Feature Stores for Real-time AI & Machine Learning
Real-time AI/ML is on the rise and feature stores are key to successfully deploying them. Read on to see how the choice of online store and the feature store architecture play important roles in determining its performance and cost.
Real-time AI/ML use cases such as fraud prevention and recommendations are on the rise, and feature stores play a key role in deploying them successfully to production. According to popular open source feature store Feast, one of the most common questions users ask in their community Slack is: how scalable / performant is Feast? This is because the most important characteristic of a feature store for real-time AI/ML is the feature serving speed from the online store to the ML model for online predictions or scoring. Successful feature stores can meet stringent latency requirements (measured in milliseconds), consistently (think p99) and at scale (up to 100Ks of queries per second and even million of queries per second, and with gigabytes to terabytes sized datasets) while at the same time maintaining a low total cost of ownership and high accuracy.
As we will see in this post, the choice of online feature store as well as the architecture of the feature store play important roles in determining how performant and cost effective it is. It’s no wonder then that often companies, before choosing their online feature store, perform thorough benchmarking to see which choice of architecture or online feature store is the most performant and cost effective. In this post we will review architectures and benchmarks from both DIY feature stores built by companies successfully deploying real-time AI/ML use cases and of open source and commercial feature stores. Let’s begin.
1. Open Source Feast
Let’s first have a look at benchmarking data and then the data architecture of the Feast open source feature store. Feast recently did a benchmark to compare its feature serving latency when using different online stores (Redis vs. Google Cloud DataStore vs. AWS DynamoDB) and also comparing the speed when using different mechanisms for extracting the features (e.g. Java gRPC server, Python HTTP server, lambda function etc.). You can find the full benchmark setup and its results in this blog post, but the bottom line is that Feast found that it was by far the most performant using the Java gRPC server and with Redis as the online store.
Source:Video
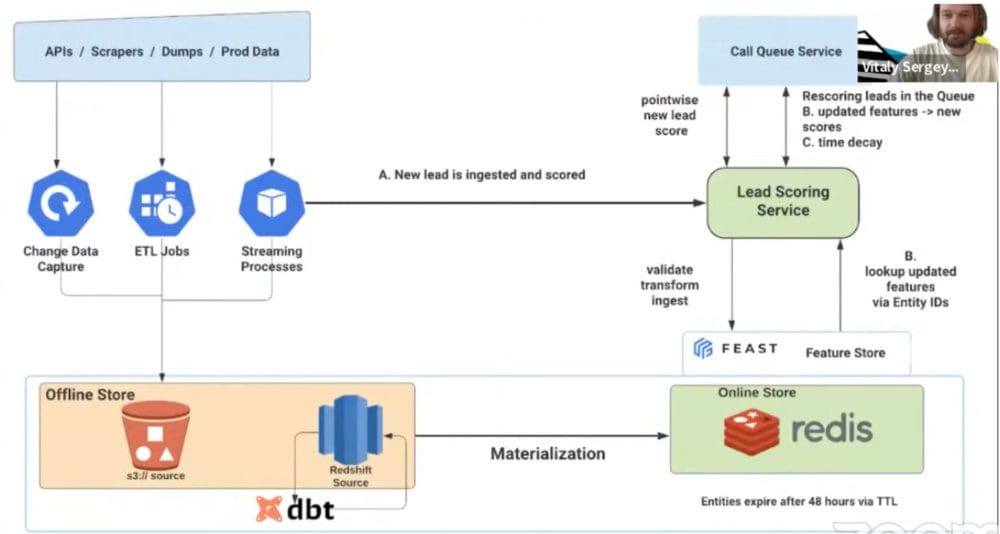
In the diagram above you can see an example of how the popular online mortgage company Better.com implemented their lead scoring ranking system using the open-source Feast feature store, as presented by Vitaly Sergey, Senior Software Engineer at Better.com: The features are materialized from the offline stores (S3, Snowflake and Redshift) to the online store (Redis). In addition to that, features are also ingested into the online store from streaming sources (Kafka topics). Feast recently added support for streaming data sources (in addition to batch data sources) which is currently supported only for Redis. Supporting streaming data sources is very important for real-time AI/ML use cases as these use cases rely on fresh live data. As an example, in a lead scoring use case of Better, new leads are being ingested continuously throughout the day, the features come from many different sources, and both the entities (the leads) and the features used to score them, get updated all the time, and leads get ranked and re-ranked. As soon as there is a new lead it is ingested and scored by the model, and at the same time it’s ingested into the online store, as we may want to re-rank it soon after. For Better.com leads expire after 48 hours, and this is implemented in the Redis online store by simply setting TTL (time to live) to 48 hours, to expire the entity (lead) and associate feature vectors after 48 hours. So the feature store cleans itself automatically and there are no stale entities or features taking up valuable online storage.
