7 Steps to Mastering Large Language Models (LLMs)
Large Language Models (LLMs) have unlocked a new era in natural language processing. So why not learn more about them? Go from learning what large language models are to building and deploying LLM apps in 7 easy steps with this guide.
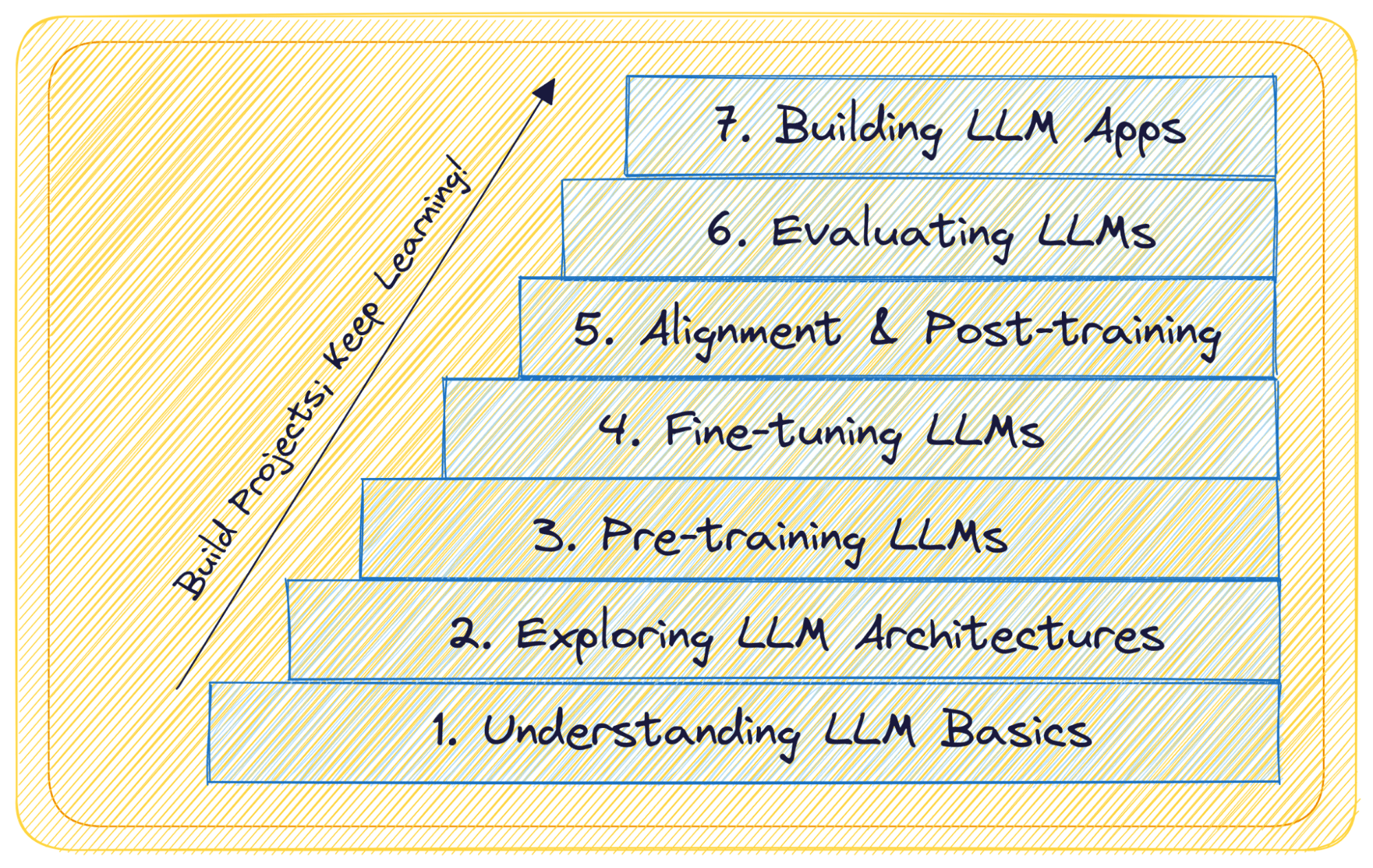
Image by Author
GPT-4, Llama, Falcon, and many more—Large Language Models—LLMs—are literally the talk of the town year. And if you’re reading this chances are you’ve already used one or more of these large language models through a chat interface or an API.
