
SQL Interview Questions for Experienced Professionals
This article will show you what SQL concepts you should know as an experienced professional.

Introduction
If you’re an experienced data scientist looking for a job, you could not have picked a better time. As of right now, many established organizations are looking for data scientists who know their craft inside and out. However, the high demand doesn’t mean that you can, or should jump through hoops and apply for senior positions without a certain skill set. When hiring experienced data scientists, companies expect them to work on the most difficult tasks at hand. These employees should have a good grasp of even the most obscure features so that they can use them when necessary.
It shouldn’t be surprising that when interviewing for senior positions, experienced data scientists tend to get asked much harder questions. Often, when working on a single job for a couple of years, data scientists become very skilled at performing certain repetitive tasks. It's essential for professionals to realize that SQL doesn’t stop and end with their existing knowledge. When it comes to advanced SQL concepts, there may still be some gaps in their knowledge. So it doesn’t hurt to get help for succeeding at your data scientist interview.
SQL is the primary language for managing databases, so performing SQL operations is at the heart of data scientists’ jobs. Most data scientist interviews are arranged to determine a candidate's knowledge of SQL.
The everyday job might not include writing complex queries, but you must show that if such skills are needed, you’re the person capable of doing it. So it shouldn’t be surprising that interviewers ask a diverse set of SQL interview questions to test the candidate’s fluency in SQL.
In this article, we wanted to summarize some of the complex questions and concepts asked in interviews with experienced professionals. Even if you’re confident in your SQL knowledge, it doesn’t hurt to scan the keywords and make sure you’ve got everything covered.
Bare minimum concepts for experienced professionals
CASE / WHEN
Thoroughly understanding the concept of CASE (and its accompanying When statement) is essential for achieving complete mastery of SQL. A case statement allows us to check certain conditions and return a value based on whether those conditions evaluate as true or false. In combination with clauses, such as WHERE and ORDER BY, CASE allows us to bring logic, conditions, and order into our SQL queries.
The value of CASE statements is not limited to providing a simple conditional logic in our queries. Experienced data scientists should have more than a surface-level understanding of the CASE statement and its uses. Interviewers are likely to ask you questions about different types of CASE expressions and how to write them.
Experienced candidates should be prepared to answer theoretical questions, such as to explain the differences between Valued and Searched CASE statements, how they work and how to write them. This requires a strong understanding of their syntax and common practices. Needless to say, this also includes the proper use of the ELSE clause.
Experienced data scientists will be expected to know how to use CASE with aggregate functions as well. You might also get asked to write a shorthand CASE statement, which is less repetitive and easier to understand. You should be able to intelligently talk about caveats and possible risks of using shorthand CASE statements.
In general, an experienced data scientist must be able to use CASE to write more efficient queries. After all, the entire purpose of the CASE statement is to avoid writing too many individual queries to consolidate the data.
Here’s an example of the question that can be solved using CASE / WHEN statements: https://platform.stratascratch.com/coding/9634-host-response-rates-with-cleaning-fees?python=
This is a difficult question asked in Airbnb interviews, where candidates have to find the average host response rate, the zip code, and its corresponding cleaning fee.
In this case, the CASE/ WHEN statement is used to format the result as a number and present it as a percentage value, in addition to the ZIP code.
SQL Joins
It’s easy to feel confident in your knowledge of SQL Joins, but the more you explore this topic, the more you’ll discover that you don’t know. Interviewers often ask interview questions about advanced aspects of SQL Joins that are often overlooked. So it’s important to delve into this concept and master it thoroughly.
Besides the basic concepts, interviewers might inquire what self cross joins are, and find out the depth of your knowledge by asking to solve practical questions. You should know all the different types of joins, including the more complex types, such as hash joins, or composite joins. You could also be asked to explain what natural joins are, and when they are the most useful. Sometimes you’ll have to explain the differences between natural and inner joins.
You should, in general, have a thorough experience and mastery of using joins in combination with other statements to achieve the desired results. For instance, you should know how to use the WHERE clause to utilize Cross Join as if it was an Inner Join. You will also be expected to know how to use joins to produce new tables without putting too much pressure on the server. Or how to use outer joins to identify and fill in the missing values when querying the database. Or the inner workings of outer joins, such as the fact that rearranging their order can change the output.
Here’s an example of the question that involves writing an inner joint statement.