Another interesting implementation of Feast is for the Microsoft Azure Feature Store. You can have a look at its architecture, it runs on the Azure cloud optimized for low latency real-time AI/ML use cases, supporting both batch and streaming sources, as well as integrated into the Azure Data & AI ecosystem. The features are ingested in the online store from both batch sources (Azure Synapse Serverless SQL, Azure Storage / ADLS) and from streaming sources (Azure Event Hub). If you are already deployed on Azure or familiar with the Azure ecosystem then this feature store may be the right one for you. For the online store it uses the Azure Cache for Redis, and with Enterprise Tiers of Azure Redis, it includes active geo-replication to create globally distributed caches with up to 99.999% availability. In addition, further cost reductions can be achieved by using the Enterprise Flash tier to run Redis on a tiered memory architecture which uses both in-memory (DRAM) and Flash memory (NVMe or SSD) to store data.
2. Wix DIY Feature Store - The Cornerstone of MLOps Platform
Below is a different feature store architecture for implementing real-time AI/ML use cases. It is the architecture of the feature store of the popular website building platform Wix . The feature store is used for real-time use cases as Recommendations, Churn & Premium Predictions, Ranking and Spam Classifier, and is considered to be the cornerstone of its MLOps platform. Wix serves over 200M registered users of which only a small fraction are active users’ at any given time. This had a big influence on the way the feature store was implemented. Let’s take a look at it. The information below is based on a TechTalk presentation that was delivered by Ran Romano when he headed ML Engineering at Wix. Over 90% of the data stored in the Wix feature store are clickstreams and the ML models are triggered per website or per user. Ran explains that for the real-time use cases latency is a big issue, and that for some of their production use cases they need to extract the feature vectors within milliseconds.
Source:Video
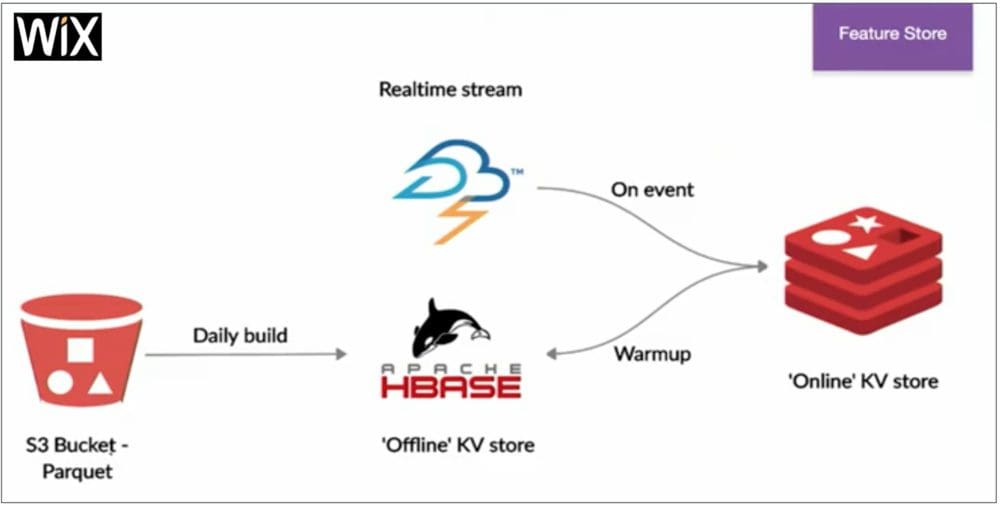
The raw data is stored in Parquet files on AWS in an S3 bucket, and is partitioned by business units (e.g. ‘editors’, ‘restaurants’ , ‘bookings’ etc.) and then by date. It is part of the Wix data platform used by its data analysts which predated Wix ML Platform by years. In a daily build batch process using Spark SQL (which takes minutes to hours) all the users history features are extracted from S3, pivoted and aggregated by user and ingested into the offline store (Apache Hbase). This provides a much faster, by ‘user’, lookup to its users history. Once the system detects that a user is currently active, a ‘Warmup’ process is triggered and the features of that user are loaded into the online store (Redis) which is much smaller than the offline store since it holds only the user history of the active users. This ‘Warmup’ process can take several seconds. And finally, features in the online feature store are continuously updated using fresh live ‘real-time” data directly from the streaming sources per each event coming from the user (using Apache Storm).
