30 Years of Data Science: A Review From a Data Science Practitioner
A review from a data science practitioner.

Image by Editor
30 years of KDnuggets and 30 years of data science. More or less 30 years of my professional life. One of the privileges that comes with working in the same field for a long time - aka experience - is the chance to write about its evolution, as a direct eye witness.
The Algorithms
I started working at the beginning of the 90s on what was then called Artificial Intelligence, referring to a new paradigm that was self-learning, mimicking organizations of nervous cells, and that did not require any statistical hypothesis to be verified: yes, neural networks! An efficient usage of the Back-Propagation algorithm had been published just a few years earlier [1], solving the problem of training hidden layers in multilayer neural networks, enabling armies of enthusiastic students to tackle new solutions to a number of old use cases. Nothing could have stopped us … just the machine power.
Training a multilayer neural network requires quite some computational power, especially if the number of network parameters is high and the dataset is large. Computational power, that the machines at the time did not have. Theoretical frameworks were developed, like Back-Propagation Through Time (BPTT) in 1988 [2] for time series or Long Short Term Memories (LSTM) [3] in 1997 for selective memory learning. However, computational power remained an issue and neural networks were parked by most data analytics practitioners, waiting for better times.
In the meantime, leaner and often equally performing algorithms appeared. Decision trees in the form of C4.5 [4] became popular in 1993, even though in the CART [5] form had already been around since 1984. Decision trees were lighter to train, more intuitive to understand, and often performed well enough on the datasets of the time. Soon, we also learned to combine many decision trees together as a forest [6], in the random forest algorithm, or as a cascade [7] [8], in the gradient boosted trees algorithm. Even though those models are quite large, that is with a large number of parameters to train, they were still manageable in a reasonable time. Especially the gradient boosted trees, with its cascade of trees trained in sequence, diluted the required computational power over time, making it a very affordable and very successful algorithm for data science.
Till the end of the 90s, all datasets were classic datasets of reasonable size: customer data, patient data, transactions, chemistry data, and so on. Basically, classic business operations data. With the expansion of social media, ecommerce, and streaming platforms, data started to grow at a much faster pace, posing completely new challenges. First of all, the challenge of storage and fast access for such large amounts of structured and unstructured data. Secondly, the need for faster algorithms for their analysis. Big data platforms took care of storage and fast access. Traditional relational databases hosting structured data left space to new data lakes hosting all kinds of data. In addition, the expansion of ecommerce businesses propelled the popularity of recommendation engines. Either used for market basket analysis or for video streaming recommendations, two of such algorithms became commonly used: the apriori algorithm [9] and the collaborative filtering algorithm [10].
In the meantime, performance of computer hardware improved reaching unimaginable speed and … we are back to the neural networks. GPUs started being used as accelerators for the execution of specific operations in neural network training, allowing for more and more complex neural algorithms and neural architectures to be created, trained, and deployed. This second youth of neural networks took on the name of deep learning [11] [12]. The term Artificial Intelligence (AI) started resurfacing.
A side branch of deep learning, generative AI [13], focused on generating new data: numbers, texts, images, and even music. Models and datasets kept growing in size and complexity to attain the generation of more realistic images, texts, and human-machine interactions.
New models and new data were quickly substituted by new models and new data in a continuous cycle. It became more and more an engineering problem rather than a data science problem. Recently, due to an admirable effort in data and machine learning engineering, automatic frameworks have been developed for continuous data collection, model training, testing, human in the loop actions, and finally deployment of very large machine learning models. All this engineering infrastructure is at the basis of the current Large Language Models (LLMs), trained to provide answers to a variety of problems while simulating a human to human interaction.
The Life Cycle
More than around the algorithms, the biggest change in data science in the last years, in my opinion, has taken place in the underlying infrastructure: from frequent data acquisition to continuous smooth retraining and redeployment of models. That is, there has been a shift in data science from a research discipline into an engineering effort.
The life cycle of a machine learning model has changed from a single cycle of pure creation, training, testing, and deployment, like CRISP-DM [14] and other similar paradigms, to a double cycle covering creation on one side and productionisation - deployment, validation, consumption, and maintenance - on the other side [15].
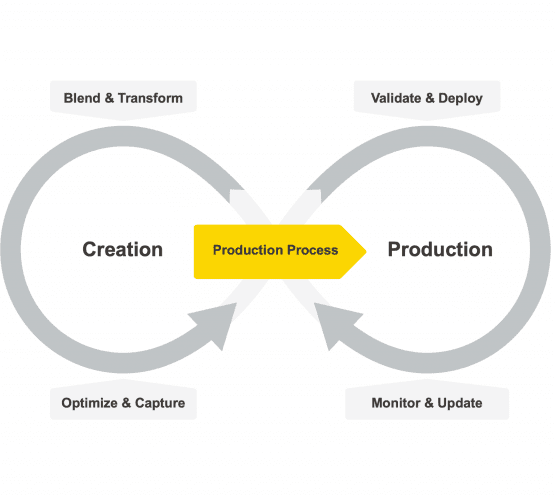
Fig. 1 The life cycle of a machine learning model
The Tools
Consequently, data science tools had to adapt. They had to start supporting not only the creation phase but also the productionization phase of a machine learning model. There had to be two products or two separate parts within the same product: one to support the user in the creation and training of a data science model and one to allow for a smooth and error-free productionisation of the final result. While the creation part is still an exercise of the intellect, the productionisation part is a structured repetitive task.
