 Data science SQL interview questions from top tech firms
Data science SQL interview questions from top tech firms
 Data science SQL interview questions from top tech firms
Data science SQL interview questions from top tech firmsAs a data scientist, there is one thing you really need to understand and know how to handle: data. With SQL being a foundational technical approach for working with data, it should not be surprising that the top tech companies will ask about your SQL skills during an interview. Here, we cover the key concepts tested so you can best prepare for your next data science interview.

Structured Querying Language, more commonly referred to as SQL, is one of the most powerful data tools out there, giving us the ability to work with and analyze large amounts of data at scale. As such, any company that uses large amounts of data will benefit from having employees with strong SQL fundamentals. SQL can have widespread use at every level in a company, and being able to use SQL establishes someone's basic competence when working in data. In any role that is even tangentially related to data, even basic SQL capability creates additional value in a candidate: being able to query data for your individual needs is a valuable skill, even for less data-specific focused roles such as product manager or business analyst. Meanwhile, in any Data Science role, strong SQL skills are almost a hard requirement.
Of course, there are many other methods to store and retrieve data en masse, including Spark, Hadoop/HIVE, Snowflake, the Python library Pandas, and even Excel and Google Sheets. However, each one comes with its own set of limitations, and none of them have been able to surpass SQL in its flexibility, scalability, and ease of use as the Data Science industry standard.
There is a large range of types of questions that will show in an interview setting, but SQL is a staple you can almost always expect to be tested on, particularly for data-focused roles. We're going to go over some key concepts and ideas you need to know to prepare for those SQL interview questions, with a focus on the companies of FAANG, before applying them as we walk through a few SQL questions asked in actual interviews.
Let's get into it.
Data Science SQL Interview Concepts and Questions
Companies of Big Tech, otherwise referred to as FAANG (Facebook, Apple, Amazon, Netflix, Google), are some of the biggest employers of Data Science roles, and anyone interested in working in the data industry will naturally look at roles at these companies. But how are the SQL questions asked in interviews by FAANG different from those asked at other companies? Generally, FAANG companies organize their interview questions in case studies that test your analytical skills in the context of their product. For example, Google might have SQL questions analyzing usage on their search engines or email accounts, while Facebook might cover platform activity such as user comments and friend relationships.
At any company you interview in, it's important to make sure that coming in, you are at least moderately comfortable in using any of the platforms and products of the company you are interviewing for. For FAANG companies with this specific emphasis, that is doubly true. While you may be able to reasonably answer a standard SQL interview question with your sheer knowledge of the code, being able to understand the content you are working in, and thus discuss the scenario, trade-offs, and even potential edge cases in your solution, which can create a stronger impression in your interview.
Types of Data Science SQL Interview Questions
Let's drill down into SQL-specific questions asked in interviews. The SQL interview questions can generally be broken down into three different categories: basic definitions, reporting, and abstract problem-solving.
Basic SQL Definitions
The most basic SQL questions asked in interviews are definitions based. These are straightforward questions that test your knowledge of SQL basics, such as using common functions like SUM, MIN/MAX, and COUNT. Commonly, these questions ask for basic definitions about SQL functionality, such as differentiating between the different types of joins or how joins are different from unions. These questions can also involve asking you to write certain short queries, where you may be pulling and compiling basic information from a small set of tables to do simple functions.
Oftentimes, these earliest questions walk you through creating the basic queries that become the framework that can build into more complicated questions further down the line.
Reporting and Insights
Next up are reporting questions with SQL, which often test your ability to write common queries that you would need in day-to-day work in data analysis, with queries that identify and pull key metrics and data, such as common reporting Key Performance Indicators (KPI's) like daily active users (DAU), monthly active users (MAU), growth rates, percentage changes over time, and retention.
The earlier basic SQL definitions, including aggregations such as MIN and MAX, will be required, as well as the ability to join datasets and create your own views with Common Table Expressions (CTEs) and subqueries. At a more advanced level in reporting, percentiles and rankings are often tested, with functions such as NTILE and RANK. Usually, these are coupled with window partitions, which are advanced technical reporting concepts.
Depending on the structure of the interview, this can build upon earlier questions on basic SQL definitions, building upon the complexity of those previously covered concepts. In these questions, it is important to understand what data you are given and the output you are looking for. If given multiple tables, they will require some joins, while limiting factors in the question means you need to understand what filters should be applied.