This type of architecture has a lower ratio of writes to reads compared to the Feast architecture, is very efficient in terms of materialization and online storage since it only stores features for active users in the online store rather than those for all users. And because in Wix active users are a small fraction of all registered users this represents a huge saving. However, this comes at a price. While retrieving features from the online store is very fast, within milliseconds, it’s only if the features already exist in the online store. Due to race conditions, it could be that for some of the users, because the Warm-up process takes several seconds, it won’t be fast enough to load the relevant features as the user becomes active, and so the scoring or prediction for that user will simply fail. This is OK as long as the use case is not part of the critical flow or for mission critical use cases such as approving transactions or preventing fraud. This type of architecture is also very specific to Wix, in which only a small fraction of users are active users at any given time.
3. Commercial Feature Store Tecton
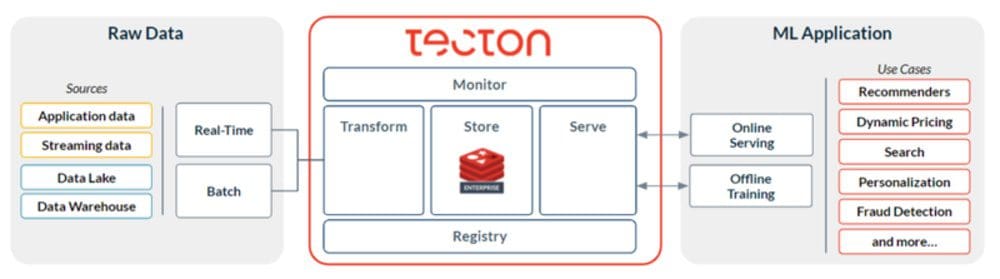
Let’s look now at the architecture of the commercial enterprise feature store Tecton. As we can see in the diagram below, in addition to batch data sources and streaming data sources, Tecton also supports ‘out-of-the-box’ Real-time data sources, also called ‘real-time features’ or ‘real-time’ transformations. Real-time features are features that can be calculated only at the inference request, for example the difference between the size of the suspected transaction and the last transaction size. So if in the case of Better.com with open source Feast above, Better.com developed on its own the support for real-time features, with the Tecton feature store this easier to implement as it’s already natively supported by the feature store.
Like with Feast and the Wix Feature Stores, Tecton also defines the features in the registry so that the logical definition is defined once for both offline and online stores, significantly reducing training-serving skew to ensure high accuracy of the ML model also in production.
Source: blog post
With respect to choice of offline store, online store and benchmarking: For the offline feature store Tecton supports S3, and for the online store Tecton now offers their customers a choice between DynamoDB and Redis Enterprise Cloud. In a recent presentation Tecton CTO Kevin Stumpf provided tips on how to choose your online feature store, based on benchmarks the company recently performed. In addition to benchmarking latency and throughput, Tecton also benchmarked the cost of the online store. Why is this important? For high throughput or low latency use cases, the cost of the online store can be a large and a significant portion of the total cost of ownership of the whole MLOps platform, so any cost savings can be substantial.
