A Better Way To Evaluate LLMs
This article introduces a new approach to evaluation LLMs, which leverages human insight to compare LLM responses to real-world user prompts categorized by NLP tasks, offering a promising solution for advancing LLM evaluation standards.
Introduction to LLM evaluation
Recent advances in the development of LLMs have popularized their usage for diverse NLP tasks that were previously tackled using older machine learning methods. Large language models are capable of solving a variety of language problems such as classification, summarization, information retrieval, content creation, question answering, and maintaining a conversation — all using just one single model. But how do we know they are doing a good job on all these different tasks?
The rise of LLMs has brought to light an unresolved problem: we don’t have a reliable standard for evaluating them. What makes evaluation harder is that they are used for highly diverse tasks and we lack a clear definition of what is a good answer for each use case.
This article discusses current approaches to evaluating LLMs and introduces a new LLM leaderboard leveraging human evaluation that improves upon existing evaluation techniques.
Current Approaches and Leaderboards
The first and usual initial form of evaluation is to run the model on several curated datasets and examine its performance. HuggingFace created an Open LLM Leaderboard where open-access large models are evaluated using four well-known datasets (AI2 Reasoning Challenge , HellaSwag , MMLU , TruthfulQA). This corresponds to automatic evaluation and checks the model's ability to get the facts for some specific questions.
This is an example of a question from the MMLU dataset.
Subject: college_medicine
Question: An expected side effect of creatine supplementation is.
- A) muscle weakness
- B) gain in body mass
- C) muscle cramps
- D) loss of electrolytes
Answer: (B)
Scoring the model on answering this type of question is an important metric and serves well for fact-checking but it does not test the generative ability of the model. This is probably the biggest disadvantage of this evaluation method because generating free text is one of the most important features of LLMs.
There seems to be a consensus within the community that to evaluate the model properly we need human evaluation. This is typically done by comparing the responses from different models.
Comparing two prompt completions in the LMSYS project - screenshot by the Author
Annotators decide which response is better, as seen in the example above, and sometimes quantify the difference in quality of the prompt completions. LMSYS Org has created a leaderboard that uses this type of human evaluation and compares 17 different models, reporting the Elo rating for each model.
Because human evaluation can be hard to scale, there have been efforts to scale and speed up the evaluation process and this resulted in an interesting project called AlpacaEval. Here each model is compared to a baseline (text-davinci-003 provided by GPT-4) and human evaluation is replaced with GPT-4 judgment. This indeed is fast and scalable but can we trust the model here to perform the scoring? We need to be aware of model biases. The project has actually shown that GPT-4 may favor longer answers.
LLM evaluation methods are continuing to evolve as the AI community searches for easy, fair, and scalable approaches. The latest development comes from the team at Toloka with a new leaderboard to further advance current evaluation standards.
Using Humans to Evaluate LLMs - A New Approach
The new leaderboard compares model responses to real-world user prompts that are categorized by useful NLP tasks as outlined in this InstructGPT paper. It also shows each model’s overall win rate across all categories.
