A Beginner’s Guide to Pandas Melt Function
Transform your dataset from a Wide-format into a Long format quickly.

Image by catalyststuff on Freepik
When handling the real-life dataset, we can’t expect our dataset to act as we require. Sometimes, the data need to be transformed into another format to handle them easier. One way is to reshape the wide format data frame into a long format.
We often encounter wide format data; each row is the data, and the column is the data feature. Let me give you an example by using the dataset example. We would use the product sales data from Kaggle (License: CC BY-NC-SA 4.0) by Soumyadipta Das.
import pandas as pd
df = pd.read_csv('time series data.csv')
df.head()
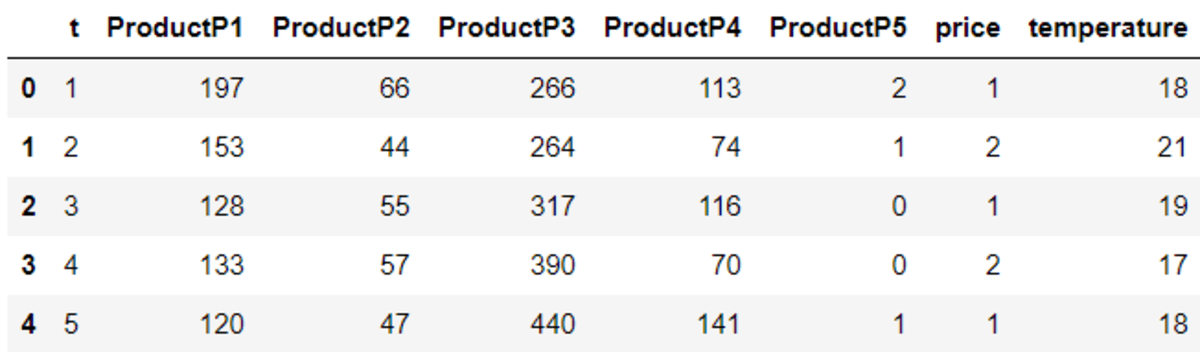
In the dataset above, each row is the time of the sales happening. On the other hand, the columns were the product type and the other supporting category (price, temperature).
The dataset above is good, but it might be hard if we want to do aggregation on the product level. That is why we can transform the data into a Long format to make the analysis easier. To do that, we can rely on the Pandas' melt function.
