skops: A New Library to Improve Scikit-learn in Production
There are various challenges in MLOps and model sharing, including, security and reproducibility. To tackle these for scikit-learn models, we've developed a new open-source library: skops. In this article, I will walk you through how it works and how to use it with an end-to-end example.
There are various challenges when it comes to machine learning models in production. These range from reproducibility in versioning to secure serialization. In this blog post, I will walk you through a library called skops, to tackle these challenges.
We will see an end-to-end example: train a model first, serialize it, document our model, and host it.
# let's import the libraries first
import sklearn
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from datasets import load_dataset
# Load the data and split
data = load_dataset("scikit-learn/breast-cancer-wisconsin")
df = data["train"].to_pandas()
y = df["diagnosis"]
X = df.drop("diagnosis", axis=1)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
pipe = Pipeline(
steps=[
("imputer", SimpleImputer()),
("scaler", StandardScaler()),
("model", LogisticRegression())
]
)
pipe.fit(X_train, y_train)
Secure Serialization
We will now save the model. We can save the model using any format, including, joblib, pickle or skops.
skops introduces a new serialization format. The motivation here is to avoid the use of pickle or joblib to serialize sklearn models. Serialization with pickle or joblib can result in bad actors executing code on your local machine and you should avoid deserializing a pickle file if it’s from a source you do not trust. It’s a serialization protocol that serializes instructions for your code in binary format, thus, it’s not human-readable. It can practically do anything: remove everything on your machine or install malware. You should only deserialize a pickle from a source that you trust.
The serialization format introduced by skops doesn’t rely on pickle and lets users see what a given file contains without loading it. You can read more about it here. Let’s take a look at the API.
You can save a sklearn model or pipeline by passing the object and the file path that it will be saved to.
import skops.io as sio
sio.dump(pipe, "pipeline.skops")
The tricky part is to load the model from a file. We will pass the file path to load. We have one more parameter called trusted which can be either True, list of trusted types, or False. If set to False, it will only load the trusted types. Let's take a look.
# passing `True`
sio.load("pipeline.skops", trusted=True)
# result
Pipeline(steps=[('imputer', SimpleImputer()), ('scaler', StandardScaler()),
('model', LogisticRegression())])
We can get a list of untrusted types using get_untrusted_types.
unknown_types = sio.get_untrusted_types(file="pipeline.skops")
print(unknown_types)
# output
['numpy.int64']
You can directly pass the above list to trusted.
loaded_model = sio.load("pipeline.skops", trusted=unknown_types)
If you try to load without the transformer on top, loading will fail with an UntrustedTypesFoundException.
loaded_model = sio.load("pipeline.skops", trusted=unknown_types[1:])
# output
UntrustedTypesFoundException: Untrusted types found in the file: ['numpy.int64'].
Note that you always need to pass something to trusted, as this prompts the user to determine whether to trust this file or not.
loaded_model = sio.load("pipeline.skops")
# output
UntrustedTypesFoundException: Untrusted types found in the file: ['numpy.int64'].
Model Hosting
If you’d like to host models open to everyone, you can do that with skops and Hugging Face Hub. This enables easy inference without downloading the model, model documentation in the model repository, and building interfaces with one line of code.

Hugging Face Model Repository

This is built with one line of code
Let’s see how to create these programmatically.
hub_utils.init creates a local folder containing the model in the given path, and the configuration file containing the requirements of the environment the model is trained in, the training objective, a sample from the dataset, and more. The sample data and the task identifier passed to the init will help Hugging Face Hub enable the inference widget on the model page as well as discoverability features to find the model.
