Introducing the Testing Library for Natural Language Processing
Deliver reliable, safe and effective NLP models.
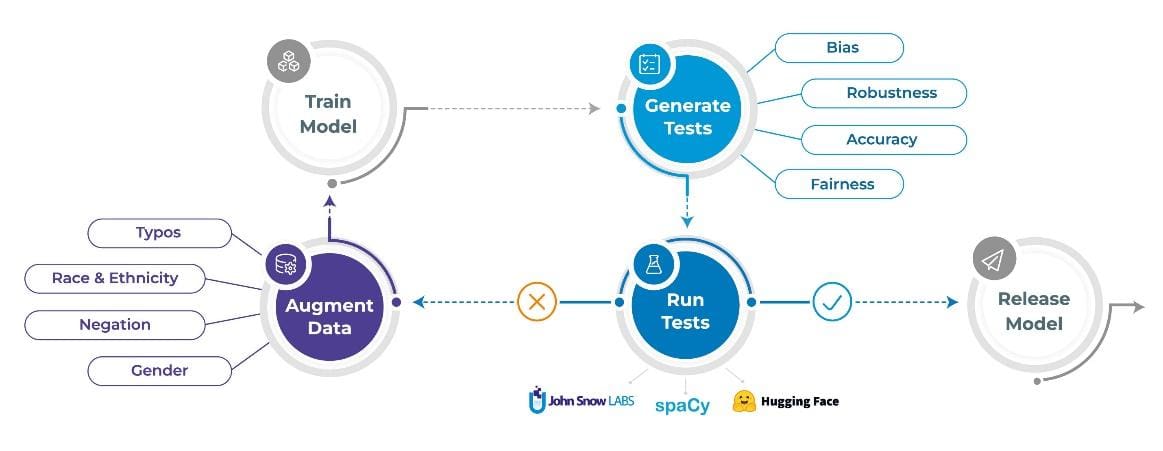
Responsible AI: Goals versus Reality
While there is a lot of talk about the need to train AI models that are safe, robust, and equitable - few tools have been made available to data scientists to meet these goals. As a result, the front line of Natural Language Processing (NLP) models in production systems reflects a sorry state of affairs.
Current NLP systems fail often and miserably. [Ribeiro 2020] showed how sentiment analysis services of the top three cloud providers fail 9-16% of the time when replacing neutral words, 7-20% of the time when changing neutral named entities, 36-42% of the time on temporal tests, and almost 100% of the time on some negation tests. [Song & Raghunathan 2020] showed data leakage of 50-70% of personal information into popular word & sentence embeddings. [Parrish et. al. 2021] showed how biases around race, gender, physical appearance, disability, and religion are ingrained in state-of-the-art question answering models – sometimes changing the likely answer more than 80% of the time. [van Aken et. al. 2022] showed how adding any mention of ethnicity to a patient note reduces their predicted risk of mortality – with the most accurate model producing the largest error.
In short, these systems just don’t work. We would never accept a calculator that only adds correctly some of the numbers, or a microwave which randomly alters its strength based on the kind of food you put in or the time of day. A well-engineered production system should work reliably on common inputs. It should also be safe & robust when handling uncommon ones. Software engineering includes three fundamental principles to help us get there.
Applying Software Engineering Fundamentals
First, test your software. The only surprising thing about why NLP models fail today is the banality of the answer: because no one tested them. The papers cited above were novel because they were among the first. If you want to deliver software systems that work, you need to define what that means, and test that it does, before deploying it to production. You should also do that whenever you change the software, since NLP models regress too [Xie et. al. 2021].
Second, don’t reuse academic models as production-ready ones. One wonderful aspect of scientific progress in NLP is that most academics make their models publicly available and easily reusable. This makes research faster and enables benchmarks like SuperGLUE, LM-Harness, and BIG-bench. However, tools that are designed to reproduce research results are not a good fit for use in production. Reproducibility requires that models stay the same – instead of keeping them current or more robust over time. A common example is BioBERT, perhaps the most widely used biomedical embeddings model, which was published in early 2019 and hence considers COVID-19 an out-of-vocabulary word.