Pandas Melt Function
Pandas melt was used to transform the dataset from a Wide format into a Long format. What is a Long format dataset? It’s a dataset where the row is data of a combination of the variable and their values. In technical terms, we are unpivoting the dataset to acquire a dataset with fewer columns and longer rows. Let’s try out the melt function to understand better.
pd.melt(df)
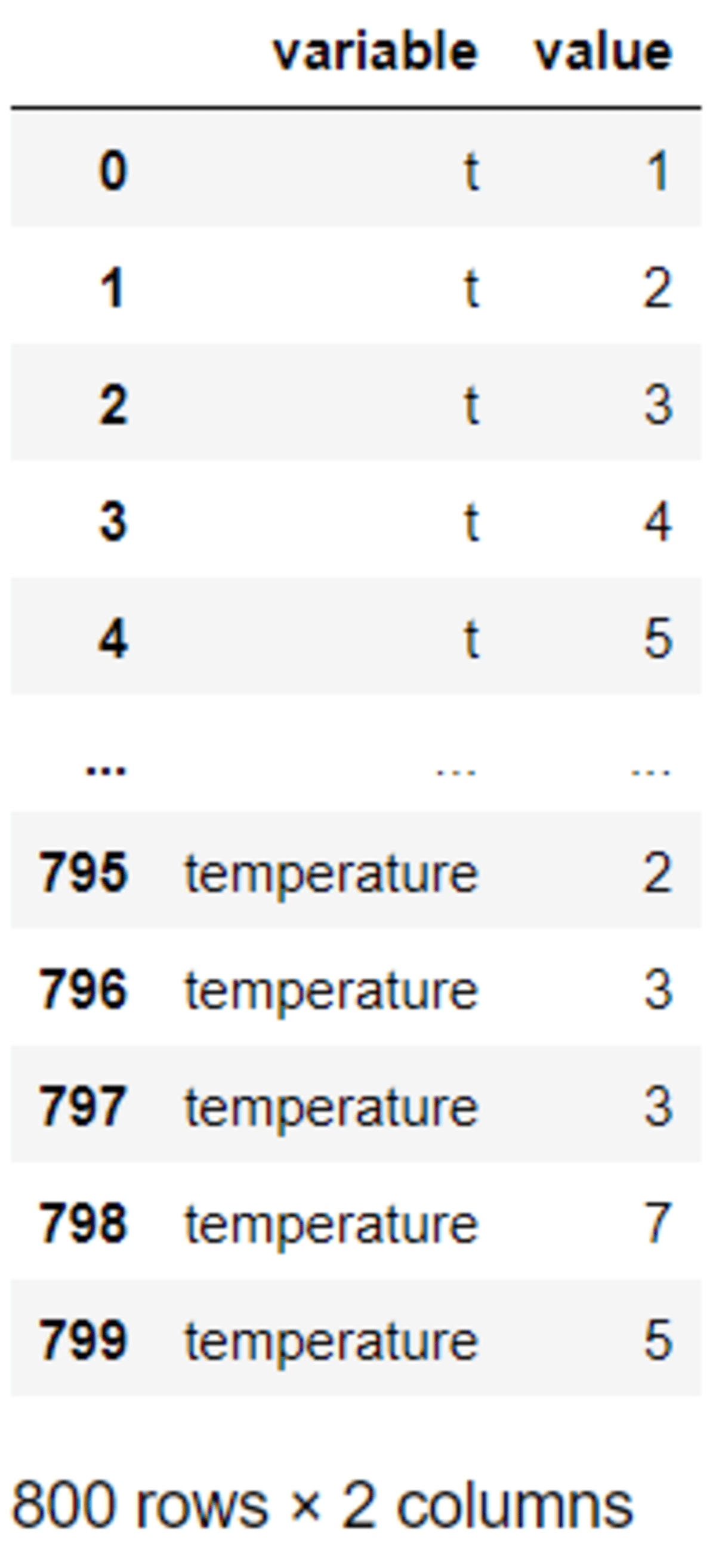
We end up with the Long format dataset from the output above. The dataset contains only two columns; the ‘variable’, which is the column name in the Wide format dataset and the ‘value’, which is the data value for each row in the Wide format.
For example, column ‘t’ is now treated as a data observation for as much as the original dataset rows number with the respective values. Basically, the melt function provides a key-value pair from the Wide format data.
Compared to the Wide format, we can now create a category based on the product level, which we couldn’t do as the Wide format data product is the column name. Let’s try to do that with the melt function.
pd.melt(
df,
id_vars=["t"],