Note: The inference widget, inference API, and
gradiointegration only work with pickle format for now. We are currently developing support forskopsformat. Therefore, we will save the model inpicklefor now.
from skops import hub_utils
import pickle
# let's save the model
model_path = "example.pkl"
local_repo = "my-awesome-model"
with open(model_path, mode="bw") as f:
pickle.dump(pipe, file=f)
# we will now initialize a local repository
hub_utils.init(
model=model_path,
requirements=[f"scikit-learn={sklearn.__version__}"],
dst=local_repo,
task="tabular-classification",
data=X_test,
)
The repository now contains the model and the configuration file that enable inference, build environment to load the model and more. The configuration file is a JSON that contains:
- a small sample of the dataset,
- columns of the dataset,
- the environment requirements to load the model,
- relative path to the model file inside the repository,
- the task that is being solved.
Now, we will document our model by creating a model card. The model cards in skops follow the format of Hugging Face Hub model cards: it consists of a markdown part and yaml metadata section. You can check out the keys of the metadata section here for better discoverability of the models. The model card follows a template that consists of:
- YAML section on top for metadata (task ID, license, library name used for training, and more)
- free text section in the format of markdown and sections to be filled (e.g. description of the model, intended use, limitations and more),
Below sections of the model card are automatically generated by skops:
- Hyperparameters of the model,
- Interactive diagram of the model,
- A small snippet that shows how to load and use the model,
- For metadata, library name, task identifier (e.g. tabular-classification), and information required by the inference widget is filled.
skops enables programmatic editing of the model card through various methods. The documentation on the card module and the default template provided by skops is here.
You can instantiate the Card class from skops to create the model card. This class is an intermediate data structure that is later rendered to markdown. We will later save this card to the repository where the model will be hosted. During the initialization of the repository, the task name (e.g. tabular-regression) and library name (e.g. scikit-learn) are written to the configuration file during repository initialization. Task and library names are also needed in the card's metadata, so you can use the metadata_from_config method to extract the metadata from the configuration file and pass it to the card when you create it. You can use add method to add information and edit metadata.
from skops import card
from pathlib import Path
# create the card
model_card = card.Card(pipe, metadata=card.metadata_from_config(Path(local_repo)))
limitations = "This model is not ready to be used in production."
model_description = (
"This is a LogisticRegression model trained on breast cancer dataset."
)
# add information to the model card
model_card.add(**{"Model description/Intended uses & limitations": limitations})
# set the license in the metadata
model_card.metadata.license = "mit"
We can evaluate the model and write it to the model card as metric. We can use the add_metrics method which adds metrics to our model card and writes as a table.
from sklearn.metrics import (ConfusionMatrixDisplay, confusion_matrix,
accuracy_score, f1_score)
# let's make a prediction and evaluate the model
y_pred = pipe.predict(X_test)
# we can pass metrics using add_metrics and pass details with add
model_card.add_metrics(accuracy=accuracy_score(y_test, y_pred))
model_card.add_metrics(**{"f1 score": f1_score(y_test, y_pred, average="micro")})
Plots that visualize model performance can be added using add_plots.
import matplotlib.pyplot as plt
# we will create a confusion matrix
cm = confusion_matrix(y_test, y_pred, labels=pipe.classes_)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=pipe.classes_)
disp.plot()
# save the plot
plt.savefig(Path(local_repo) / "confusion_matrix.png")
# the plot will be written to the model card under the name confusion_matrix
# we pass the path of the plot itself
model_card.add_plot(**{
"Confusion Matrix": "path-to-confusion-matrix.png"})
Let’s save the model card in the local repository. The file name here should be README.md since it is what Hugging Face Hub expects.
model_card.save(Path(local_repo) / "README.md")
The repository is now ready for push to Hugging Face Hub. We can use hub_utils for this. Hugging Face Hub follows an authentication flow with tokens, so we can pass our token in push.
# set create_remote to True if the repository doesn't exist remotely on the Hugging Face Hub
hub_utils.push(
repo_id="scikit-learn/blog-example",
source=local_repo,
commit_message="pushing files to the repo from the example!",
create_remote=True,
)
Once the model is on the Hugging Face Hub, it can be downloaded by anyone using download, unless the model is private. The repository contains the model, model card, and model configuration that contains a small sample of the dataset for reproducibility, requirements, and more.