This is a fairly difficult question, where the candidates are asked to display the order size as a percentage of total spending.
Advanced Concept N1: Date-time Manipulation
It is common for databases to include dates and times, so any experienced data scientist should have deep knowledge of working with them. This type of data allows us to track the order in which the events occur, changes in frequency, calculate intervals, and gain other important insights. A lot of times performing these operations requires a complete mastery of date-time manipulation in SQL. So the professionals with such a set of skills are going to have an advantage over competing candidates. If you’re not 100% confident in your skills, look over the concepts described below and see how many of them sound familiar.
Since there are many different (but valid) approaches to formatting data in SQL, great coders should be at least familiar with them all. During the interviews, hiring managers expect knowledge of basic data formatting concepts and the ability to talk intelligently about choosing the right function for the task. This includes the knowledge of an important FORMAT() function and the associated syntax to make full use of the function. The knowledge of other basic functions, such as NOW() is also expected. Also, it wouldn’t be out of the blue for experienced professionals to get asked about basic concepts like time-series data and its purpose.
It’s also important to consider the context of the job you’re applying for. An AI or IoT company would be more concerned with tracking data collected from the sensors, whereas a stock trading app might require you to track the price fluctuations during the day, week, or month.
In some cases, employers might ask about more advanced date/time functions in SQL, such as CAST(), EXTRACT(), or DATE_TRUNC(). These functions can be invaluable when you’re working with a large volume of data that contains dates. An experienced data scientist should know the purpose of each function and its applications. In an ideal scenario, he or she should have experience of using them in the past.
The most complex date-time manipulation in SQL is going to involve the combination of basic and advanced functions. So it’s necessary to know them all, starting from the more basic FORMAT(), NOW(),CURRENT_DATE, and CURRENT_TIME, and including more advanced functions mentioned above. As an experienced data scientist, you should also know what INTERVAL does and when to use it.
Here’s an example of a question asked in Airbnb interviews, where the candidates must use the available data to track the growth of Airbnb.
The Premise:
In this question, the candidates are asked to track the growth of Airbnb based on changes in the number of hosts signed up each year. In other words, we’ll use the number of newly registered hosts as an indicator of growth for each year. We’ll find the growth rate by calculating the difference in the number of hosts between the last and current year and dividing that number by the number of hosts registered during the previous year. Then we’ll find the percentage value by multiplying the result by 100.
The output table should have columns and the corresponding data for the number of hosts in the current year, in the previous year, and the percentage of growth from year to year. The percentage must be rounded to the nearest whole number and the rows must be ordered in ascending order depending on the year.
Solution:
To answer this question, a candidate must work with the table called ‘airbnb_search_details’, which includes many columns. The column that we need is labeled ‘host_since’, which denotes the year, month, and the day when the host first signed up for the website. For this exercise, the month and the day are irrelevant, so the first thing we’ll need to do is to extract the year from the value. Then we’ll have to create a view that includes separate columns for the current year, previous year, and the total number of hosts in that year.
Select extract(year FROM host_since::DATE) FROM airbnb_search_details WHERE host_since IS NOT NULL
So far, we have done two things:
- We’ve made sure to only include the rows where the host_since column is not empty.
- We’ve extracted the year from the data and cast it as the DATE value.
Select extract(year FROM host_since::DATE) count(id) as current_year_host FROM airbnb_search_details WHERE host_since IS NOT NULL GROUP BY extract(year FROM host_since::DATE) ORDER BY year asc
Then we proceed to count the ids and set up the GROUP BY clause for every year. And make it display in ascending order.
This should give us a table with two columns: the year, and the number of hosts registered that year. We still don't have a full picture needed to solve the question, but it’s a step in the right direction. We also need separate columns for hosts signed up during the previous year. This is where the LAG() function comes in.