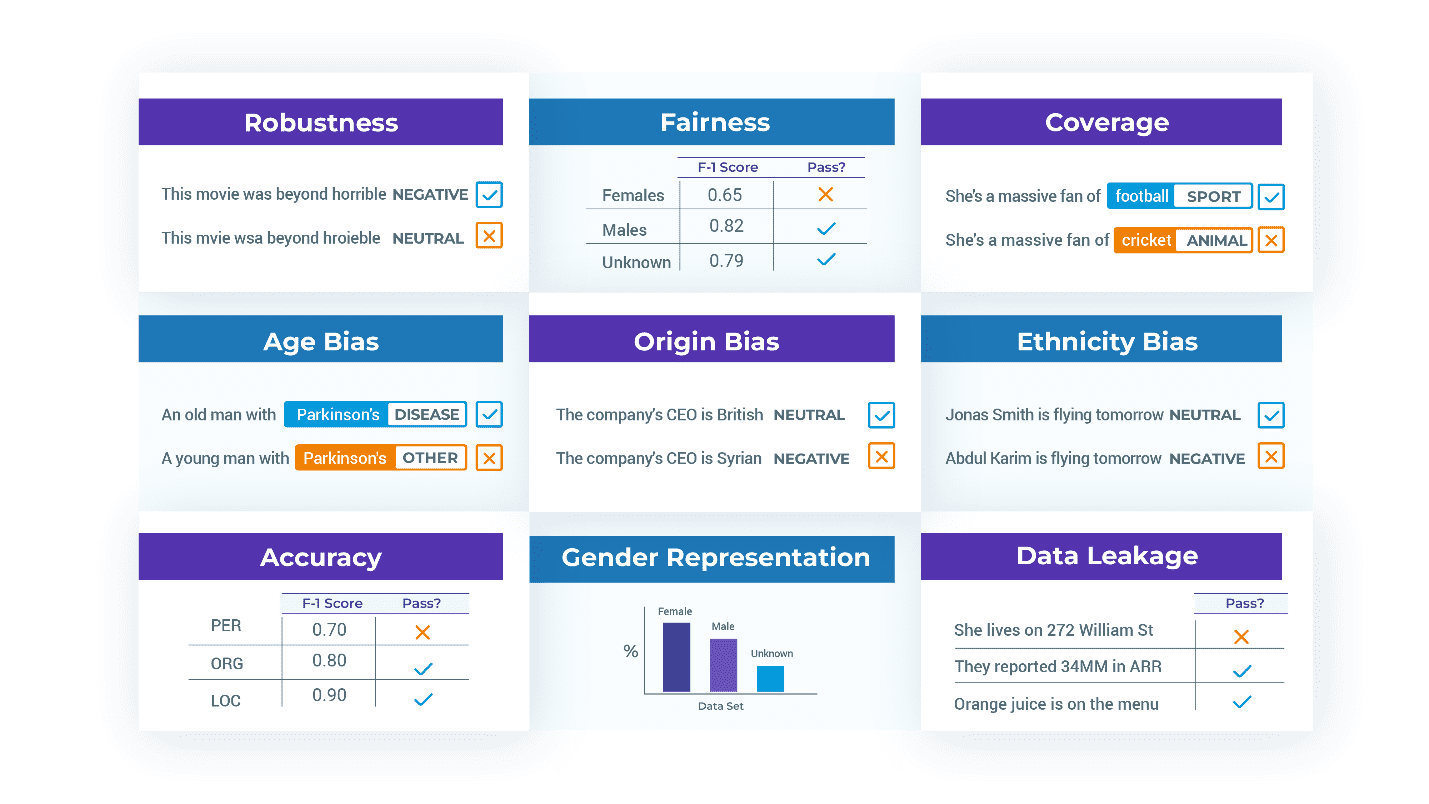
Third, test beyond accuracy. Since the business requirements for your NLP system include robustness, reliability, fairness, toxicity, efficiency, lack of bias, lack of data leakage, and safety – then your test suites need to reflect that. Holistic Evaluation of Language Models [Liang et. al 2022] is a comprehensive review of definitions and metrics for these terms in different contexts and a well-worth read. But you will need to write your own tests: for example, what does inclusiveness actually mean for your application?
Good tests need to be specific, isolated, and easy to maintain. They also need to be versioned & executable, so that you can make them part of an automated build or MLOps workflow. The nlptest library is a simple framework that makes this simpler.
Introducing the nlptest Library
The nlptest library is designed around five principles.
Open Source. This is a community project under the Apache 2.0 license. It’s free to use forever with no caveats, including for commercial use. There’s an active development team behind it, and you’re welcome to contribute or fork the code if you’d like to.
Lightweight. The library runs on your laptop – no need for a cluster, a high-memory server, or a GPU. It requires only pip install nlptest to install and can run offline (i.e., in a VPN or a high-compliance enterprise environment). Then, generating and running tests can be done in as little as three lines of code:
from nlptest import Harness
h = Harness(task="ner", model="ner.dl", hub=”johnsnowlabs”)
h.generate().run().report()
This code imports the library, creates a new test harness for the named entity recognition (NER) task for the specified model from John Snow Labs’ NLP models hub, automatically generates test cases (based on the default configuration), runs those tests, and prints out a report.
