the main impediment to deployment) wrote in these unsurprising entries:
- Research purposes [this respondent indicated "Academic/Research" as their employer type]
- too much hype, deep learning often fails at reality check
- Loss of interest
- Adoption
The Next Steps
Further industry research is needed. This short survey leaves plenty of uncertainty and plenty more to poll on. After all, some well-trodden ML projects – such as training an updated model for an existing credit scoring system at a large bank – are much more likely to succeed than new initiatives. Ideally, future surveys would differentiate by application area, industry vertical, whether the initiative is a new one, and whether they're using deep learning. We may find that, outside the most ideal circumstances, the failure rate is even higher.
But I'll conclude with a more important call-to-action: Lead ML well. Take on the leadership of ML projects toward deployment just as rigorously as you take on the application of core ML algorithms!
Eric Siegel, Ph.D., is a leading consultant and former Columbia University professor who bridges the business and tech sides of machine learning. He is the founder of the Predictive Analytics World and Deep Learning World conference series, together Machine Learning Week, which has served more than 17,000 attendees since 2009. As the instructor of the acclaimed online course “Machine Learning Leadership and Practice – End-to-End Mastery”, a winner of teaching awards as a professor, and a popular speaker, Eric has delivered more than 110 keynote addresses. The executive editor of The Machine Learning Times, he wrote the bestselling Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die, which has been adopted for courses at hundreds of universities. Eric has appeared on numerous media channels, including Bloomberg, National Geographic, and NPR, and has published in Newsweek, HBR, SciAm blog, WaPo, WSJ, and more – including op-eds on analytics and social justice. Follow him @predictanalytic.