Obviously for the creation phase, data scientists need a platform with extensive coverage of machine learning algorithms, from the basic ones to the most advanced and sophisticated ones. You never know which algorithm you will need to solve which problem. Of course, the most powerful models have a higher chance of success, that comes at the price of a higher risk of overfitting and slower execution. Data scientists in the end are like artisans who need a box full of different tools for the many challenges of their work.
Low code based platforms have also gained popularity, since low code enables programmers and even non-programmers to create and quickly update all sorts of data science applications.
As an exercise of the intellect, the creation of machine learning models should be accessible to everybody. This is why, though not strictly necessary, an open source platform for data science would be desirable. Open-source allows free access to data operations and machine learning algorithms to all aspiring data scientists and at the same time allows the community to investigate and contribute to the source code.
On the other side of the cycle, productionization requires a platform that provides a reliable IT framework for deployment, execution, and monitoring of the ready-to-go data science application.
Conclusion
Summarizing 30 years of data science evolution in less than 2000 words is of course impossible. In addition, I quoted the most popular publications at the time, even though they might not have been the absolute first ones on the topic. I apologize already for the many algorithms that played an important role in this process and that I did not mention here. Nevertheless, I hope that this short summary gives you a deeper understanding of where and why we are now in the space of data science 30 years later!
Bibliography
[1] Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. (1986). “Learning representations by back-propagating errors”. Nature, 323, p. 533-536.
[2] Werbos, P.J. (1988). "Generalization of backpropagation with application to a recurrent gas market model". Neural Networks. 1 (4): 339–356. doi:10.1016/0893-6080(88)90007
[3] Hochreiter, S.; Schmidhuber, J. (1997). "Long Short-Term Memory". Neural Computation. 9 (8): 1735–1780.
[4] Quinlan, J. R. (1993). “C4.5: Programs for Machine Learning” Morgan Kaufmann Publishers.
[5] Breiman, L. ; Friedman, J.; Stone, C.J.; Olshen, R.A. (1984) “Classification and Regression Trees”, Routledge. https://doi.org/10.1201/9781315139470
[6] Ho, T.K. (1995). Random Decision Forests. Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, 14–16 August 1995. pp. 278–282
[7] Friedman, J. H. (1999). "Greedy Function Approximation: A Gradient Boosting Machine, Reitz Lecture
[8] Mason, L.; Baxter, J.; Bartlett, P. L.; Frean, Marcus (1999). "Boosting Algorithms as Gradient Descent". In S.A. Solla and T.K. Leen and K. Müller (ed.). Advances in Neural Information Processing Systems 12. MIT Press. pp. 512–518
[9] Agrawal, R.; Srikant, R (1994) Fast algorithms for mining association rules. Proceedings of the 20th International Conference on Very Large Data Bases, VLDB, pages 487-499, Santiago, Chile, September 1994.
[10] Breese, J.S.; Heckerman, D,; Kadie C. (1998) “Empirical Analysis of Predictive Algorithms for Collaborative Filtering”, Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence (UAI1998)
[11] Ciresan, D.; Meier, U.; Schmidhuber, J. (2012). "Multi-column deep neural networks for image classification". 2012 IEEE Conference on Computer Vision and Pattern Recognition. pp. 3642–3649. arXiv:1202.2745. doi:10.1109/cvpr.2012.6248110. ISBN 978-1-4673-1228-8. S2CID 2161592.
[12] Krizhevsky, A.; Sutskever, I.; Hinton, G. (2012). "ImageNet Classification with Deep Convolutional Neural Networks". NIPS 2012: Neural Information Processing Systems, Lake Tahoe, Nevada.
[13] Hinton, G.E.; Osindero, S.; Teh, Y.W. (2006) ”A Fast Learning Algorithm for Deep Belief Nets”. Neural Comput 2006; 18 (7): 1527–1554. doi: https://doi.org/10.1162/neco.2006.18.7.1527
[14] Wirth, R.; Jochen, H.. (2000) “CRISP-DM: Towards a Standard Process Model for Data Mining.” Proceedings of the 4th international conference on the practical applications of knowledge discovery and data mining (4), pp. 29–39.
[15] Berthold, R.M. (2021) “How to move data science into production”, KNIME Blog
Rosaria Silipo is not only an expert in data mining, machine learning, reporting, and data warehousing, she has become a recognized expert on the KNIME data mining engine, about which she has published three books: KNIME Beginner’s Luck, The KNIME Cookbook, and The KNIME Booklet for SAS Users. Previously Rosaria worked as a freelance data analyst for many companies throughout Europe. She has also led the SAS development group at Viseca (Zürich), implemented the speech-to-text and text-to-speech interfaces in C# at Spoken Translation (Berkeley, California), and developed a number of speech recognition engines in different languages at Nuance Communications (Menlo Park, California). Rosaria gained her doctorate in biomedical engineering in 1996 from the University of Florence, Italy.