If you’ve ever wondered what LLMs really are, how they work, and what you can build with them, this guide is for you. Whether you’re a data professional interested in large language models or someone just curious about them, this is a comprehensive guide to navigating the LLM landscape.
From what LLMs are to building and deploying applications with LLMs, we break down—into 7 easy steps—learning all about large language models covering:
- What you should know
- An overview of the concepts
- Learning resources
Let’s get started!
Step 1: Understanding LLM Basics
If you’re new to large language models, it’s helpful to start with a high-level overview of LLMs and what makes them so powerful. Start by trying to answer these questions:
- What are LLMs anyways?
- Why are they so popular?
- How are LLMs different from other deep learning models?
- What are the common LLM use cases? (You’d be familiar with this already; still a good exercise to list them down)
Were you able to answer them all? Well, let’s do it together!
What are LLMs?
Large Language Models—or LLMs—are a subset of deep learning models trained on massive corpus of text data. They’re large—with tens of billions of parameters—and perform extremely well on a wide range of natural language tasks.
Why Are They Popular?
LLMs have the ability to understand and generate text that is coherent, contextually relevant, and grammatically accurate. Reasons for their popularity and wide-spread adoption include:
- Exceptional performance on a wide range of language tasks
- Accessibility and availability of pre-trained LLMs, democratizing AI-powered natural language understanding and generation
So How Are LLMs Different from Other Deep Learning Models?
LLMs stand out from other deep learning models due to their size and architecture, which includes self-attention mechanisms. Key differentiators include:
- The Transformer architecture, which revolutionized natural language processing and underpins LLMs (coming up next in our guide)
- The ability to capture long-range dependencies in text, enabling better contextual understanding
- Ability to handle a wide variety of language tasks, from text generation to translation, summarization and question-answering
What Are the Common Use Cases of LLMs?
LLMs have found applications across language tasks, including:
- Natural Language Understanding: LLMs excel at tasks like sentiment analysis, named entity recognition, and question answering.
- Text Generation: They can generate human-like text for chatbots and other content generation tasks. (Shouldn’t be surprising at all if you’ve ever used ChatGPT or its alternatives).
- Machine Translation: LLMs have significantly improved machine translation quality.
- Content Summarization: LLMs can generate concise summaries of lengthy documents. Ever tried summarizing YouTube video transcripts?
Now that you have a cursory overview of LLMs and their capabilities, here are a couple of resources if you’re interested in exploring further:
Step 2: Exploring LLM Architectures
Now that you know what LLMs are, let’s move on to learning the transformer architecture that underpins these powerful LLMs. So in this step of your LLM journey, Transformers need all your attention (no pun intended).
The original Transformer architecture, introduced in the paper "Attention Is All You Need," revolutionized natural language processing:
- Key Features: Self-attention layers, multi-head attention, feed-forward neural networks, encoder-decoder architecture.
- Use Cases: Transformers are the basis for notable LLMs like BERT and GPT.
The original Transformer architecture uses an encoder-decoder architecture; but encoder-only and decoder-only variants exist. Here’s a comprehensive overview of these along with their features, notable LLMs, and use cases:
| Architecture | Key Features | Notable LLMs | Use Cases |
| Encoder-only | Captures bidirectional context; suitable for natural language understanding |
|
|
| Decoder-only | Unidirectional language model; Autoregressive generation |
|
|
| Encoder-Decoder | Input text to target text; any text-to-text task |
|
|
The following are great resources to learn about transformers:
- Attention Is All You Need (must read)
- The Illustrated Transformer by Jay Alammar
- Module on Modeling from Stanford CS324: Large Language Models
- HuggingFace Transformers Course
Step 3: Pre-training LLMs
Now that you’re familiar with the fundamentals of Large Language Models (LLMs) and the transformer architecture, you can proceed to learn about pre-training LLMs. Pre-training forms the foundation of LLMs by exposing them to a massive corpus of text data, enabling them to understand the aspects and nuances of the language.