value_vars=["ProductP1", "ProductP2"],
var_name="Product",
value_name="Sales",
)
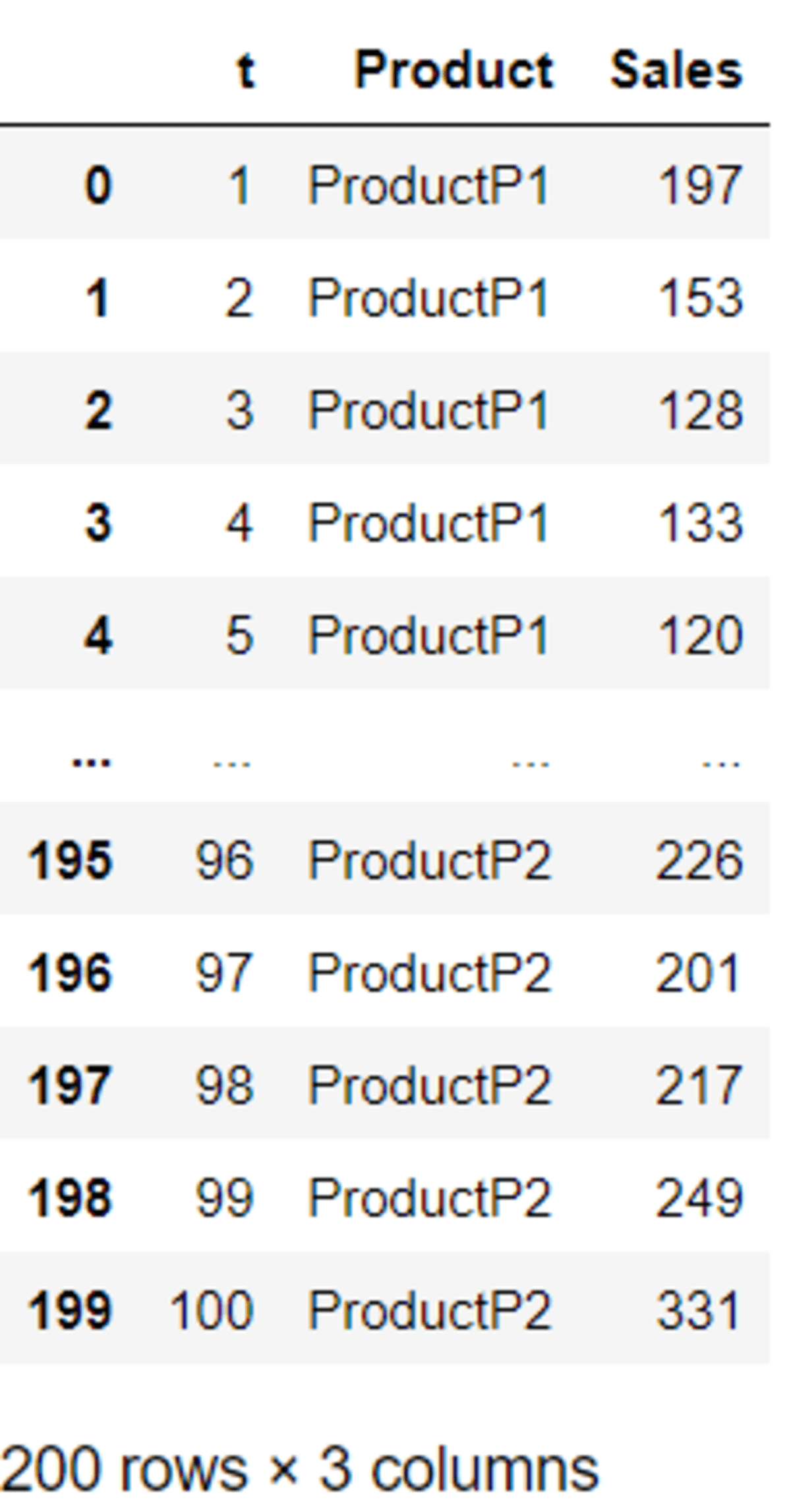
In the code above, we specify the ‘t’ column as the data identifier and the ‘ProductP1’ with ‘ProductP2’ as the category. To make the reading easier, we change the variable name to ‘Product’ and the value to ‘Sales’.
Now, with the code above, for each time frame (‘t’), we acquire two different Product categories with their values. This makes the analysis of the dataset more intuitive as the group comparison is more explicit.
We can melt the dataset with the DataFrame method as well. The current code works precisely similar to the example above.
df.melt(
id_vars=["t"],
value_vars=["ProductP1", "ProductP2"],
var_name="Product",
value_name="Sales",
)
You can choose your data melting method preferences depending on your data pipeline. There are no differences at all in the result between both methods.
It’s also possible to add more identifiers to our melted dataset. To do that, we only need to specify all the intended identifiers in the ‘id_vars’ parameters. For example, I would add the ‘price’ column as an additional identifier.