In a previous blog post, we went more in-depth into the types of SQL Interview Questions to Prepare For. We also previously wrote about Types of Window Functions in SQL asked by some popular companies.
Problem-solving with SQL
At the highest, most advanced level are the problem-solving SQL questions. These are open-ended, often ambiguous questions that test how you would approach solving a problem with SQL. Somewhat similar to the previous reporting SQL interview questions, these come with the additional added complexity of ambiguity, where you need to consider not only the SQL output you want to report but also how to pull certain data and exactly what the data is that you want to pull.
These types of interview questions can often be further subcategorized as ETL and database design questions. ETL stands for "extract, transform, load," which is a general data processing procedure of copying data from one source into a different source or context, with the requisite data extraction, transformation, and upload. Database design is the organization of your data according to a database model, which is created by the classification of data and the identification of the relationships between those data points.
ETL can be the start of building a data science infrastructure, with the first step of collecting data and transforming it into a usable format. While these concepts are most often tested in data engineering-specific interviews, most data scientists are still expected to have solid fundamentals on how to, at minimum, create, insert, and update tables. Working with APIs would be an additional step in skill development and lays the groundwork for the next step in the data science workflow of creating models and dashboards.
Problem-solving SQL questions are an order of magnitude more complicated than the previous reporting questions, where beyond just querying and returning data with established parameters, you must also take additional steps in transforming the data between different sources and contexts, sometimes even designing an entire data pipeline. Of course, given the limited timeframe of the interview setting, the complexity of any answer to these questions will be naturally limited, covering only general steps or broad theoretical strokes.
Check out our video on Solving Complex SQL Interview Questions. We also talk about the Data Science infrastructure pipeline in our video on The One and Only Data Science Project You Need.
Finally, remember that there are also non-SQL questions asked throughout the interview process. These include personal or behavioral questions, product sense and business cases, data analysis and coding in other languages such as R and Python, and artificial intelligence and modeling questions. We cover the overarching interview process for companies at FAANG in our Ultimate Guide to the Top 5 Data Science Companies.
Data Science SQL Interview Questions Asked at Individual Companies of FAANG
Obviously, each individual company has different focuses and emphases depending on the values and products of the company itself, not to mention the team and the role itself. We will be walking through a few of the questions asked at interviews with FAANG, some of the largest data science employers in the industry. While we will go over the solutions for some of the questions, be sure to try them out for yourself before looking at the answer, or at least take a minute to fully consider how you would approach the problem before diving into the solutions.
The social media conglomerate asks a lot of product sense questions in addition to their SQL. The various social media platforms under the Facebook umbrella mean their interview questions will focus on metrics vital to those platforms, particularly user activity. Let's take a look:
Number of Comments Per User in Past 30 days

This data science SQL interview question from Facebook tests your ability to filter out data based on date conditionals. Check out the below video to find some tips on how to approach the solution.
Share of Active Users

Rank Variance Per Country

First, let's take a look at the tables we are given:
fb_comments_count
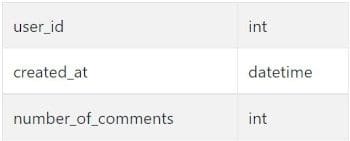
fb_active_users

Is there anything we would need to clarify in order to answer this data science SQL interview question? The phrasing can be a little confusing, so in an interview setting, if you are even a little bit unsure, be sure to ask clarifying questions. "Risen in the rankings based on the number of comments" between two months would mean the country that had an increase in the number of comments made by users from one month to the other. For example, the number of comments made by Australian users would be 5 in December 2019, but a larger number of 6 in January 2020, and thus Australia would have an increase in rank. (Check the tables out for yourself on the StrataScratch platform!)
Aside from that, consider if there are any edge cases that we might need to deal with. One big issue might be if there isn't any location data for a user, resulting in null values for the country column. We can handle this by filtering out rows where that is the case. There may also be countries that had no comments at all in the former month (December 2019) but did have comments in the latter (January 2020). Depending on how we create the joins, this will create an additional null value that we will need to account for in the final steps.
Now, let's think about what the output should look like. We're looking for a simple list of countries, but that list will be based on hidden numbers that filter for the condition of having "risen in the rankings based on the number of comments" between two months. So what do we need to get there?
