How to Avoid Overfitting
Overfitting is when a statistical model fits exactly against its training data. This leads to the model failing to predict future observations accurately.
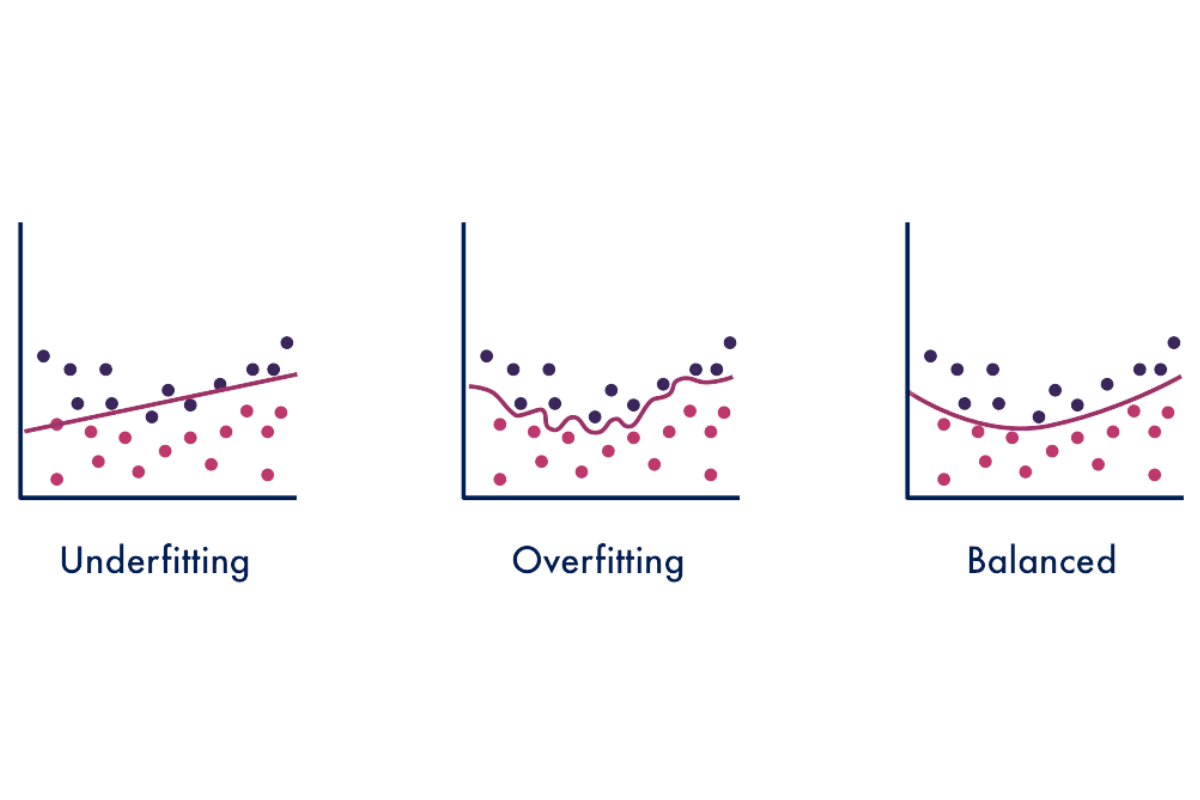
Image by Editor
Overfitting is a regular mistake that many Data Scientists make. It can take your hours of coding and throw it all in the trash bin. Your model can produce inaccurate outputs and lead to further problems in the decision making process.
Before we get into how to avoid overfitting, let’s go over what overfitting it.
What is Overfitting?
Overfitting is when a statistical model fits exactly against its training data. It is a type of modeling error which explains that your functions are too closely fit to a limited set of data points. This is due to the model solely focusing on variables it knows and automatically assumes that these predictions will work on testing or unseen data. This leads to the model failing to predict future observations accurately.
One of the reasons overfitting happens is due to the complexity of the model or the dataset. If the model is too complex or the model trains on a sample dataset that is very large - the model starts to memorize information on the dataset that is irrelevant. When information is memorized, the model fits too closely to the training set and is unable to generalize well to new data.
Although this is good when working with training data as it will produce a low error, it becomes very useless when working with testing data as it produces a high error. One way to indicate if your model is overfitting is if it has a low error rate but a high variance.
What is Underfitting?
The opposite of Overfitting is Underfitting. Underfitting is when a model fails to identify the relationship between the input and output variables accurately. This can be due to the model being very simple, and can be resolved by adding more input features or using high variance models such as Decision Trees.
The worst thing about Underfitting is that it can neither model training data nor generalize new data - producing a high error rate on both the training set and unseen data.
Signal and Noise
Another aspect we need to understand before we get into how to avoid Overfitting is Signal and Noise.
A Signal is the true underlying pattern that helps the model to learn the data. For example, the relationship between age and height in teenagers is a clear relationship.
Noise is random and irrelevant data in the dataset. Using the same example for Signal, if we sample a school that is well known for majoring in sports - this will cause outliers. Naturally there will be a higher population of pupils who attend the school due to their physical attributes, such as height in basketball. This will cause randomness in your model - showing how Noise interferes with Signal.
