Vector Databases in AI and LLM Use Cases
Learn about Vectors and How Storing Data Can Be Used in LLM Applications.

Image generated with Ideogram.ai
So, you might hear all these Vector Database terms. Some might understand about it, and some might not. No worries if you don’t know about them, as Vector Databases have only become a more prominent topic in recent years.
Vector databases have risen in popularity thanks to the introduction of Generative AI to the public, especially the LLM.
Many LLM products, such as GPT-4 and Gemini, help our work by providing text generation capability for our input. Well, vector databases actually play a part in these LLM products.
But How did Vector Database work? And what are their relevances in the LLM?
The question above is what we would answer in this article. Well, Let’s explore them together.
Vector Databases
A vector database is a specialized database storage designed to store, index, and query vector data. It’s often optimized for high-dimensional vector data as usually it is the output for the machine learning model, especially LLM.
In the context of a Vector Database, the vector is a mathematical representation of the data. Each vector consists of an array of numerical points representing the data position. Vector is often used in the LLM to represent the text data as a vector is easier to process than the text data.
In the LLM space, the model might have a text input and could transform the text into a high-dimensional vector representing the semantic and syntactic characteristics of the text. This process is what we call Embedding. In simpler terms, embedding is a process that transforms text into vectors with numerical data.
Embedding generally uses a Neural Network model called the Embedding Model to represent the text in the Embedding Space.
Let’s use an example text: “I Love Data Science”. Representing them with the OpenAI model text-embedding-3-small would result in a vector with 1536 dimensions.
[0.024739108979701996, -0.04105354845523834, 0.006121257785707712, -0.02210472710430622, 0.029098540544509888,...]
The number within the vector is the coordinate within the model’s embedding space. Together, they would form a unique representation of the sentence meaning coming from the model.
Vector Database would then be responsible for storing these embedding model outputs. The user then could query, index, and retrieve the vector as they need.
Maybe that’s enough introduction, and let’s get into a more technical hands-on. We would try to establish and store vectors with an open-source vector database called Weaviate.
Weaviate is a scalable open-source Vector Database that serves as a framework to store our vector. We can run Weaviate in instances like Docker or use Weaviate Cloud Services (WCS).
To start using Weaviate, we need to install the packages using the following code:
pip install weaviate-client
To make things easier, we would use a sandbox cluster from WCS to act as our Vector Database. Weaviate provides a 14-day free cluster that we can use to store our vectors without registering any payment method. To do that, you need to register on their WCS console initially.
Once within the WCS platform, select Create a Cluster and input your Sandbox name. The UI should look like the image below.