# pass repository ID that our model is hosted on the Hub, destination directory can be any path
hub_utils.download(repo_id="scikit-learn/blog-example", dst="downloaded-model")
The model can be easily tested using the inference widget.
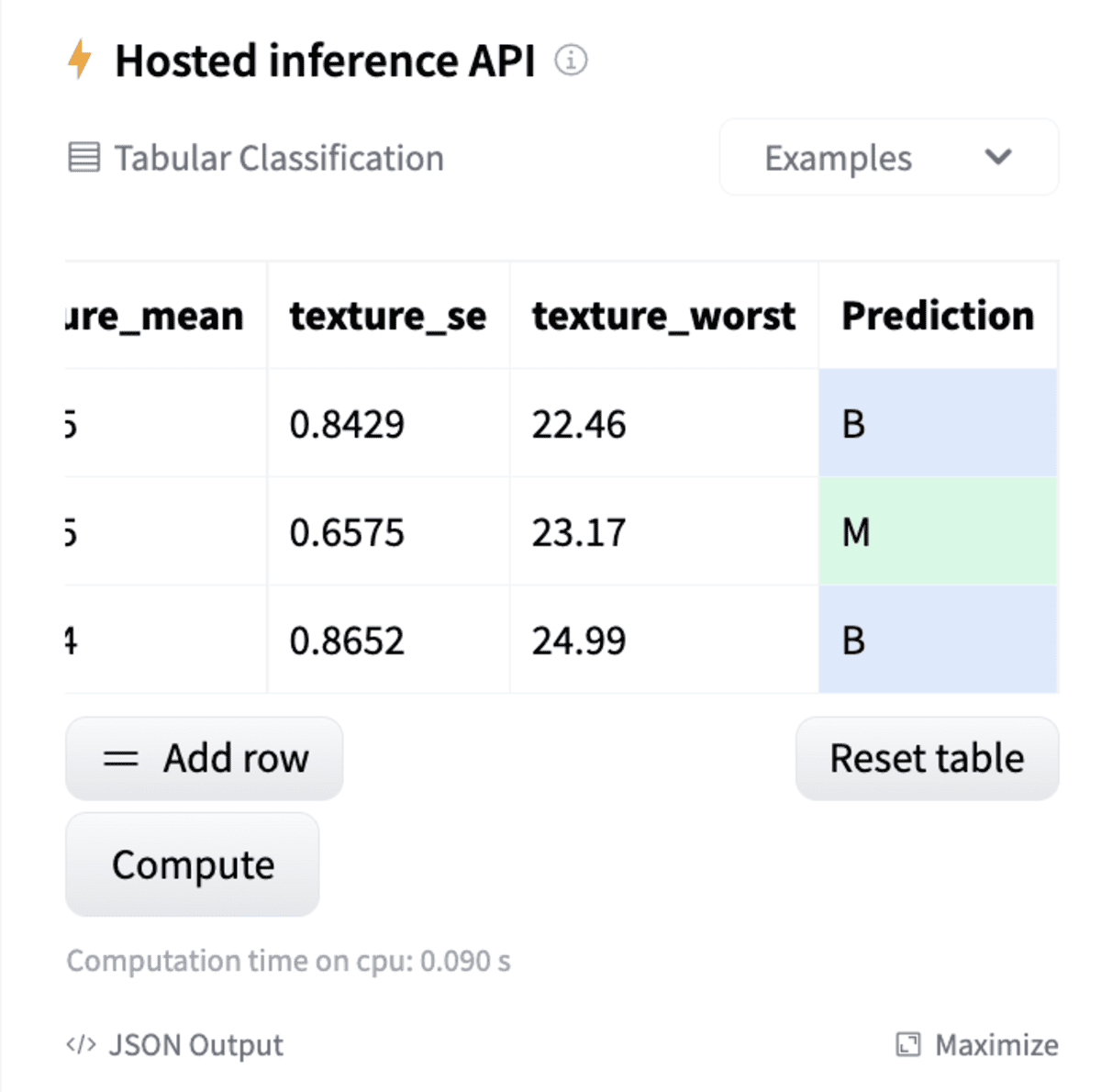
Inference Widget in Repository
We can now use gradio integration for skops. We’ve created the interface below with only one line of code! ????
