Hidden Technical Debts Every AI Practitioner Should be Aware of
Coming to think of technical debt in ML systems leads to the additional overhead of ML-related issues on top of typical software engineering issues.
Introduction
Building your first machine learning model has become fairly quick now with the advent of new packages and libraries. As rosy as it may seem at first, it is accumulating hidden technical debt in terms of maintaining such machine learning systems.
But let's first understand what a technical debt is:
“In software development, technical debt (also known as design debt or code debt) is the implied cost of additional rework caused by choosing an easy (limited) solution now instead of using a better approach that would take longer.” – Wikipedia
As per Ward Cunningham, technical debt is the long-term costs incurred by moving quickly in software engineering. It might look like the right thing to do at one point in time while moving code to production but it needs to be attended to at a later stage, in terms of writing comprehensive unit tests, removing redundant and unused code, documentation, code refactoring, etc. Teams working on such tasks are not delivering new functionality, but attending to accruing debt in a timely fashion to reduce the scope of errors and promote easy code maintenance.
Technical Debt from a Machine Learning Purview
Coming to think of technical debt in ML systems leads to the additional overhead of ML-related issues on top of typical software engineering issues.
A large part of ML technical debt is attributed to system-level interactions and interfaces.
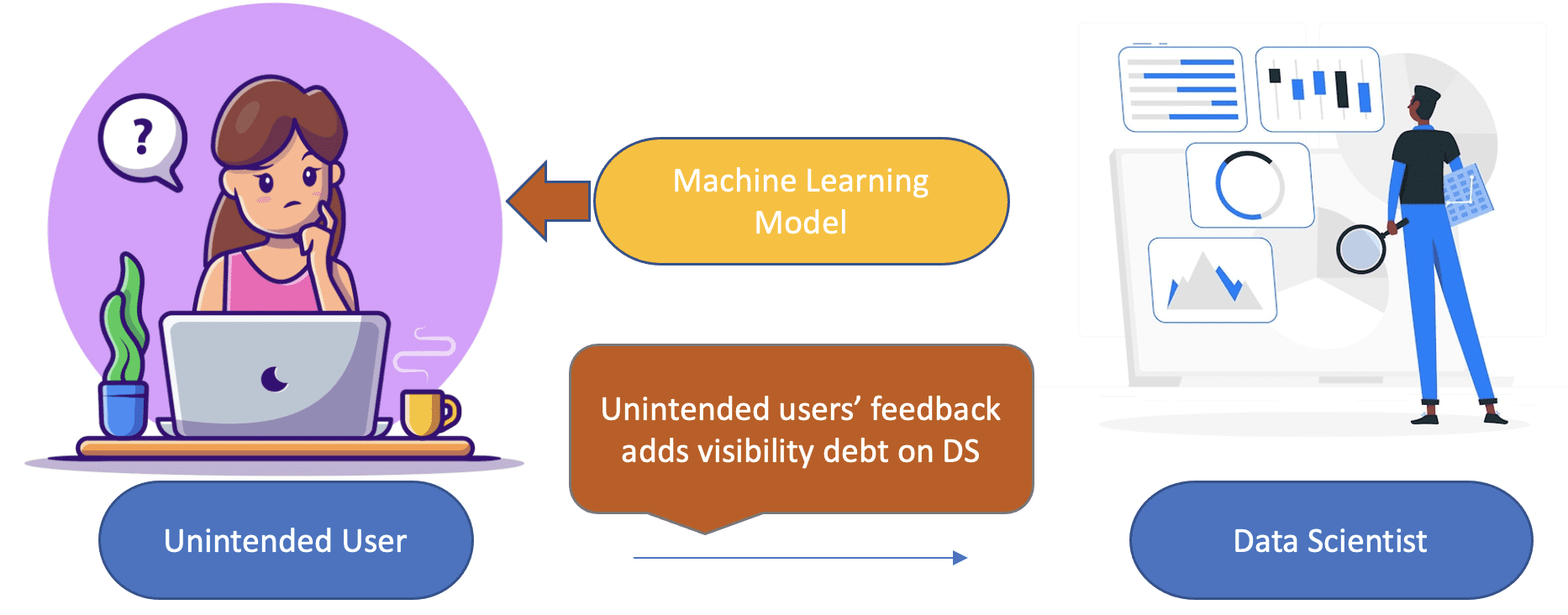
Know your consumers
Identifying the consumers of machine learning prediction is critical to gauge the impact of your new version of the model. The feedback of the model predictions set the ground for model revision and incorporates the potential impact on its users.