First, we would need to isolate the number of comments made in each individual month. Fortunately, the number of comments has already been aggregated for us in the table fb_comments_count, so this initial step will be a straightforward join between the two tables. Since the individual users don't matter, we will group by the countries and sum together the number of comments.
SELECT
country,
sum(number_of_comments) as number_of_comments_dec,
FROM fb_active_users as a
LEFT JOIN fb_comments_count as b
on a.user_id = b.user_id
WHERE country IS NOT NULL
GROUP BY country
Note that given the phrasing of the question, and for simplicity's sake, we will be assigning rankings to each country based on their summed number of comments. Note that from the hint, we are told to avoid gaps between the ranks, so instead of the RANK function, we will use the DENSE_RANK function. While both RANK and DENSE_RANK will usually assign the grades the same rank depending on how they fall compared to the other values, DENSE_RANK will use the next chronological ranking value as opposed to skipping to the following value as RANK does. For example, RANK will go [1, 2, 2, 4, 5], while DENSE_RANK will go [1, 2, 2, 3, 4].
Let's add that to the query now.
SELECT
country,
sum(number_of_comments) as number_of_comments_dec,
dense_rank() over(order by sum(number_of_comments) DESC) as country_rank
FROM fb_active_users as a
LEFT JOIN fb_comments_count as b
on a.user_id = b.user_id
WHERE country IS NOT NULL
GROUP BY country
However, this current query actually returns an aggregate of all user comment activity, while we actually want to divide and compare two separate specific timeframes. Next up, we will separate the comments of December 2019 and January 2020. We can use the WITH header to create two separate tables of the individual months' user comment activity. For example, the December 2019 activity would look like:
SELECT
country,
sum(number_of_comments) as number_of_comments_dec,
dense_rank() over(order by sum(number_of_comments) DESC) as country_rank
FROM fb_active_users as a
LEFT JOIN fb_comments_count as b
on a.user_id = b.user_id
WHERE created_at <= '2019-12-31' and created_at >= '2019-12-01'
AND country IS NOT NULL
GROUP BY country
The next obvious step is to carry the above code from December 2019 to January 2020 by adjusting the date values filtered by our WHERE statement and combine the two segments together. Before we get there, we want to build out the full skeleton of our query. Thus, we will temporarily use the placeholder pseudocode of the individual months' WITH statements for readability. Note that the December and January tables will have the same columns and can be joined on the unique country name. In addition, we are looking for the times when the January 2020 ranking is higher than the December 2019 rank, which in numerical terms means a lesser value.
WITH dec_summary as (CODE BLOCK), jan_summary as (CODE BLOCK) SELECT j.country FROM jan_summary j LEFT JOIN dec_summary d on d.country = j.country WHERE (j.country_rank < d.country_rank)
Now one last step before we put all the fully written code back together: as we mentioned earlier, we also want to capture the edge case where there is potentially no user comment activity in the earlier month, December 2019. Based on how our tables are joined, there would be no column values from the December 2019 dec_summary table. Since we start FROM the jan.summary table, this means the December values that we LEFT JOIN onto the January summary will result in null December values. Therefore, we must add that additional null condition as an OR, which results in:
WITH dec_summary as (CODE BLOCK), jan_summary as (CODE BLOCK) SELECT j.country FROM jan_summary j LEFT JOIN dec_summary d on d.country = j.country WHERE (j.country_rank < d.country_rank) OR d.country is NULL
Finally, let's put that all together!
with dec_summary as (
SELECT
country,
sum(number_of_comments) as number_of_comments_dec,
dense_rank() over(order by sum(number_of_comments) DESC) as country_rank
FROM fb_active_users as a
LEFT JOIN fb_comments_count as b
on a.user_id = b.user_id
WHERE created_at <= '2019-12-31' and created_at >= '2019-12-01'
AND country IS NOT NULL
GROUP BY country
),
jan_summary as (
SELECT
country,
sum(number_of_comments) as number_of_comments_jan,
dense_rank() over(order by sum(number_of_comments) DESC) as country_rank
FROM fb_active_users as a
LEFT JOIN fb_comments_count as b
on a.user_id = b.user_id
WHERE created_at <= '2020-01-31' and created_at >= '2020-01-01'
AND country IS NOT NULL
GROUP BY country
)
SELECT j.country
FROM jan_summary j
LEFT JOIN dec_summary d on d.country = j.country
WHERE (j.country_rank < d.country_rank)
OR d.country is NULL
Check out our Facebook Data Scientist Interview Guide. We also talk about the broader interview process in our post about Understand the Facebook Data Scientist Interview Process.