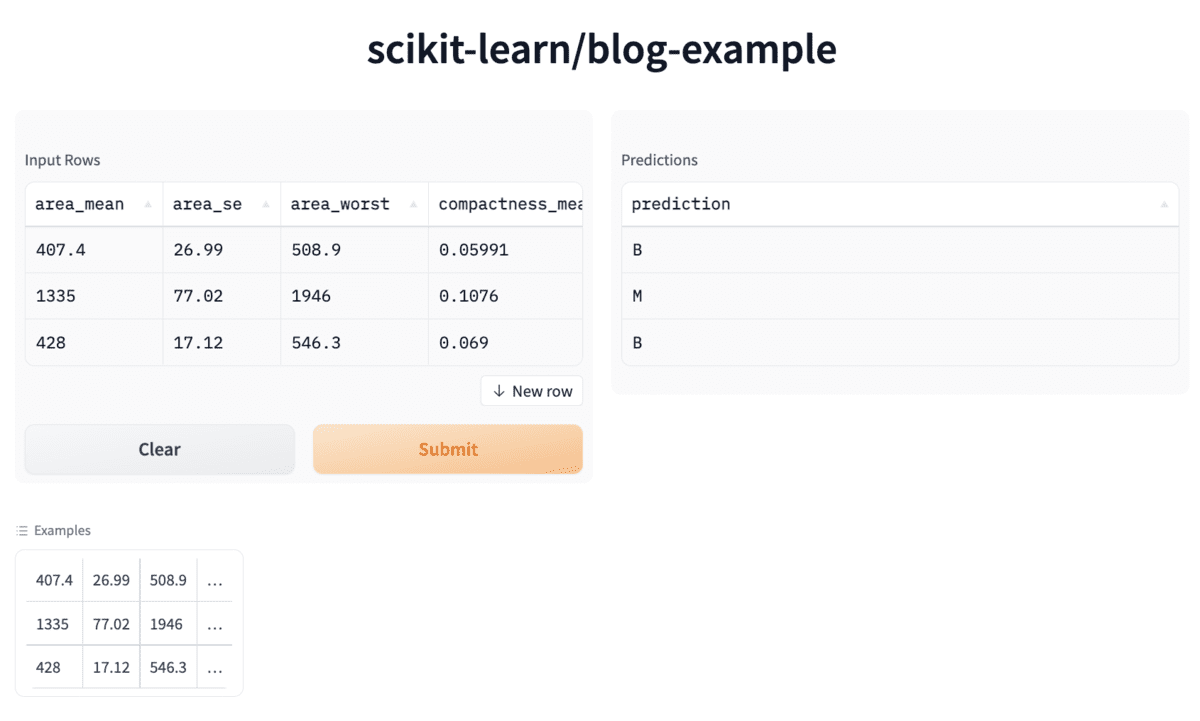
Gradio UI for our model
import gradio as gr
gr.Interface.load("huggingface/scikit-learn/skops-blog-example").launch()
We can further customize this UI like the following:
We can pass title, description, and more to the loaded UI. Check out gradio documentation on Interface class for more information on what you can customize.
import gradio as gr
gr.Interface.load("huggingface/scikit-learn/blog-example",
title="Logistic Regression on Breast Cancer").launch()
The resulting repository is here.
Further Resources
Merve Noyan is a Google developer expert on machine learning and developer advocate at Hugging Face.