SELECT Year, current_year_host, LAG(current_year_host, 1) OVER (ORDER BY year) as prev_year_host Select extract(year FROM host_since::DATE) count(id) as current_year_host FROM airbnb_search_details WHERE host_since IS NOT NULL GROUP BY extract(year FROM host_since::DATE) ORDER BY year asc
Here, we added the third column, which will be labeled ‘prev_year_host’ and its values are going to come from ‘current_year_host’, except for the delay of one row. Here’s what that might look like:
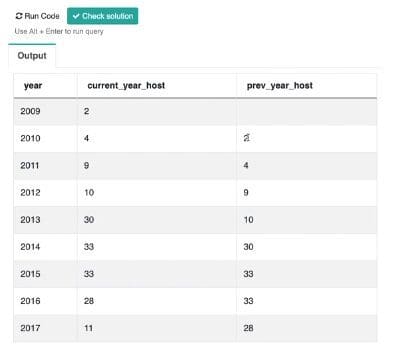
Arranging the table in this way makes it very convenient to calculate the final growth rate. We have a separate column for every value in the equation. Ultimately, our code should look something like this:
SELECT year, current_year_host, prev_year_host, round(((current_year_host - prev_year_host)/(cast(prev_year_host AS numeric)))*100) estimated_growth FROM (SELECT year, current_year_host, LAG(current_year_host, 1) OVER (ORDER BY year) AS prev_year_host FROM (SELECT extract(year FROM host_since::date) AS year, count(id) current_year_host FROM airbnb_search_details WHERE host_since IS NOT NULL GROUP BY extract(year FROM host_since::date) ORDER BY year) t1) t2
Here, we add another query and another column where we calculate the growth rate. We must multiply the initial result by 100 and round it to satisfy the requirements of the task.
That’s the solution to this task. It’s clear that date-time manipulation functions were essential for completing the task.
Advanced Concept N2: Window Functions and Partitions

SQL Window Functions are one of the most important concepts for writing complex, yet efficient SQL queries. Experienced professionals are expected to have a deep practical and theoretical knowledge of window functions. This includes knowing what the over clause is and mastering its use. Interviewers might ask how the OVER clause can turn aggregate functions into window functions. You might also get asked about the three aggregate functions that can be used as window functions. Experienced data scientists should be aware of other, non-aggregate window functions as well.
To make the best use of window functions, one must also know what the PARTITION BY clause is and how to use it. You may be asked to explain it and provide examples of a few use cases. Sometimes you’ll have to organize rows within partitions using the ORDER_BY clause.
Candidates who can demonstrate a thorough knowledge of every individual window function, such as ROW_NUMBER() will have an advantage. Needless to say, the theoretical knowledge alone isn’t enough - professionals should also have experience of using them in practice, with or without partitions. For instance, an experienced professional should be able to explain the differences between RANK() and DENSE_RANK(). An ideal candidate should know some of the most advanced concepts, such as frames within partitions, and be able to explain them clearly.
Great candidates should also explain the use of the NTH_VALUE() function. It wouldn’t hurt to mention the alternatives to this function, such as FIRST_VALUE() and LAST_VALUE() functions. Companies often like to measure quartiles, quantiles, and percentiles in general. To perform this operation, data scientists must know how to use the NTILE() window function as well.
In SQL, there are usually many ways to approach a task. Still, window functions provide the easiest way to perform common, but complex operations. A good example of such a window function is LAG() or LEAD(), so you should be familiar with them as well. For instance, let’s look at an example from the previous solution to a difficult Airbnb interview question:
To display the number of hosts in the previous year, we used the LAG() function with the OVER statement. This could’ve been done in many other ways, but window functions allowed us to get the desired result in just one line of SQL code:
LAG(current_year_host, 1) OVER (ORDER BY year) as prev_year_host
Lots of companies need to calculate growth over a certain period of time. The LAG() function can be invaluable for completing such assignments.
Advanced Concept N3: Month Over Month Growth
Many organizations use data analysis to measure their own performance. This may entail measuring the effectiveness of marketing campaigns or ROI on a specific investment. Performing such analysis requires an in-depth knowledge of SQL, such as date, time, and window functions.
Data scientists will also have to prove their skills in formatting the data and displaying it as percentages or in any other form. In general, to solve the practical questions where you have to calculate month-over-month growth, you must use the combination of multiple skill sets. Some of the required concepts will be advanced (window functions, date-time manipulation), while others will be basic (aggregate functions and common SQL statements).
Let’s look at one example question asked by Interviewers at Amazon.
The Premise:
In this question, we have to work with a table of purchases and calculate monthly growth or decline in revenue. The end result must be formatted in a specific way (YYYY-MM format) and the percentages should be rounded to the second nearest decimal.
Solution:
When working on a task like this, the first thing you need to do is understand the table. You should also identify the columns you need to work with to answer the question. And what your output is going to look like.
In our example, the data values have the object type, so we’ll have to use the CAST() function to transform them into date types.