Coffee work vector created by catalyststuff; Web analytics vector created by storyset
To eliminate the risks arising from the poorly framed or poorly understood requirements from the unintended users, it's important to document and sign off the declared set of users and decouple the hidden feedback loops and expectations from a wide set of users.
No change is small
A machine learning system is best built when all the attributes impacting the target variables are present during model training time. Essentially, a model gets to see what a human expert would see to assess the outcome. The life of a data scientist would be much simpler if all the variables are independent, but that's not how a real-life event is governed. Any single change in a variable not only changes its distribution but also impacts the feature importance and weights of all the input (or independent) variables together. This is owed to the interaction property i.e. change in variable impacts the joint distribution of all the variables.
Similar effects can be observed upon adding or deleting a variable. The mixing and entanglement of the signals intricately change the entire model learning process.
Note that this is not limited to any variable addition or removal, primarily any change in hyperparameters, data curation, labeling process, threshold selection, or a sampling process that can lead to an effect called Changing Anything Changes Everything.
Relevant data and changing data
The input data distribution may change over time and would need an assessment of its implications on the model outcome. That is where data versioning is important so that qualitative and quantitative changes in the data are well captured and documented. This however leads to an added cost of being vigilant of data freshness and maintaining multiple versions.
A lot of data scientists add a lot of packages or make temporary changes to the code to quickly adapt the latest version of the running code to carry out an experiment or analysis. The problem arises when they forget to keep the code relevant and remove the unused or unnecessary code blocks that act as an impediment for later changes in the code when needed. This is frequently the case when multiple developers are collaborating on a single script and keep adding the changes without eliminating the redundancy or irrelevancy under the fear that they might end up breaking someone else's code or that it will incur the additional time to test the backward-compatible changes.
When to add vs not trade-off
Every data scientist needs to accept the fact that “more is not the merrier” when it comes to adding features. Under the presumption that every single feature is important for model learning unless it leads to exorbitant data dimensions, the data scientists do not consider the cost of maintaining the features with residual value. Additionally, if a feature is later declared not important, they prefer to not take the pain of changing the model pipeline and hence, continue carrying the legacy features engineered during the early model development stage.
This still looks fairly simple to handle until all features are directly plugged into the model from a single table. The complexity increases manifold when the attributes are sourced from multiple data streams and undergo a multitude of joins and transformations leading to additional intermediate steps. Managing such pipelines, and detecting and debugging such systems become a deterrent for the team to continue developing innovative solutions.
Cascading effect of limitations
Managing a single model is a tough battle in itself, hence a lot of organizations are inclined toward building one generalized model. As much as it appears to be a winning game, it's a double-edged sword.

Coffee work vector created by catalyststuff
Is a generalized model performing well for all the use cases? If not then it's often a sought-after choice to build a correction model layer on top of the base model to better serve the slightly different but similar problem statement. In such cases, the revised model takes the base model as input that adds a layer of dependency and an extra set of analysis and monitoring of the revised model.
Summary
In the article, we discussed the costs and benefits of handling hidden technical debt in machine learning systems. The myopic view of prioritizing the release of new model versions or test running the pipeline end to end will move things to production quickly. But it continues to add the hidden costs that slow down the speed of the teams to innovate in the long run.
The authors of the research paper share some thoughtful questions for AI practitioners to ponder while considering the hidden debts’ implications:
- How easy it is to test a new algorithmic approach at full scale
- How can we measure the impact of each change? Have we established the checkpoints in the pipeline to capture and attribute the diagnostic factors?
- Is the improvement by bringing one change in the system leading to a negative impact on the rest of the system?
- How fast and easy it is for the new members to understand the nuances and complexities of the entire pipeline?
References
Vidhi Chugh is an award-winning AI/ML innovation leader and an AI Ethicist. She works at the intersection of data science, product, and research to deliver business value and insights. She is an advocate for data-centric science and a leading expert in data governance with a vision to build trustworthy AI solutions.