Amazon
The multinational technology company is said to put a strong emphasis on modeling in their interview questions, such as capturing customer behavior and retention. Amazon also has a wide range of products under its company umbrella, though, of course, the questions you would realistically be asked in an interview will vary depending on the exact team or position you are applying for. That said, let's take a look at a few data science SQL interview questions on the most well-known Amazon product of eCommerce:
Total Cost Of Orders

First, let's take a look at the tables we are given:
customers
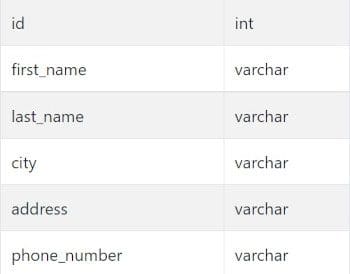
orders
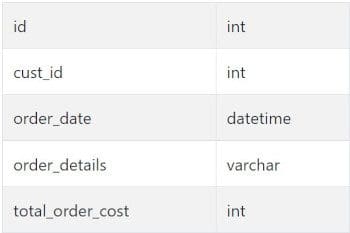
As always, start off by asking yourself some key questions: What should the output to this question look like? Are there any clarifications we want to double-check? The question is explicit about what it wants: we are getting the customer ID, customer name, and total cost of their orders sorted alphabetically. This should be a straightforward join of our given tables of customers and orders, where we can group by the customer ID and name, and then sum the total cost of the orders that they have.
Let's put together the join first:
SELECT customers.id, customers.first_name, FROM orders JOIN customers ON customers.id = orders.cust_id
Next, we want to aggregate the total costs of each customer's orders, which here is the SUM of the total_order_cost. Thus, we would be grouping the other relevant columns and then grabbing the SUM of our order cost field.
SELECT customers.id,
customers.first_name,
SUM(total_order_cost)
FROM orders
JOIN customers ON customers.id = orders.cust_id
GROUP BY customers.id,
customers.first_name
ORDER BY customers.first_name ASC;
And finally, the question asks us to order by the customer's first name alphabetically, which requires a simple ORDER BY at the end of the query:
SELECT customers.id,
customers.first_name,
SUM(total_order_cost)
FROM orders
JOIN customers ON customers.id = orders.cust_id
GROUP BY customers.id,
customers.first_name
ORDER BY customers.first_name ASC;
And there we have it!
Take a look at a few additional data science SQL interview questions from Amazon below:
Finding User Purchases
![]()
Marketing Campaign Success [Advanced]
This data science SQL interview question involves handling complex logic and implementing multiple scenarios and edge cases. Check out the video below and find how to go over this advanced SQL interview question.
Check out our article on Amazon Data Scientist Interview Questions. We also talk about the broader interview process in our Amazon Data Scientist Interview Guide.
This multinational technology company is also said to ask many modeling questions, with additional product questions leaning more into the business side of things. Again, the exact type and focus of the questions will vary according to the team and position you are applying for.
Let's take a look at a few SQL data science interview questions from Google.
Total AdWords Earnings

User Email Labels

Again, let's start off by looking at the tables provided
google_gmail_emails
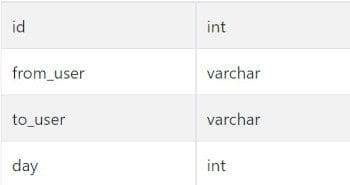
google_gmail_labels
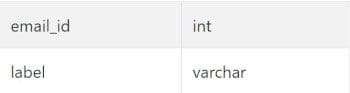
As usual, we start off by understanding what output we are looking for and then getting any clarifications that we might need or considering any potential edge cases. Here, we want to return the emails with their labels, which are stored in a separate table, so we would start off with a simple join. As we are focusing on each user and counting the number of emails they got from each type of label, we can start off by grouping our given columns of user and label before counting them individually:
SELECT mails.to_user,
labels.label,
COUNT(*) AS cnt
FROM google_gmail_emails mails
INNER JOIN google_gmail_labels labels ON mails.id = labels.email_id
GROUP BY mails.to_user,
labels.label
Notice that we use the COUNT instead of the SUM function, as COUNT ignores null values. If we were to use SUM, we would get a blank output for any grouped values that include a null. This required join can then be used as the table we SELECT from, and we can separately make the divisions according to the individual labels. We want the numbers from each individual label, which from some basic exploring or general familiarity with Gmail we know are "Promotion", "Social", and "Shopping". From here, we can put together individual COUNTS for each of the different labels, which would require an additional outer GROUP similar to the above. We will use some pseudocode for readability before we fully incorporate the above code:
SELECT
to_user,
SUM(CASE
WHEN label = 'Promotion' THEN cnt
ELSE 0
END) AS promotion_count,
SUM(CASE
WHEN label = 'Social' THEN cnt
ELSE 0
END) AS social_count,
SUM(CASE
WHEN label = 'Shopping' THEN cnt
ELSE 0
END) AS shopping_count
FROM (CODE BLOCK)
GROUP BY to_user
ORDER BY to_user
And finally, we write in our initial joined table.