pd.melt(
df,
id_vars=["t", "price"],
value_vars=["ProductP1", "ProductP2"],
var_name="Product",
value_name="Sales",
)
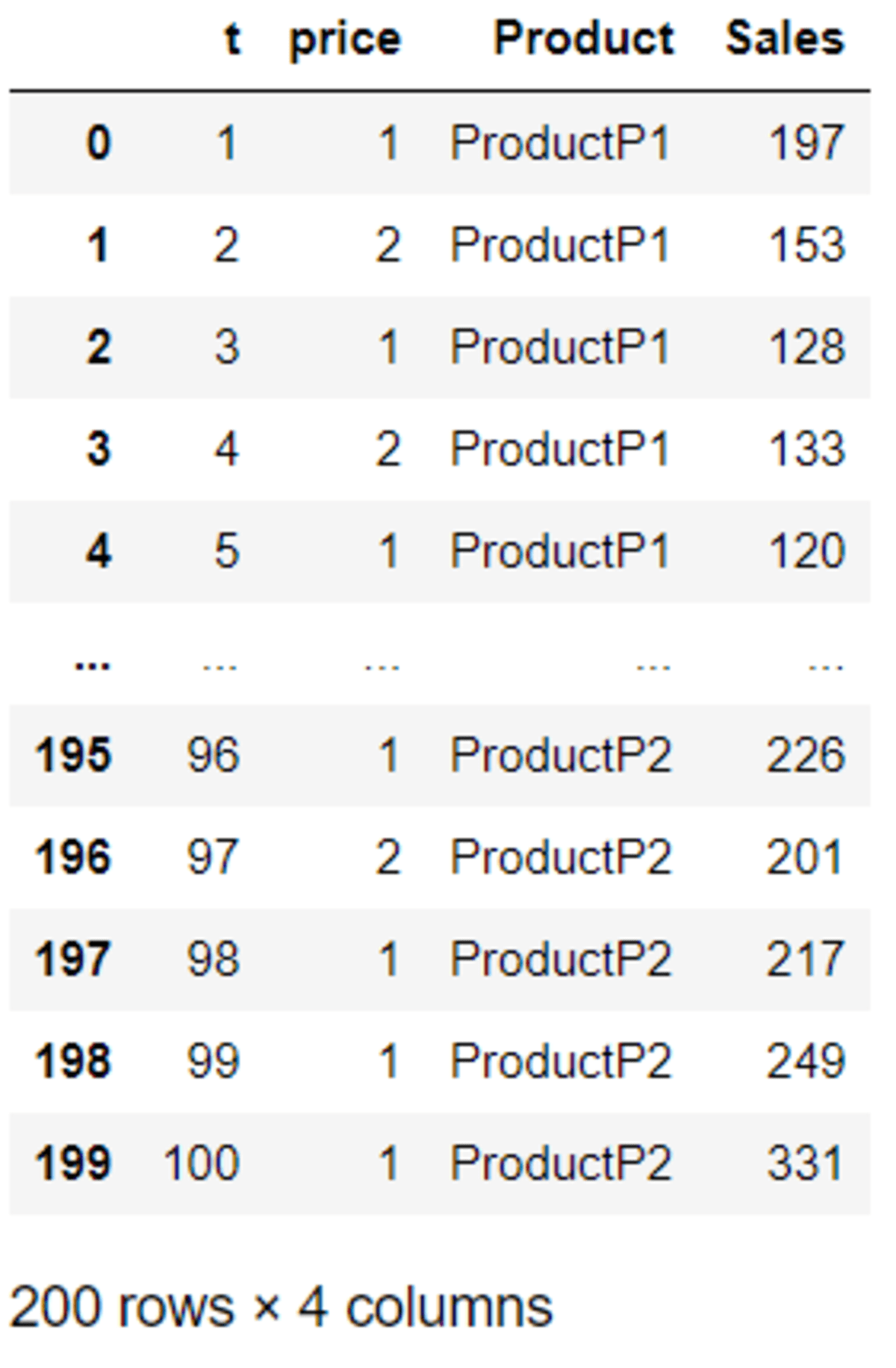
The result would be both the ‘t’ and ‘price’ column as the dataset identifier. The method above would be helpful when you have multiple keys in your Wide format dataset that you don’t want to remove.
For further reference of the Pandas melt function, you could visit the Pandas documentation.
Conclusion
Long-format data is sometimes preferred compared to Wide format data. Occasionally, our columns were what we wanted to analyse, and the only way to acquire them was by unpivoting the data. By using the Pandas melt function, we manage to transform the Wide format data into a Long format containing a key-value combination of the column's name and the values from the original data.
Cornellius Yudha Wijaya is a data science assistant manager and data writer. While working full-time at Allianz Indonesia, he loves to share Python and Data tips via social media and writing media.