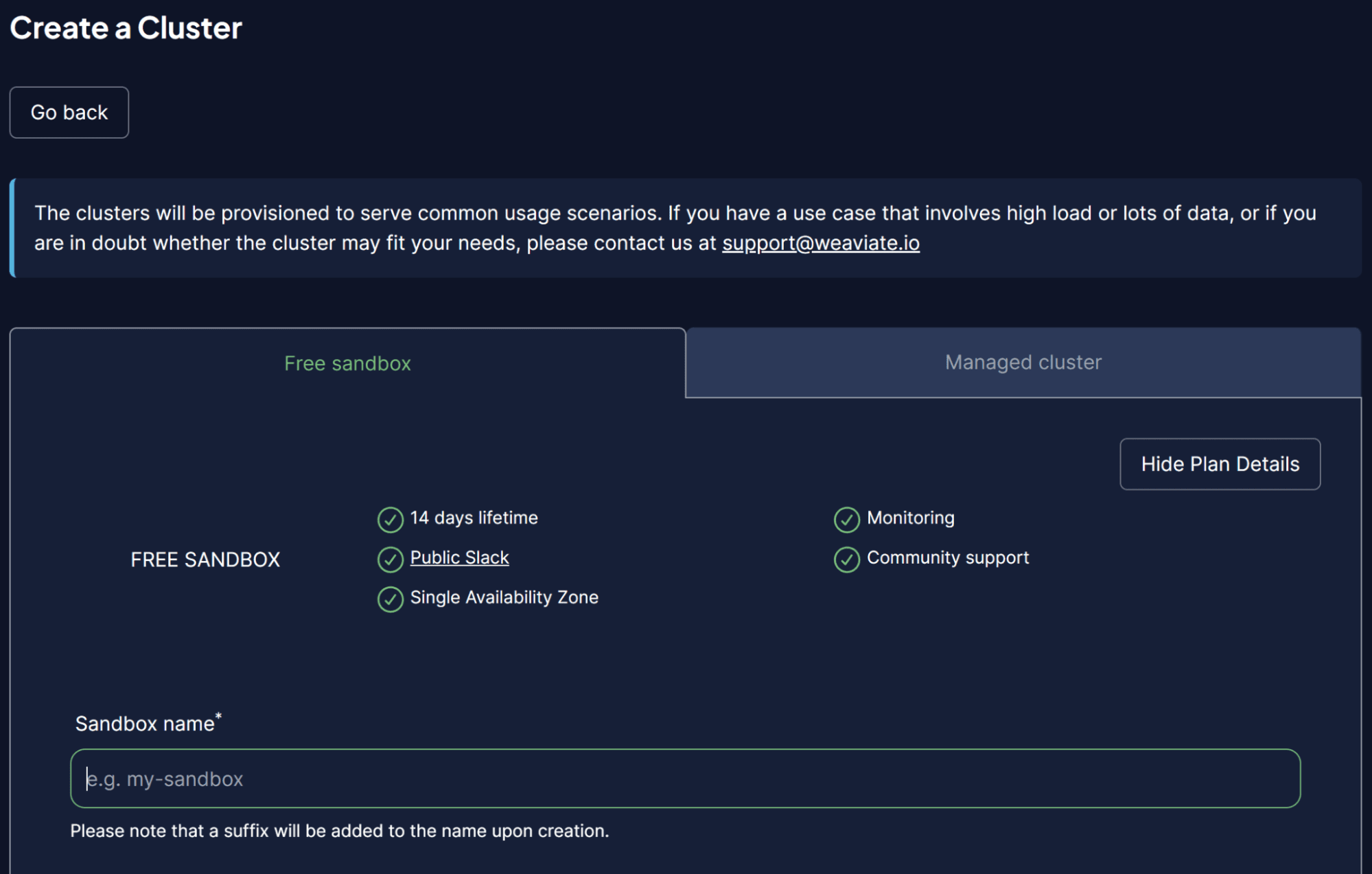
Image by Author
Don’t forget to enable authentication, as we also want to access this cluster via the WCS API Key. After the cluster is ready, find the API key and Cluster URL, which we will use to access the Vector Database.
Once things are ready, we would simulate storing our first vector in the Vector Database.
For the Vector Database storing example, I would use the Book Collection example dataset from Kaggle. I would only use the top 100 rows and 3 columns (title, description, intro).
import pandas as pd
data = pd.read_csv('commonlit_texts.csv', nrows = 100, usecols=['title', 'description', 'intro'])
Let’s set aside our data and connect to our Vector Database. First, we need to set up a remote connection using the API key and your Cluster URL.
import weaviate
import os
import requests
import json
cluster_url = "Your Cluster URL"
wcs_api_key = "Your WCS API Key"
Openai_api_key ="Your OpenAI API Key"
client = weaviate.connect_to_wcs(
cluster_url=cluster_url,
auth_credentials=weaviate.auth.AuthApiKey(wcs_api_key),
headers={
"X-OpenAI-Api-Key": openai_api_key
}
)
Once you set up your client variable, we will connect to the Weaviate Cloud Service and create a class to store the vector. Class in Weaviate is the data collection or analogs to the table name in a relational database.
import weaviate.classes as wvc
client.connect()
book_collection = client.collections.create(
name="BookCollection",
vectorizer_config=wvc.config.Configure.Vectorizer.text2vec_openai(),
generative_config=wvc.config.Configure.Generative.openai()
)
In the code above, we connect to the Weaviate Cluster and create a BookCollection class. The class object also uses the OpenAI text2vec embedding model to vectorize the text data and OpenAI generative module.
Let’s try to store the text data in a vector database. To do that, you can use the following code.
sent_to_vdb = data.to_dict(orient='records')
book_collection.data.insert_many(sent_to_vdb)
Image by Author
We just successfully stored our dataset in the Vector Database! How easy is that?
Now, you might be curious about the use cases for using Vector Databases with LLM. That’s what we are going to discuss next.
Vector Database and LLM Use Cases
A few use cases in which LLM can be applied with Vector Database. Let’s explore them together.
Semantic Search
Semantic Search is a process of searching for data by using the meaning of the query to retrieve relevant results rather than relying solely on the traditional keyword-based search.
The process involves the utilization of the LLM Model Embedding of the query and performing embedding similarity search into our stored embedded in the vector database.
Let’s try to use Weaviate to perform a semantic search based on a specific query.
book_collection = client.collections.get("BookCollection")
client.connect()
response = book_collection.query.near_text(
query="childhood story,
limit=2
)
In the code above, we try to perform a semantic search with Weaviate to find the top two books closely related to the query childhood story. The semantic search uses the OpenAI embedding model we previously set up. The result is what you can see in below.