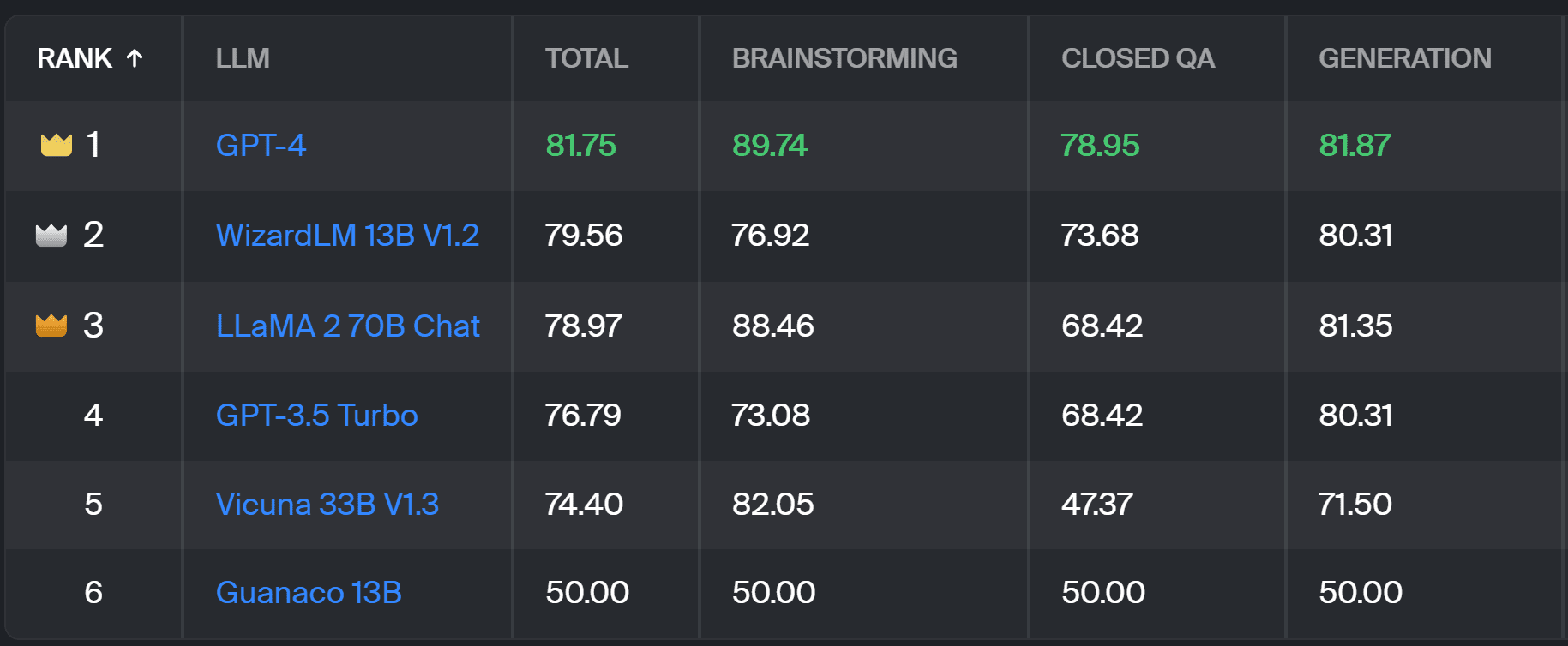
Toloka leaderboard - screenshot by the Author
The evaluation used for this project is similar to the one performed in AlpacaEval. The scores on the leaderboard represent the win rate of the respective model in comparison to the Guanaco 13B model, which serves here as a baseline comparison. The choice of Guanaco 13B is an improvement to the AlpacaEval method, which uses the soon-to-be outdated text-davinci-003 model as the baseline.
The actual evaluation is done by human expert annotators on a set of real-world prompts. For each prompt, annotators are given two completions and asked which one they prefer. You can find details about the methodology here.
This type of human evaluation is more useful than any other automatic evaluation method and should improve on the human evaluation used for the LMSYS leaderboard. The downside of the LMSYS method is that anybody with the link can take part in the evaluation, raising serious questions about the quality of data gathered in this manner. A closed crowd of expert annotators has better potential for reliable results, and Toloka applies additional quality control techniques to ensure data quality.
Summary
In this article, we have introduced a promising new solution for evaluating LLMs — the Toloka Leaderboard. The approach is innovative, combines the strengths of existing methods, adds task-specific granularity, and uses reliable human annotation techniques to compare the models.
Explore the board, and share your opinions and suggestions for improvements with us.
Magdalena Konkiewicz is a Data Evangelist at Toloka, a global company supporting fast and scalable AI development. She holds a Master's degree in Artificial Intelligence from Edinburgh University and has worked as an NLP Engineer, Developer, and Data Scientist for businesses in Europe and America. She has also been involved in teaching and mentoring Data Scientists and regularly contributes to Data Science and Machine Learning publications.