The bottom line of Tecton’s benchmarking is that for high throughput use cases typical for Tectons’s users, Redis Enterprise was 3x faster and at the same time 14x less expensive compared to DynamoDB.
So what’s the catch you may ask? There are cases, for example, if you have only one use case, and it doesn’t have high or consistent throughput, and it doesn’t have any strict latency requirements, then you could go with DynamoDB. You can find the full details and the results of Tecton’s benchmarks here.
4. Lightricks using Commercial Feature Store Qwak
Below is another example of a feature store architecture, this one used by Lightricks based on the commercial feature store Qwak. Lightricks is a unicorn company that develops video and image editing mobile apps, known particularly for its selfie-editing app, Facetune. It uses the feature store for its recommendation system.
Source: AIGuild video
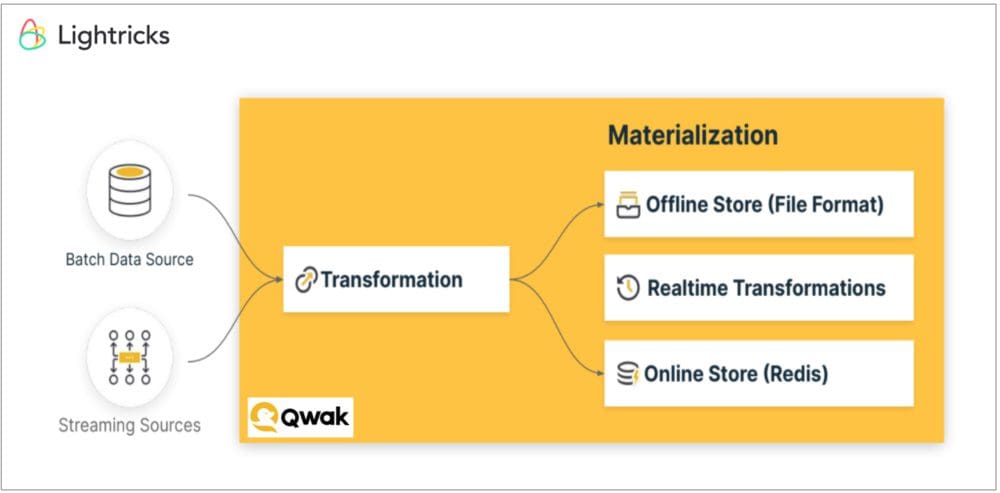
As shown in the diagram above, like Tecton, also Qwak feature store supports out-of-the-box three types of features sources - batch, streaming and real-time features.
It is important to note that with the Qwak feature store, the materialization of features into the feature stores is done directly from the raw data sources for both the offline store (using Parquet files on S3), and the online store (using Redis). This is different compared with the feature store examples from Wix, Feast or Tecton in which the materialization to the online store is done from the offline store to the online store for the batch sources. Why is this important? This has the advantage that not only the transformation logic of a feature is unified across training and serving flows (as with the feature stores of Feast, Wix and Tecton above), but also the actual transformation or feature computation is done uniformly, further decreasing training-serving skew. Having a unified data pipeline for offline & online directly from raw data has the potential to ensure even higher accuracy during production. You can find more information on Qwak's feature store architecture and components in this presentation.
Summary
In this post we reviewed key highlights of benchmarks and architectures of several Feature Stores for real-time AI/ML. The first one being Open Source Feast, the second DIY Wix Feature Store, the third from Tecton and the fourth by Qwak. We also reviewed the highlights of some of the benchmarks these companies performed to see which online store is the most performant and the most cost effective, as well as which mechanism or feature server to use for extracting the features from the online store. We saw that there are significant differences in the performance and cost of feature stores, depending on the architecture, supported type of features and components selected.
Nava Levy is a Developer Advocate for Data Science and MLOps at Redis. She started her career in tech with an R&D Unit in the IDF and later had the good fortune to work with and champion Cloud, Big Data, and DL/ML/AI technologies just as the wave of each of these was starting. Nava is also a mentor at the MassChallenge accelerator and the founder of LerGO—a cloud-based EdTech venture. In her free time she enjoys cycling, 4-ball juggling, and reading fantasy and sci-fi books.