{'title': 'Act Your Age', 'description': 'A young girl is told over and over again to act her age.', 'intro': 'Colleen Archer has written for \nHighlights\n. In this short story, a young girl is told over and over again to act her age.\nAs you read, take notes on what Frances is doing when she is told to act her age. '}
{'title': 'The Anklet', 'description': 'A young woman must deal with unkind and spiteful treatment from her two older sisters.', 'intro': "Neil Philip is a writer and poet who has retold the best-known stories from \nThe Arabian Nights\n for a modern day audience. \nThe Arabian Nights\n is the English-language nickname frequently given to \nOne Thousand and One Arabian Nights\n, a collection of folk tales written and collected in the Middle East during the Islamic Golden Age of the 8th to 13th centuries. In this tale, a poor young woman must deal with mistreatment by members of her own family.\nAs you read, take notes on the youngest sister's actions and feelings."}
As you can see, no direct words about childhood stories are in the result above. However, the result is still closely related to a story that aims for children.
Generative Search
The Generative Search could be defined as an extension application for the Semantic Search. The Generative Search, or Retrieval Augmented Generation (RAG), utilizes LLM prompting with the Semantic search that retrieved data from the vector database.
With RAG, the result from the query search is processed to LLM, so we get them in the form we want instead of the raw data. Let’s try a simple implementation of the RAG with Vector Database.
response = book_collection.generate.near_text(
query="childhood story",
limit=2,
grouped_task="Write a short LinkedIn post about these books."
)
print(response.generated)
The result can be seen in the text below.
Excited to share two captivating short stories that explore themes of age and mistreatment. "Act Your Age" by Colleen Archer follows a young girl who is constantly told to act her age, while "The Anklet" by Neil Philip delves into the unkind treatment faced by a young woman from her older sisters. These thought-provoking tales will leave you reflecting on societal expectations and family dynamics. #ShortStories #Literature #BookRecommendations 📚
As you can see, the data content is the same as before but has now been processed with OpenAI LLM to provide a short LinkedIn post. In this way, RAG is useful when we want specific form output from the data.
Question Answering with RAG
In our previous example, we used a query to get the data we wanted, and RAG processed that data into the intended output.
However, we can turn the RAG capability into a question-answering tool. We can achieve this by combining them with the LangChain framework.
First, let’s install the necessary packages.
pip install langchain
pip install langchain_community
pip install langchain_openai
Then, let’s try to import the packages and initiate the variables we require to make QA with RAG work.
from langchain.chains import RetrievalQA
from langchain_community.vectorstores import Weaviate
import weaviate
from langchain_openai import OpenAIEmbeddings
from langchain_openai.llms.base import OpenAI
llm = OpenAI(openai_api_key = openai_api_key, model_name = 'gpt-3.5-turbo-instruct', temperature = 1)
embeddings = OpenAIEmbeddings(openai_api_key = openai_api_key )
client = weaviate.Client(
url=cluster_url, auth_client_secret=weaviate.AuthApiKey(wcs_api_key)
)
In the code above, we set up the LLM for the text generation, embedding model, and the Weaviate client connection.
Next, we set the Weaviate connection to the Vector Database.
weaviate_vectorstore = Weaviate(client=client, index_name='BookCollection', text_key='intro',by_text = False, embedding=embeddings)
retriever = weaviate_vectorstore.as_retriever()
In the code above, make the Weaviate Database BookCollection the RAG tool that would search the ‘intro’ feature when prompted.
Then, we would create Question Answering Chain from the LangChain with the code below.
qa_chain = RetrievalQA.from_chain_type(
llm=llm, chain_type="stuff", retriever = retriever
)
Everything is now ready. Let’s try out the QA with RAG using the following code example.
response = qa_chain.invoke(
"Who is the writer who write about love between two goldfish?")
print(response)
The result is shown in the text below.
{'query': 'Who is the writer who write about love between two goldfish?', 'result': ' The writer is Grace Chua.'}
With the Vector Database as the place to store all the text data, we can implement RAG to perform QA with LangChain. How neat is that?
Conclusion
A vector database is a specialized storage solution designed to store, index, and query vector data. It is often used to store text data and implemented in conjunction with Large Language Models (LLMs). This article will try a hands-on setup of the Vector Database Weaviate, including example use cases such as Semantic Search, Retrieval-Augmented Generation (RAG), and Question Answering with RAG.
Cornellius Yudha Wijaya is a data science assistant manager and data writer. While working full-time at Allianz Indonesia, he loves to share Python and data tips via social media and writing media. Cornellius writes on a variety of AI and machine learning topics.