If you produce an efficient machine learning model that performs well, it will be able to distinguish the difference between Signal and Noise.
Goodness of fit is a statistical term that refers to how closely a model’s predicted values match the observed values. When a model learns the noise instead of learning the signal, that leads to Overfitting. A model that is too complex or too simple raises the possibility of learning Noise.
Techniques to Prevent Overfitting
Training with more data
I’m going to start off with the simplest technique you can use. Increasing the volume of your data in the training phase will not only improve the accuracy of your model but can also reduce Overfitting. This allows for your model to identify more signals, learn the patterns and minimize error.
This will help the model to generalize well to new data as there are more opportunities for the model to understand the relationship between input and output variables. However, you need to ensure that the additional training data you use is clean - if not, you could be doing the reverse and adding more complexity.
Feature Selection
The next simplest technique you can use to reduce Overfitting is Feature Selection. This is the process of reducing the number of input variables by selecting only the relevant features that will ensure your model performs well.
Depending on your task at hand, there are some features that have no relevance or correlation to other features. Therefore, these can be removed as it is overwhelming your model to learn something it does not need to. In order to figure out which features have a direct correlation to your task at hand, you can test the different features by training them on individual models.
Not only will you be improving your models performance, but you will also be reducing the computational cost of modeling.
Data Augmentation
Data Augmentation is a set of techniques which artificially increase the amount of data by generating new data points from existing data.
Although adding more clean data is an option, it is also a very expensive option. Data Augmentation reduces that cost by making data appear more diverse as the sample data look slightly different each time it is processed by the model. Each dataset will appear unique to the model - increasing its learning rate and performance.
Noise can also be used in this technique to improve the model's stability. Adding Noise to the data makes the data more diverse without reducing the quality of the data quality. However, the choice of adding Noise should be done carefully and in moderation to prevent overfitting.
Early stopping
Measuring the performance of your model during the training phase through each iteration is a good technique to prevent overfitting. You can do this by pausing the training before the model starts to learn the noise. However, you need to take into consideration that when using the ‘Early Stopping’ technique, there is the risk of pausing the training process too early - which can lead to underfitting.
Regularization
Regularization is forcing your model to be simpler to minimize the loss function and prevent overfitting or underfitting. It discourages the model from learning something that is very complex.
This technique aims to penalize the coefficient, which is helpful when reducing Overfitting as a model that is suffering from Overfitting has a coefficient that is generally inflated. If the coefficient inflates, the effect of it is that the cost function will increase.
Regularization is also a hyperparameter for techniques such as Cross-Validation - making the process easier.
Cross Validation
Cross-Validation is one of the most well known techniques used to measure against overfitting. It is used to evaluate how well the results of statistical analysis can generalize to unseen data.
The process of Cross-Validation is to generate multiple train-test splits from your training data - which are used to tune your model. The parameters will then undergo Cross-Validation which will select the best parameters and feed this back into the model to be retrained. This will improve the overall performance and accuracy of the model as well as help the model generalize better to unseen data.
Examples of Cross-Validation techniques are Hold-out, K-folds, Leave-one-out and Leave-p-out.
The benefits of Cross-Validation is that it is simple to understand, easy to implement, and it generally has a lower bias in comparison to other methods.
If you would like to know more about the most well used Cross-Validation technique K-fold, have a read of this article: Why Use k-fold Cross Validation?
Ensembling
The last technique I will speak about is Ensembling. Ensemble methods create multiple models and then combine the predictions produced by these models to improve the results. The most popular ensemble methods include boosting and bagging.
Bagging
Bagging is an acronym for ‘Bootstrap Aggregation’ and is an ensemble method used to decrease the variance in the prediction model. Bagging aims to reduce the chance of overfitting complex models by focusing on the ‘strong learners’
It trains a large number of strong learners in parallel and then combines the strong learners together in order to optimize and produce accurate predictions. Algorithms that are known for having high variance are decision trees, like classification and regression trees (CART)
Boosting
Boosting focuses on converting a ‘weak learner’ to a stronger one by improving the predictive flexibility of much simpler models. It decreases the bias error by building and improving simpler models into strong predictive models.
The weak learners are trained in sequence so that they can focus on learning from their previous mistakes. Once this is done, the weak learners are all combined into a strong learner.
If you would like to know more about Ensemble Techniques, have a read of this article: When Would Ensemble Techniques be a Good Choice?
Conclusion
You made it to the end. In this article we have gone through:
- What is Overfitting?
- What is Underfitting?
- Signal and Noise
- Techniques to prevent Overfitting
Stay tuned for more articles that go further into this topic such as The Variance Bias Trade-off and more.
Nisha Arya is a Data Scientist and Freelance Technical Writer. She is particularly interested in providing Data Science career advice or tutorials and theory based knowledge around Data Science. She also wishes to explore the different ways Artificial Intelligence is/can benefit the longevity of human life. A keen learner, seeking to broaden her tech knowledge and writing skills, whilst helping guide others.