SELECT to_char(cast(created_at as date), 'YYYY-MM') FROM sf_transactions
The question also specifies a format for dates, so we can use theTO_CHAR() function in SQL to output the date in this format.
To calculate the growth, we should also select the created_at and SUM() aggregate function to get the volume of total sales for that date.
SELECT to_char(cast(created_at as date), 'YYYY-MM'), created_at, sum(value) FROM sf_transactions
At this point, we have to use window functions again. Specifically, we’re going to use the LAG() function to access last month’s volume and display it as a separate column. For that, we’ll also need an OVER clause.
SELECT to_char(cast(created_at as date), 'YYYY-MM') AS year_month, created_at, sum(value) lag(sum(value), 1) OVER (ORDER BY created_at::date) FROM sf_transactions GROUP BY created_at
Based on the code we’ve written so far, our table will look something like this:
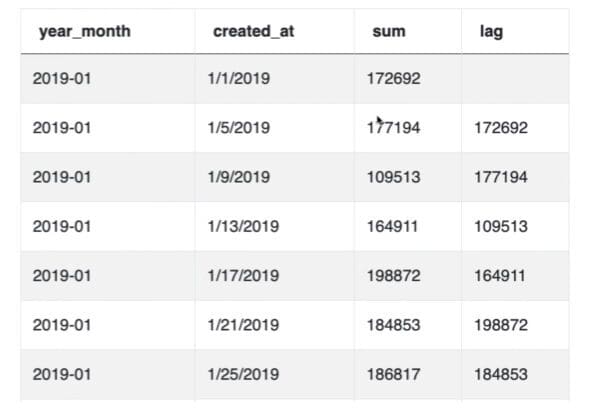
Here, we have the dates and corresponding total values in the sum column, and the last date’s values in the lag column. Now we can plug the values into the formula and display the growth rate in a separate column.
We should also remove the unnecessary created_at column, and change the GROUP BY and ORDER BY clauses to year_month.
SELECT to_char(cast(created_at as date), 'YYYY-MM') AS year_month, sum(value), lag(sum(value), 1) OVER (ORDER BY to_char(cast(created_at as date)) FROM sf_transactions GROUP BY year_month
Once we run the code, our table should only include the columns that are essential for our calculation.
Now we can finally arrive at the solution. Here’s what the final code would look like:
SELECT to_char(created_at::date, 'YYYY-MM') AS year_month, round(((sum(value) - lag(sum(value), 1) OVER w) / (lag(sum(value), 1) OVER w)) * 100, 2) AS revenue_diff_pct FROM sf_transactions GROUP BY year_month WINDOW w AS ( ORDER BY to_char(created_at::date, 'YYYY-MM')) ORDER BY year_month ASC
In this code, we take two column values from the previous example and calculate the difference between them. Note that we also make use of window aliases to reduce the repetitiveness of our code.
Then, in accordance with the algorithm, we divide it by the current month’s revenue and multiply it by 100 to get the percentage value. Finally, we round the percentage value to two decimal points. We arrive at the answer that satisfies all the requirements of the task.
Advanced Concept N4: Churn rates
Even though it's the opposite of growth, churn is an important metric as well. Many companies keep track of their churn rates, especially if their business model is subscription-based. This way, they can track the number of lost subscriptions or accounts, and predict the reasons that caused it. An experienced data scientist will be expected to know which functions, statements, and clauses to use to calculate churn rates.
Subscription data is very private and contains private user information. It is also important for data scientists to know how to work with such data without exposing it. Often calculating churn rates involves common table expressions, which are a relatively new concept. The best data scientists should know why CTEs are useful and when to use them. When working with older databases, where CTEs are unavailable, an ideal candidate should still be able to get the job done.
Here’s an example of a difficult task. Candidates interviewing at Lyft receive this assignment to calculate drivers’ churn rate at the company.
To solve this problem, data scientists must use case/when statements, window functions such as LAG(), as well as FROM / WHERE, and other basic clauses.
Conclusion
Working as a data scientist for many years certainly looks impressive on a CV, and will get you many interviews. However, once you get your foot in the door, you still need to display the knowledge to complement years of experience. Even if you have wide-ranging experience in writing queries in SQL, it doesn’t hurt to use resources like StrataScratch to refresh your knowledge.
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Connect with him on Twitter: StrataScratch or LinkedIn.