SELECT
to_user,
SUM(CASE
WHEN label = 'Promotion' THEN cnt
ELSE 0
END) AS promotion_count,
SUM(CASE
WHEN label = 'Social' THEN cnt
ELSE 0
END) AS social_count,
SUM(CASE
WHEN label = 'Shopping' THEN cnt
ELSE 0
END) AS shopping_count
FROM (SELECT mails.to_user,
labels.label,
COUNT(*) AS cnt
FROM google_gmail_emails mails
INNER JOIN google_gmail_labels labels ON mails.id = labels.email_id
GROUP BY mails.to_user,
labels.label)
GROUP BY to_user
ORDER BY to_user
There we have it!
Activity Rank
Check out our Ultimate Guide to Become a Data Scientist at Google. We also talk about the broader interview process in our Google Data Scientist Interview Guide
We've also covered other SQL questions asked at popular companies in another blog post Advanced SQL Interview Questions.
Final reminders
Now that we've gone over a few data science SQL interview questions by individual FAANG companies let's briefly go over best practices for working on your SQL capabilities in preparation for your big interviews. It's vital to build up your SQL skills, as they can be important for any role that even tangentially handles data. The ability to read and understand other people's code or even pull your own data is immeasurably powerful.
A good first step to building up those SQL abilities is being here! Getting practical experience with SQL can be immensely helpful, as you get practice working with SQL beyond the theoretical framework you built from whatever classroom or boot camp equivalent you may have spawned from.
As you look at practicing SQL data science interview questions, start off by trying to build out solutions without running the code runner. Spend a good 15 minutes or so thinking through the raw code you've written, and do your best to assure that there aren't any syntax errors or bugs. You can even enforce the process by physically writing down your code on paper instead of working through the code editor. Take a quick look at the hints if you get stuck.
While in a practical work environment, you can generally rerun any code you want to test over and over to solve each error that may come up. Working in this way is good practice to truly solidify your SQL knowledge by training yourself to be able to get the most well-rounded first try answer. Furthermore, when working on these data science SQL interview questions in an interview setting, it's important to get a good, solid answer on your first try. While it doesn't need to be 100% perfect, having your code littered with small syntax errors doesn't make for a good impression with your interviewer.
It's also important to note that in extreme cases, rerunning the code over and over may not be practical either, such as in cases when the database that you are working with is so large that each query takes a significant amount of time. Having a large query take a few hours to finish running, only to realize you accidentally did an incorrect join, which can result in a lot of wasted time.
Next up, after you are as sure as you can reasonably be in the short term-frame you are working with that there are no more errors in what you've written, do the actual run in the code editor. Look at any errors or issues that pop up that you may have missed in the previous step and make the necessary changes. It's also a good practice to take notes on what you miss, and as you work through multiple practice SQL interview questions, see if there are patterns that reveal any gaps in your knowledge, problematic habits, or common issues that you may have.
Finally, check your work against the other available solutions, which you can use to compare approaches and learn about potential optimizations. First off would be the official solution, where you should ask yourself a few questions.
- Are there any ways you could have optimized your code further?
- Are there any inefficiencies in your code?
- How are alternative approaches to the problem different from yours? Are they better methods that you can learn things from?
Furthermore, read through the discussion threads of each problem to identify any topics related to the question, such as edge cases or alternative approaches, or even similar questions to the given scenario.
From there on out, you're well set to ace any SQL question that comes up in a data science interview.
Original. Reposted with permission.
Bio: Nathan Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies.
Related: