Ten Key Lessons of Implementing Recommendation Systems in Business
We've been long working on improving the user experience in UGC products with machine learning. Following this article's advice, you will avoid a lot of mistakes when creating a recommendation system, and it will help to build a really good product.
1. Define a Goal that Really Contributes to the Business Tasks
The global task of the recommendation system is to select a shortlist of content from a large catalog that is most suitable for a particular user. The content itself can be different — from products in the online store and articles to banking services. FunCorp product team works with the most interesting kind of content — we recommend memes.
To do this, we rely on the history of the user's interaction with the service. But “good recommendations” from a user perspective and from a business perspective are not always the same thing. For example, we found that increasing the number of likes that a user clicks thanks to more accurate recommendations does not affect retention, a metric that is important for our business. So we started focusing on models that optimize time spent in the app instead of likes.
That's why it's so important to focus on the most important goal for your business. Goals can be different, for example:
- user retention,
- increased revenue,
- cost reduction,
- and so on.
The recommendation system will surely allow you to improve the user experience, and the user will take the targeted action faster and/or more often. What remains to be done is to make sure that you reach your business goals at the same time. Win-win! In our case, we saw a 25% increase in the relative number of smiles (likes) and an almost 40% increase in the viewing depth as a result of implementing a recommendation system in our feed.
Main goal in iFunny is to increase retention and you can see that sometimes we run experiments with a very destructive influence on retention.
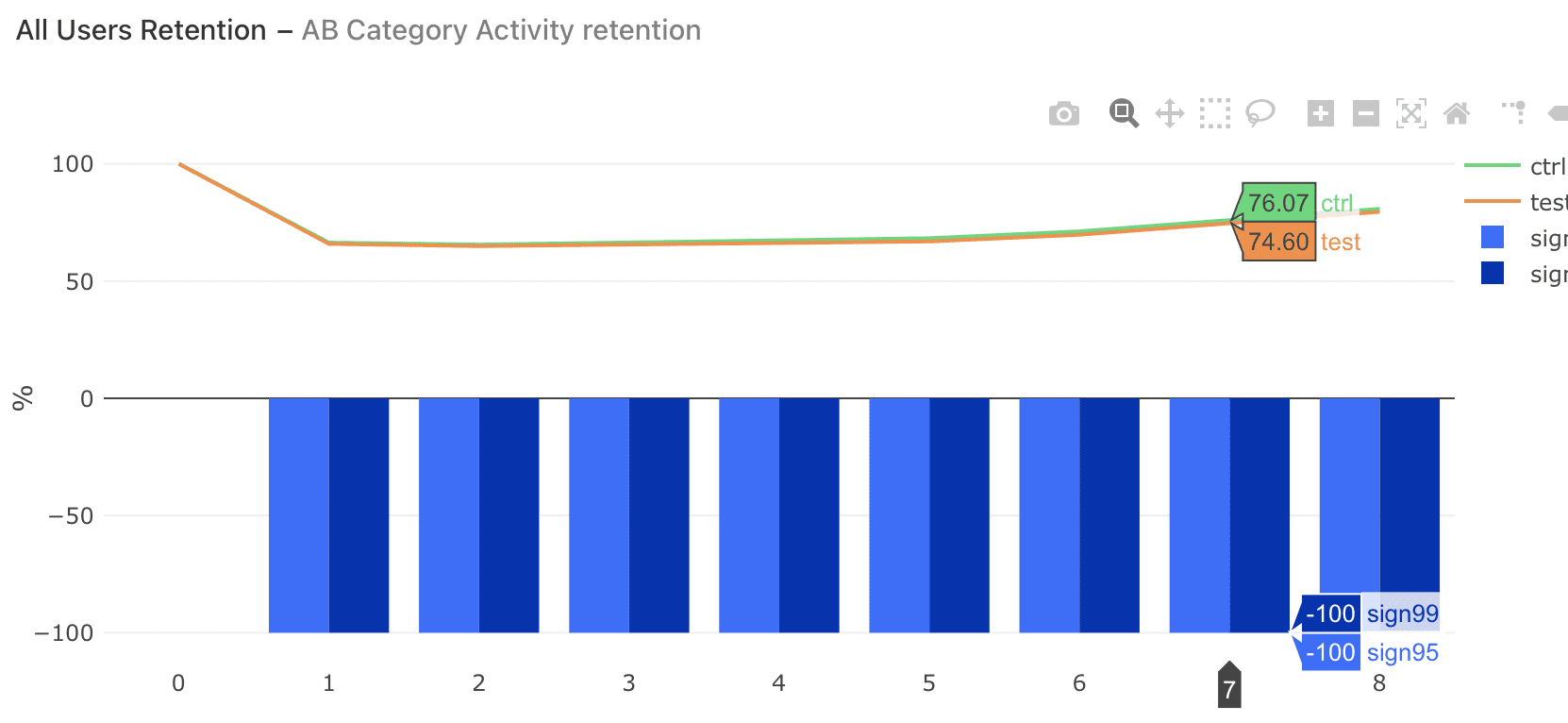
2. Find the Optimal User Touchpoint in the Product
When you've decided on the global goal, you need to figure out what is the best way to display recommendations:
- in the feed — this is relevant for news sites or entertainment apps like our iFunny,
- push notifications,
- email newsletter,
- the section with personalized offers in a personal account,
- or other sections on the site/application.
Many factors influence the choice of touchpoint — for example, the share of DAU in this point (for some users, push notifications may be disabled) or the complexity of integration with ML microservice.
In our case, an ineffective choice might look like this. The iFunny app has an Explore section where we collect a selection of the best memes of the week. One can collect such selections with ML, but only small amount of DAUs go to this section.
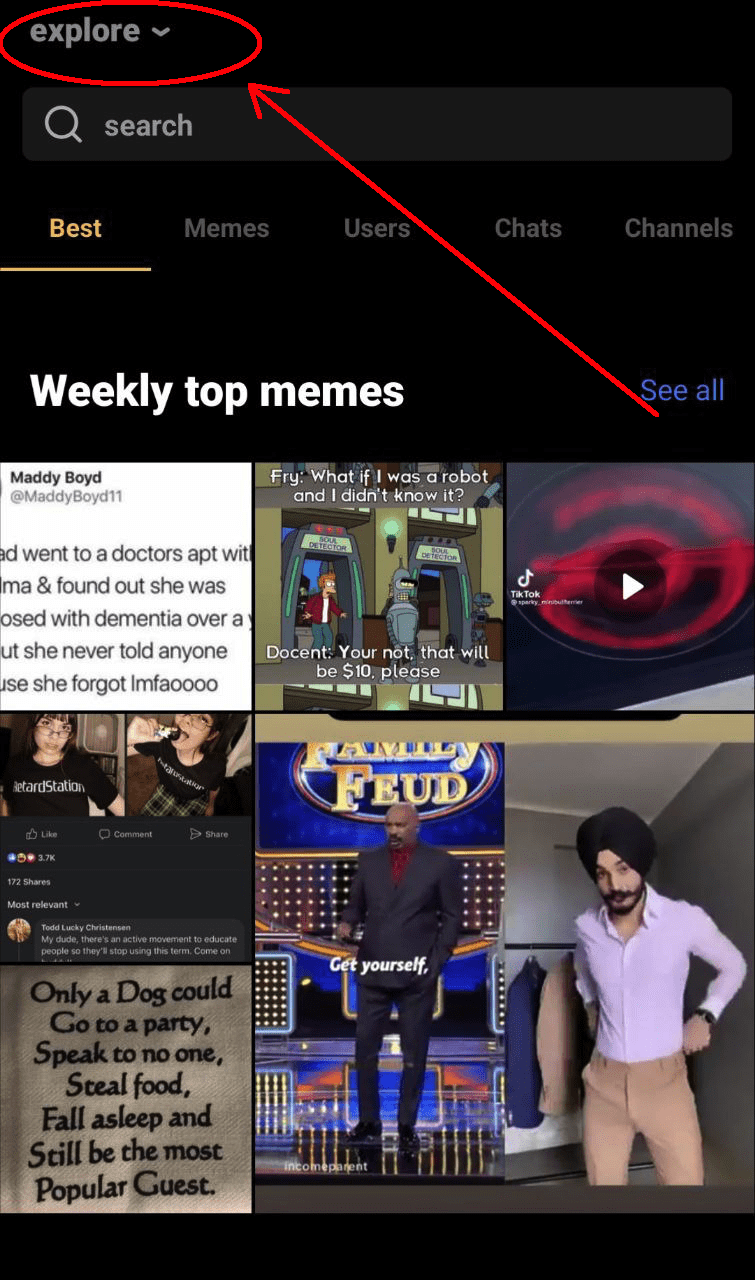
Using ML at this point is impractical.
The main rule here is to integrate ML where it will make the biggest increase in business metrics. Therefore, in the case of FunCorp we, first of all, decided to implement ML in the feed, because it is seen by the maximum number of users. And secondly, we started to create the recommendation system for the push notifications — because there is a noticeable, but still a smaller volume of the audience interacting with them.
3. Collect As Much Diverse Feedback From Users As Possible
In our case, feedback is the actions a user can take to demonstrate how they feel about the content in the app. To build a recommendation system, you need to learn how to collect different types of feedback:
- Explicit — this can be a rating by any scale or a like/dislike.
- And implicit:
- the amount of time a user spends on the content,
- the number of visits to the content page,
- the number of times one shares the content on social networks or sends it to friends.
Feedback should correlate with the business goals of the recommendation system. For example, if the goal is to reduce churn, it is reasonable to add a feedback form and show it to users who unsubscribe from the service.
Here are some important technical points you need to consider:
- Make it possible to expand user feedback channels. For example, in addition to the time spent on the page, you can start collecting user comments and determining their tone. Positive comments will tell you that you need more of this kind of content. And vice versa.
- Keep a history of user feedback for a long time — at least several months. This is necessary for two purposes. First, the more data you have when training the recommendation system model, the better the model will be — you will be able to identify insights in long-term users' behavior. Second, a large amount of historical data will allow us to compare models without running AB tests, in an offline format.
- You need a data quality control system. Real case: when we started collecting statistics on the time of viewing content and training the model using this data, we found out in the process that the data was collected from the iOS platform only. On Android, the feature had not been implemented. That is, we expected personalization to improve, but didn't have data for the whole platform.
Don't forget about the limitations of channels. For example, only 30–40% of users give feedback using likes. And if you build the recommendation system only on likes, then 60–70% of the audience will receive non-personalized dropout. So the more different channels of user feedback you have, the better.
In iFunny we have only 50% of users with explicit feedback, so we need to develop models with implicit feedback to improve our metrics

4. Define Business Metrics
Machine learning experts got used to working with the metrics of ML algorithms: precision, recall, NDCG... But in fact, businesses are not interested in these metrics, other indicators play a role:
- session depth,
- conversion to purchase/view,
- retention,
- average check per user.
So you need to choose the metrics that best fit your key business goals. Here's what you can do:
- Count the various metrics.
- On offline data, find correlations between business metrics and long-term metrics: user retention, revenue growth, etc.
As a result, you get a set of business metrics to grow in AB tests.
5. Segment Your Users
From a business perspective, the audience of the site can be very heterogeneous in various ways (such indicators are sometimes called slices):
- socio-demographic characteristics,
- activity on the service (number of feedback, frequency of visits),
- geopositions,
- etc.
Very often your models will have different effects on different audience segments — for example, showing metrics growth on new users and no growth on older users.
The reporting system should provide the ability to calculate metrics in different user sections, to notice the improvement (or deterioration) of metrics in each particular segment.
For example, iFunny has two large segments:
- “high activity" — users visit the app frequently and watch a lot of content,
- “low activity” — users visit the app rarely.
We used to count metrics overall, but when we separated these users in reports, we saw that model changes affect them differently. Sometimes there is growth only in the high activity segment — and when you count metrics without segmentation, you might not notice it.
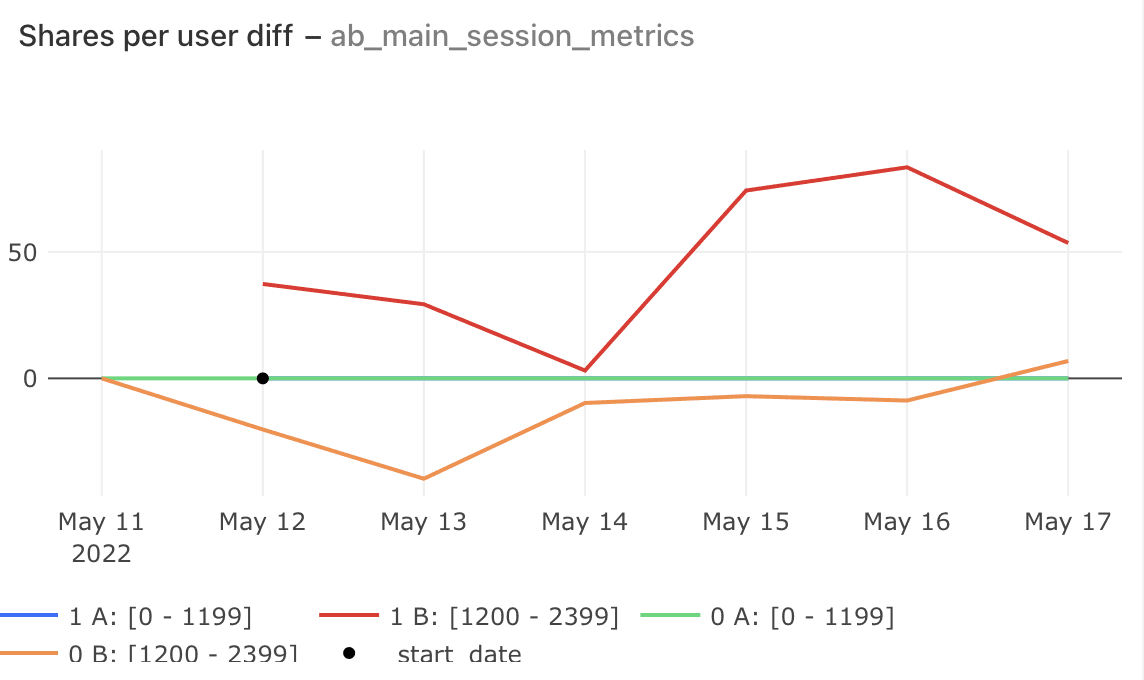
6. Determine the Right Offline Metrics
When the feedback data is collected and the business metrics are selected, there is a choice of offline metrics, which will optimize our model, for example:
- precision@k,
- recall@k,
- NDCG,
- MAP.