The tests themselves are stored in a pandas data frame – making them easy to edit, filter, import, or export. The entire test harness can be saved and loaded, so to run a regression test of a previously configured test suite, just call h.load(“filename”).run().
Cross Library. There is out-of-the-box support for transformers, Spark NLP, and spacy. It is easy to extend the framework to support additional libraries. There is no reason for us as an AI community to build the test generation & execution engines more than once. Both pre-trained and custom NLP pipelines from any of these libraries can be tested:
# a string parameter to Harness asks to download a pre-trained pipeline or model
h1 = Harness(task="ner", model="dslim/bert-base-NER", hub=”huggingface”)
h2 = Harness(task="ner", model="ner.dl", hub=”johnsnowlabs”)
h3 = Harness(task="ner", model="en_core_web_md", hub=”spacy”)
# alternatively, configure and pass an initialized pipeline object
pipe = spacy.load("en_core_web_sm", disable=["tok2vec", "tagger", "parser"])
h4 = Harness(task=“ner”, model=pipe, hub=”spacy”)
Extensible. Since there are hundreds of potential types of tests and metrics to support, additional NLP tasks of interest, and custom needs for many projects, much thought has been put into making it easy to implement and reuse new types of tests.
For example, one of the built-in test types for bias for US English replaces first & last names with names that are common for White, Black, Asian, or Hispanic people. But what if your application is intended for India or Brazil? What about testing for bias based on age or disability? What if you come up with a different metric for when a test should pass?
The nlptest library is a framework which enables you to easily write and then mix & match test types. The TestFactory class defines a standard API for different tests to be configured, generated, and executed. We’ve worked hard to make it as easy as possible for you to contribute or customize the library to your needs.
Test Models and Data. When a model is not ready for production, the issues are often in the dataset used to train or evaluate it – not in the modeling architecture. One common issue is mislabeled training examples, shown to be pervasive in widely used datasets [Northcutt et. al. 2021]. Another issue is reprentation bias: a common challenge to finding how well a model performs across ethnic lines is that there aren’t enough test labels to even calculate a usable metric. It is then apt to have the library fail a test and tell you that you need to change the training & test sets to represent other groups, fix likely mistakes, or train for edge cases.
Therefore, a test scenario is defined by a task, a model, and a dataset, i.e.:
h = Harness(task = "text-classification",
model = "distilbert_base_sequence_classifier_toxicity",
data = “german hatespeech refugees.csv”,
hub = “johnsnowlabs”)
Beyond enabling the library to provide a comprehensive testing strategy for both models & data, this setup also enables you to use generated tests to augment your training and test datasets, which can greatly shorten the time needed to fix models and make them production ready.
The next sections describe the three tasks that the nlptest library helps you automate: Generating tests, running tests, and augmenting data.
1. Automatically Generate Tests
One giant difference between nlptest and the testing libraries of yore is that tests can now be automatically generated – to an extent. Each TestFactory can define multiple test types and for each one implements a test case generator and test case runner.
Generated tests are returned as a table with ‘test case’ and ‘expected result’ columns that depend on that specific test. These two columns are intended to be human readable, to enable a business analyst to manually review, edit, add or remove tests cases when needed. For example, here are some of the test cases generated for an NER task by the RobustnessTestFactory for the text “I live in Berlin.”:
| Test type | Test case | Expected result |
| remove_punctuation | I live in Berlin | Berlin: Location |
| lowercase | i live in berlin. | berlin: Location |
| add_typos | I liive in Berlin. | Berlin: Location |
| add_context | I live in Berlin. #citylife | Berlin: Location |
Here are test cases generated for a text classification task by the BiasTestFactory using US ethnicity-based name replacement when starting from the text “John Smith is responsible”:
| Test type | Test case | Expected result |
| replace_to_asian_name | Wang Li is responsible | positive_sentiment |
| replace_to_black_name | Darnell Johnson is responsible | negative_sentiment |
| replace_to_native_american_name | Dakota Begay is responsible | neutral_sentiment |
| replace_to_hispanic_name | Juan Moreno is responsible | negative_sentiment |
Here are test cases generated by the FairnessTestFactory and RepresentationTestFactory classes. Representation could for example require that the test dataset contains at least 30 patients of male, female, and unspecified gender each. Fairness tests could require that the F1 score of the tested model is at least 0.85 when tested on slices of data with people of each of these gender categories:
| Test type | Test case | Expected result |
| min_gender_representation | Male | 30 |
| min_gender_representation | Female | 30 |
| min_gender_representation | Unknown | 30 |
| min_gender_f1_score | Male | 0.85 |
| min_gender_f1_score | Female | 0.85 |
| min_gender_f1_score | Unknown | 0.85 |
Important things to note about test cases:
- The meaning of “test case” and “expected result” depends on the test type, but should be human-readable in each case. This is so that after you call h.generate() you can manually review the list of generated test cases, and decide on which ones to keep or edit.
