A (Much) Better Approach to Evaluate Your Machine Learning Model
Using one or two performance metrics seems sufficient to claim that your ML model is good — chances are that it’s not.
It’s crazy how difficult it can be for Data Scientists like myself to evaluate ML models using classic performance metrics properly.
Even with access to multiple metrics and scoring methods, it is still challenging to understand the right metrics for the problems I — and likely many others — am facing. This is exactly why I use Snitch AI for most of my ML model quality evaluation. PS — I’ve been an active member of developing Snitch AI for the past 2 years.
Machine Learning Model Validation Tool | Snitch AI
Let me explain why selecting the right metric is so important with an example: the generation of a model that can predict company bankruptcy using data centralized on the UC Irvine Machine Learning Repository. The dataset is called Taiwanese Bankruptcy Prediction (licensed under CC BY 4.0) and leverages bankruptcy data from the Taiwan Economic Journal from 1999 to 2009.
The problem: Imbalanced Dataset
The first problem that you will encounter is the imbalance in the dataset. It’s both good news and bad news. The good news is that only 3.3% of companies went bankrupt! On the flip side, the bad news is that the imbalance in the dataset makes it more difficult to predict the “rare class” (the 3.3%), as our lazy models could predict the right fate for 96.7% of the companies by simply predicting no bankruptcies.
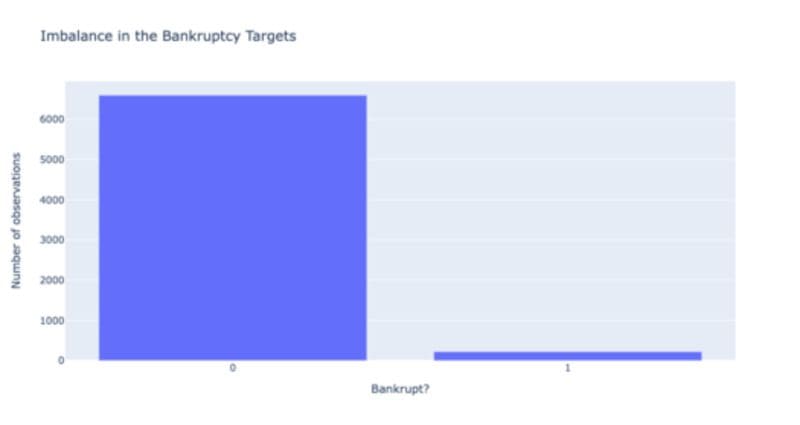
Target imbalance assessment by Author
You can see that this is also a performance evaluation problem as most metrics are biased towards the biggest class, ultimately making them wrong. Why? predicting no bankruptcies makes our model 96.7% accurate in theory. Here is an example of the first model that was built and evaluated in Snitch AI. The tool calculates multiple relevant performance metrics by default. As you can see below, our first model gets 96% accuracy. However, when you look at the F1 score, a better metric for imbalanced classes, I get a score of barely 26%…

Image of initial quality analysis by Author
So what gives?
The Solution for Imbalanced Datasets
When dealing with imbalanced data, a good practice is to try to get the training dataset more balanced as a second step. You can achieve that by either under-sampling the majority class (no-bankruptcy), by removing random observations, or by oversampling the minority class (bankruptcy).
For over-sampling, you can either copy random observations or create synthetic observations using proven algorithms like Synthetic Minority Oversampling TEchnique. SMOTE works by selecting examples that are close, drawing a line between the examples, and drawing a new sample at a point along that line.
As you can see, there are many techniques I can end up using to enhance my model.