Here’s an overview of concepts you should know:
- Objectives of Pre-training LLMs: Exposing LLMs to massive text corpora to learn language patterns, grammar, and context. Learn about the specific pre-training tasks, such as masked language modeling and next sentence prediction.
- Text Corpus for LLM Pre-training: LLMs are trained on massive and diverse text corpora, including web articles, books, and other sources. These are large datasets—with billions to trillions of text tokens. Common datasets include C4, BookCorpus, Pile, OpenWebText, and more.
- Training Procedure: Understand the technical aspects of pre-training, including optimization algorithms, batch sizes, and training epochs. Learn about challenges such as mitigating biases in data.
If you’re interested in learning further, refer to the module on LLM training from CS324: Large Language Models.
Such pre-trained LLMs serve as a starting point for fine-tuning on specific tasks. Yes, fine-tuning LLMs is our next step!
Step 4: Fine-Tuning LLMs
After pre-training LLMs on massive text corpora, the next step is to fine-tune them for specific natural language processing tasks. Fine-tuning allows you to adapt pre-trained models to perform specific tasks like sentiment analysis, question answering, or translation with higher accuracy and efficiency.
Why Fine-Tune LLMs
Fine-tuning is necessary for several reasons:
- Pre-trained LLMs have gained general language understanding but require fine-tuning to perform well on specific tasks. And fine-tuning helps the model learn the nuances of the target task.
- Fine-tuning significantly reduces the amount of data and computation needed compared to training a model from scratch. Because it leverages the pre-trained model's understanding, the fine-tuning dataset can be much smaller than the pre-training dataset.
How to Fine-Tune LLMs
Now let's go over the how of fine-tuning LLMs:
- Choose the Pre-trained LLM: Choose the pre-trained LLM that matches your task. For example, if you're working on a question-answering task, select a pre-trained model with the architecture that facilitates natural language understanding.
- Data Preparation: Prepare a dataset for the specific task you want the LLM to perform. Ensure it includes labeled examples and is formatted appropriately.
- Fine-Tuning: After you’ve chosen the base LLM and prepared the dataset, it’s time to actually fine-tune the model.But how?