There are quite a few metrics for recommendation systems. So how do you choose the right one? The answer is simple: choose offline metrics that correlate with business metrics. You can do this by calculating the correlation between offline and online metrics. For example, for a while at FunCorp, we thought that the number of smiles per user correlated with such business metrics as retention, but our experiments showed that this was not the case. And we began to optimize other business metrics, such as time spent.
Analyze, and in this case, you will learn how to avoid mistakes when a model with good offline metrics worsens business metrics.
7. Create a Baseline Model
Don't try to use the most complex models to solve the problem right away — start with simpler approaches. For example, with product recommendations by popularity instead of neural networks. This simple model is called a baseline.
In this case, you will immediately see the growth of product metrics, while avoiding large infrastructure and development costs. In the future, all your more complex models will be compared with the baseline.
For example, at FunCorp, we first used a simple approach based on the K Nearest Neighborhoods algorithm to create a service for recommending content in push notifications, and only in the second iteration, we moved to a more complex boosting model. The boosting model requires more computational resources for training, so we first made sure that ML has a small positive effect — and to enhance it, it makes sense to spend time on developing a more complex model.
8. Choose the ML Algorithm and Discard the Worst Models
The next step is to train more complex models. Recommendation systems usually use both neural networks and classical ML algorithms:
- Matrix factorization,
- LogisticRegression,
- KNN (user-based, item-based),
- boosting.
At this stage, we count offline metrics and, thanks to the data already accumulated in the feedback system, we choose the best model to run in the test.
This approach has a noticeable disadvantage. Offline data are the result of the model that was working in production at the time of collecting this data, so offline experiments will be won by the model that most accurately “repeats” the current one.
So with offline data, we only distinguish very bad models from “not quite bad ones” in order to run the “not quite bad model” in the test. Alternatively, we can run the experiment without offline tests — using, for example, the multi-armed bandits mechanism. In case of bad metrics, the bandit automatically stops directing traffic to the “bad” model. But this approach of testing new models greatly complicates the architecture, so we test models on offline data.
9. Run Everything Through the AB Testing System
Any changes in the recommendation algorithm, such as switching from a baseline to an advanced model, must go through a system of AB tests.
Without good analytics, you either can't see the effect of a recommendation system, or you misinterpret the data, which can cause business metrics to deteriorate. For example, if you start recommending more NSFW content, the metric “number of likes per user” will increase in the moment. But in the long run, such content can lead to an increase in unsubscribes from the service.
This is why AB tests need to measure both short-term and long-term effects.
When conducting AB tests, you need to ensure that the samples in the test and control groups are representative. At FunCorp, we calculate the sample size depending on what metric growth we expect to see.
We also need to avoid the influence of some tests on others. This is a problem with mature products when a large number of changes are tested in parallel, some of which may affect ML output. For example, if we do tests in parallel for both the recommendation feed and moderation rules (for which the content may be rejected by the moderator), the test and control metrics may diverge not because of differences in the model but because of differences in content sorting.
10. Remember the Classic Problems in Production
When rolling out the algorithm “in production” it is necessary to provide a solution to a number of classic problems.
- Users' cold start: what to recommend to those who haven't left feedback? We recommend here to make lists of globally popular content and make them as diverse as possible to be more likely to “hook” the user.
- Content' cold-start: how do you recommend the content that hasn't had time to gain statistics? To solve this problem, cold-start content is usually swept into recommendations in a small proportion of recommendations.
- A feedback loop is a classic trap for recommendation systems. We show the content to the user, then collect feedback, and run the next learning cycle on that data. In this case, the system learns from the data it generates itself. To avoid this trap, we usually allocate a small percentage of users who receive random output instead of recommendations—with this design, the system will be trained not only on its own data but also on users' interactions with randomly selected content.
Good luck with building recommendation systems and thanks for your attention!
Alexander Dzhumurat is the lead of DS team at FunCorp, a company that creates entertaining UGC apps with millions of active users (iFunny, ABPV) and helps create the best personalization possible. Previously Alexander led the DS team at online-cinema IVI.