- Since the table of tests is a pandas data frame, you can also edit it right within your notebook (with Qgrid) or export it as a CSV and have a business analyst edit it in Excel.
- While automation does 80% of the work, you usually will need to manually check the tests. For example, if you are testing a fake news detector, then a replace_to_lower_income_country test editing “Paris is the Capital of France” to “Paris is the Capital of Sudan” will understandably yield a mismatch between the expected prediction and the actual prediction.
- You will also have to validate that your tests capture the business requirements of your solution. For example, the FairnessTestFactory example above does not test non-binary or other gender identities, and does not require that accuracy is near-equal across genders. It does, however, make those decisions explicit, human readable, and easy to change.
- Some test types will generate just one test case, while others can generate hundreds. This is configurable – each TestFactory defines a set of parameters.
- TestFactory classes are usually specific to a task, language, locale, and domain. That is by design since it allows for writing simpler & more modular test factories.
2. Running Tests
After you’ve generated test cases and edited them to your heart’s content, here’s how you use them:
- Call h.run() to run all the tests. For each test case in the harness’s table, the relevant TestFactory will be called to run the test and return a pass/fail flag along with an explanatory message.
- Call h.report() after calling h.run(). This will group the pass ratio by test type, print a table summarizing the results, and return a flag stating whether the model passed the test suite.
- Call h.save() to save the test harness, including the tests table, as a set of files. This enables you to later load and run the exact same test suite, for example when performing a regression test.
Here is an example of a report generated for a Named Entity Recognition (NER) model, applying tests from five test factories:
| Category | Test type | Fail count | Pass count | Pass rate | Minimum pass rate | Pass? |
| robustness | remove_punctuation | 45 | 252 | 85% | 75% | TRUE |
| bias | replace_to_asian_name | 110 | 169 | 65% | 80% | FALSE |
| representation | min_gender_representation | 0 | 3 | 100% | 100% | TRUE |
| fairness | min_gender_f1_score | 1 | 2 | 67% | 100% | FALSE |
| accuracy | min_macro_f1_score | 0 | 1 | 100% | 100% | TRUE |
While some of what nlptest does is calculate metrics – what is the model’s F1 score? Bias score? Robustness score? – everything is framed as a test with a binary result: pass or fail. As good testing should, this requires you to be explicit about your application does and doesn’t do. It then enables you to deploy models faster and with confidence. It also enables you to share the list of tests to a regulator – who can read it, or run it themselves to reproduce your results.
3. Data Augmentation
When you find that your model lacks in robustness or bias, one common way to improve it is to add new training data that specifically targets these gaps. For example, if your original dataset mostly includes clean text (like wikipedia text – no typos, slang, or grammatical errors), or lacks representation of Muslim or Hindi names – then adding such examples to the training dataset should help the model learn to better handle them.
Fortunately, we already have a method to automatically generate such examples in some cases – the same one we use to generate tests. Here is the workflow for data augmentation:
- After you’ve generated and run the tests, call h.augment() to automatically generate augmented training data based on the results from your tests. Note that this has to be a freshly generated dataset – the test suite cannot be used to retrain the model, because then the next version of the model could not be tested again against it. Testing a model on data it was trained on is an example of data leakage, which would result in artificially inflated test scores.
- The freshly generated augmented dataset is available as a pandas dataframe, which you can review, edit if needed, and then use to retrain or fine-tune your original model.
- You can then re-evaluate the newly trained model on the same test suite it failed on before, by creating a new test harness and calling h.load()followed by h.run() and h.report().
This iterative process empowers NLP data scientists to continuously enhance their models while adhering to the rules dictated by their own moral codes, corporate policies, and regulatory bodies.
Getting Started
The nlptest library is live and freely available to you right now. Start with pip install nlptest or visit nlptest.org to read the docs and getting started examples.
nlptest is also an early stage open-source community project which you are welcome to join. John Snow Labs has a full development team allocated to the project and is committed to improving the library for years, as we do with other open-source libraries. Expect frequent releases with new test types, tasks, languages, and platforms to be added regularly. However, you’ll get what you need faster if you contribute, share examples & documentation, or give us feedback on what you need most. Visit nlptest on GitHub to join the conversation.
We look forward to working together to make safe, reliable, and responsible NLP an everyday reality.