Are there parameter-efficient techniques? Remember, LLMs have 10s of billions of parameters. And the weight matrix is huge!
What if you don’t have access to the weights?
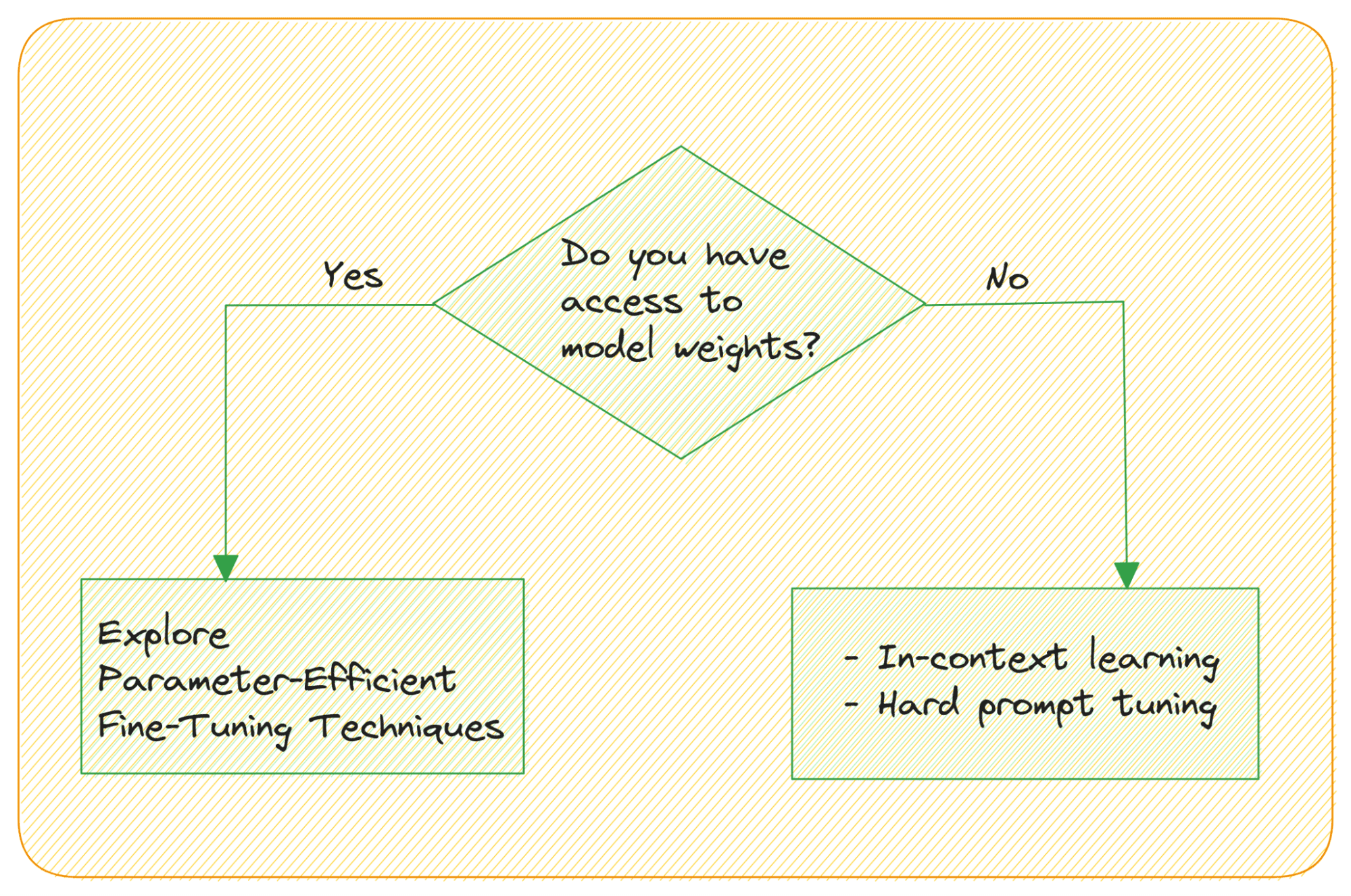
Image by Author
How do you fine-tune an LLM when you don't have access to the model’s weights and accessing the model through an API? Large Language Models are capable of in-context learning—without the need for an explicit fine-tuning step. you can leverage their ability to learn from analogy by providing input; sample output examples of the task.
Prompt tuning—modifying the prompts to get more helpful outputs—can be: hard prompt tuning or (soft) prompt tuning.
Hard prompt tuning involves modifying the input tokens in the prompt directly; so it doesn’t update the model's weights.
Soft prompt tuning concatenates the input embedding with a learnable tensor. A related idea is prefix tuning where learnable tensors are used with each Transformer block as opposed to only the input embeddings.
As mentioned, large language models have tens of billions of parameters. So fine-tuning the weights in all the layers is a resource-intensive task. Recently, Parameter-Efficient Fine-Tuning Techniques (PEFT) like LoRA and QLoRA have become popular. With QLoRA you can fine-tune a 4-bit quantized LLM—on a single consumer GPU—without any drop in performance.
These techniques introduce a small set of learnable parameters—adapters—are tuned instead of the entire weight matrix. Here are useful resources to learn more about fine-tuning LLMs:
- QLoRA is all you need - Sentdex
- Making LLMs even more accessible with bitsandbytes, 4-bit quantization, and QLoRA
Step 5: Alignment and Post-Training in LLMs
Large Language models can potentially generate content that may be harmful, biased, or misaligned with what users actually want or expect. Alignment refers to the process of aligning an LLM's behavior with human preferences and ethical principles. It aims to mitigate risks associated with model behavior, including biases, controversial responses, and harmful content generation.
You can explore techniques like:
- Reinforcement Learning from Human feedback (RLHF)
- Contrastive Post-training
RLHF uses human preference annotations on LLM outputs and fits a reward model on them. Contrastive post-training aims at leveraging contrastive techniques to automate the construction of preference pairs.