With Snitch, I can see a clean history of my various experiments :
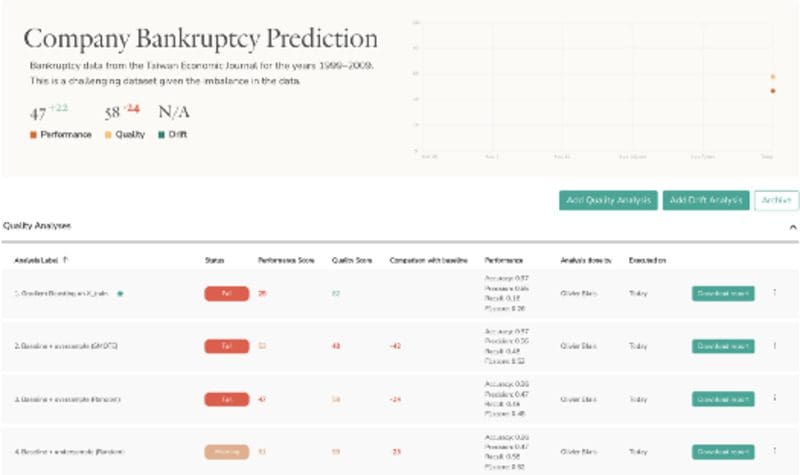
Image of multiple quality analysis by Author
Here are some conclusions I learned from the experiments above:
- Undersampling and oversampling techniques significantly enhance the F1 score. This is a good thing!
- However, this performance gain is at the expense of the overall quality of our models.
- Our model 4 (Gradient Boosting with under-sampling) is the best model, as it is almost as performant as model 2, but is generally of better quality.
Wait! What’s this “Quality Score”?
Snitch uses about a dozen automated quality analyses to generate this Quality Score.
The Quality Analysis produces:
- The Feature Contribution Score: to check whether your model’s predictions are biased or fairly distributed between the input variables.
- The Random Noise Robustness Score: to check if your model is robust to the introduction of noisy data.
- The Extreme Noise Robustness Score: to check if your model is robust to the introduction of worst-case scenario noisy data.
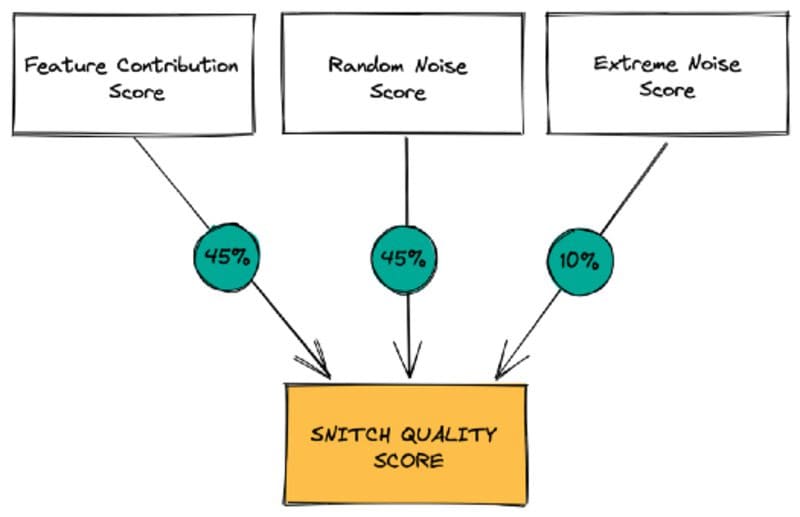
Image from Snitch AI quality analysis methodology, 2021. Reposted with permission
Performance evaluation is hard
Nothing good comes easy, and performance evaluation is no different. While tricky to get right, performance evaluation needs to be taken seriously while developing your models. It’s not because you have a good accuracy that your model is a good one.
The truth is, accuracy might not even be a relevant measure of performance. In our case, the F1 score was definitely better as our dataset was imbalanced. The lesson here is simple. Make sure you validate that the metrics you selected properly measure what you’re trying to achieve.
Although performance metrics are important (they are about measuring how well your model predicts the outcome after all), these metrics do not validate data biases or the overall robustness of your model. A good practice here is to specifically test for other characteristics such as biases and robustness.
We saw that some models can perform better than other models in theory but are in fact of poorer quality. We also saw models that are performing badly but that are of better quality. At the end of the day, the goal is to be able to compare these signals to select the best approach.
Remember, a better approach should not only focus on estimating your model’s performance, it actually requires in-depth testing to make sure your system is robust as well so that it will actually work on new data in production… this is where the magic needs to happen!
Olivier Blais is co-founder and Head of Decision Science at Moov AI. He’s also a member of the Standards Council of Canada committee that is defining the ISO standards for artificial intelligence solutions where he leads initiatives on quality evaluation guidelines for AI Systems.
Original. Reposted with permission.