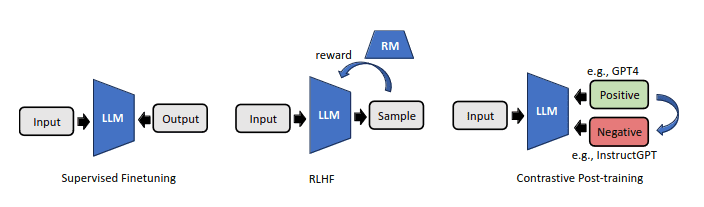
Techniques for Alignment in LLMs | Image Source
To learn more, check out the following resources:
- Illustrating Reinforcement Learning from Human Feedback (RLHF)
- Contrastive Post-training Large Language Models on Data Curriculum
Step 6: Evaluation and Continuous Learning in LLMs
Once you've fine-tuned an LLM for a specific task, it's essential to evaluate its performance and consider strategies for continuous learning and adaptation. This step ensures that your LLM remains effective and up-to-date.
Evaluation of LLMs
Evaluate the performance to assess their effectiveness and identify areas for improvement. Here are key aspects of LLM evaluation:
- Task-Specific Metrics: Choose appropriate metrics for your task. For example, in text classification, you may use conventional evaluation metrics like accuracy, precision, recall, or F1 score. For language generation tasks, metrics like perplexity and BLEU scores are common.
- Human Evaluation: Have experts or crowdsourced annotators assess the quality of generated content or the model's responses in real-world scenarios.
- Bias and Fairness: Evaluate LLMs for biases and fairness concerns, particularly when deploying them in real-world applications. Analyze how models perform across different demographic groups and address any disparities.
- Robustness and Adversarial Testing: Test the LLM's robustness by subjecting it to adversarial attacks or challenging inputs. This helps uncover vulnerabilities and enhances model security.
Continuous Learning and Adaptation
To keep LLMs updated with new data and tasks, consider the following strategies:
- Data Augmentation: Continuously augment your data store to avoid performance degradation due to lack of up-to-date info.
- Retraining: Periodically retrain the LLM with new data and fine-tune it for evolving tasks. Fine-tuning on recent data helps the model stay current.
- Active Learning: Implement active learning techniques to identify instances where the model is uncertain or likely to make errors. Collect annotations for these instances to refine the model.
Another common pitfall with LLMs is hallucinations. Be sure to explore techniques like Retrieval augmentation to mitigate hallucinations.
Here are some helpful resources:
Step 7: Building and Deploying LLM Apps
After developing and fine-tuning an LLM for specific tasks, start building and deploying applications that leverage the LLM's capabilities. In essence, use LLMs to build useful real-world solutions.
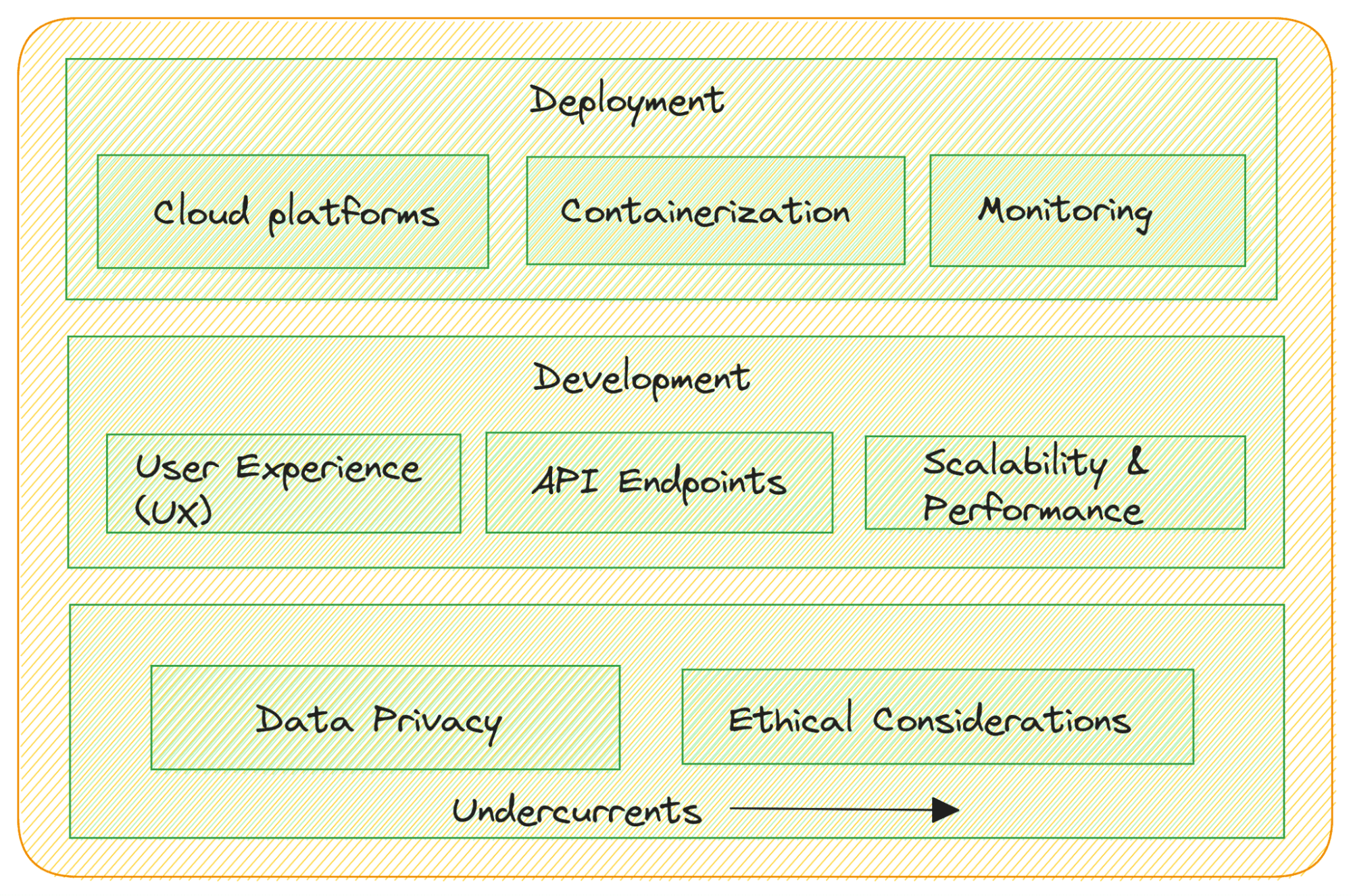
Image by Author
Building LLM Applications
Here are some considerations:
- Task-Specific Application Development: Develop applications tailored to your specific use cases. This may involve creating web-based interfaces, mobile apps, chatbots, or integrations into existing software systems.
- User Experience (UX) Design: Focus on user-centered design to ensure your LLM application is intuitive and user-friendly.
- API Integration: If your LLM serves as a language model backend, create RESTful APIs or GraphQL endpoints to allow other software components to interact with the model seamlessly.
- Scalability and Performance: Design applications to handle different levels of traffic and demand. Optimize for performance and scalability to ensure smooth user experiences.
Deploying LLM Applications
You’ve developed your LLM app and are ready to deploy them to production. Here’s what you should consider:
- Cloud Deployment: Consider deploying your LLM applications on cloud platforms like AWS, Google Cloud, or Azure for scalability and easy management.
- Containerization: Use containerization technologies like Docker and Kubernetes to package your applications and ensure consistent deployment across different environments.
- Monitoring: Implement monitoring to track the performance of your deployed LLM applications and detect and address issues in real time.
Compliance and Regulations
Data privacy and ethical considerations are undercurrents:
- Data Privacy: Ensure compliance with data privacy regulations when handling user data and personally identifiable information (PII).
- Ethical Considerations: Adhere to ethical guidelines when deploying LLM applications to mitigate potential biases, misinformation, or harmful content generation.
You can also use frameworks like LlamaIndex and LangChain to help you build end-to-end LLM applications. Some useful resources:
Wrapping Up
We started our discussion by defining what large language models are, why they are popular, and gradually delved into the technical aspects. We’ve wrapped up our discussion with building and deploying LLM applications requiring careful planning, user-focused design, robust infrastructure, while prioritizing data privacy and ethics.
As you might have realized, it’s important to stay updated with the recent advances in the field and keep building projects. If you have some experience and natural language processing, this guide builds on the foundation. Even if not, no worries. We’ve got you covered with our 7 Steps to Mastering Natural Language Processing guide. Happy learning!
Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she's working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more. Bala also creates engaging resource overviews and coding tutorials.