Contest 2nd Place: Automated Data Science and Machine Learning in Digital Advertising
This post is an overview of an automated machine learning system in the digital advertising realm. It is an entrant and second-place recipient in the recent KDnuggets blog contest.
By Claudia Perlich and Dstillery Data Science Team.
Editor's note: This blog post was an entrant in the recent KDnuggets Automated Data Science and Machine Learning blog contest, where it tied for second place.
Digital Advertising provides an exciting playground for machine learning in general and automated predictive modeling in particular. An increasing proportion of digital advertising is delivered through real-time bidding ad exchanges. Ad exchanges connect sellers of ad placements (usually websites with ad space to monetize) and buyers (usually technology firms like Dstillery, operating on behalf of consumer brands and agencies).
The goals of the buyers vary. At Dstillery, our goal is to identify the best audience for each of our advertising clients, and deliver ads to this audience. The “best” audience depends on the goals of the advertiser, but we typically optimize toward post-view conversion. The meaning of “conversion” is campaign-specific, but always requires taking some consumer action, such as visiting a site, buying a product, or signing up for a service. The post-view qualifier means the conversion is observed in some interval following an ad exposure, either with or without a click.
We run completely separate targeting models for each brand we represent. As a result, our machine learning system updates and deploys thousands of predictive models daily. Our clients’ diverse performance requirements, along with the need to keep so many models running effectively, pose a number of interesting technical challenges. The remainder of this article describes a combination of strategies we employ at Dstillery for keeping our targeting system running with minimal human intervention.1
High-level system design
There is a great deal of infrastructure supporting our actual predictive modeling engine. Data ingestion, normalization, sampling and cleaning are all done in an automated fashion with one clear goal: building thousands of sparse models daily that are good at classifying brand prospects along a wide variety of products.
Sampling the Event Stream
Dstillery has developed a robust data sampling solution that can sample a real-time event stream based on any properties of the event, performing a customizable set of tasks on each accepted observation.
On the average day, over 50 billion events pass through our system. These events can be bid requests, impressions, visits to a specific website, uses of a mobile app or thousands of other types of actions from Internet-connected devices. The sampler dynamically chooses among the events that based on sampling rules that we define. This portion of the system is seen in pink in Figure 1, Extensible Rules Engine.
Event Data Augmentation by Sampler
For each sampled observation, the sampler performs a set of tasks, which can include logging the event to a number of databases or fetching additional data about a device. The User History Augmentation and Scoring System seen in Figure 1 includes a wide variety of tasks. Oneexample would be selecting mobile devices identified via GPS coordinates at a place of interest (e.g., a McDonald's or a Pokemon-Go location), and augmenting those events with the historic places the device was seen.

In data domains that only include thousands or even millions of observations, histories can be recreated from scratch by doing full scans of the data. However, with billions of data points, full scans are not computationally feasible. That is why the system is designed to augment additional historical data at the time of sampling (center of Figure 1) by accessing these histories in multiple Cassandra-based key-value stores. This enables the learning of models based on long histories of a user’s past actions without having to scan months of full data records.
The processing system defined above is extremely flexible and allows for the sampling of data for specific machine learning tasks, as seen in the Seed Sampler in Figure 1. Histories, or features, can then be fetched at sampling time during the augmentation process. These data can then be consumed by the machine learning system,2 which stores the results of thousands of models a day in the Brand Signal Repository in Figure 1. An alternative sampling task can be kicked off that determines when a device should be scored for the models. Finally these scores can be used to bid on opportunities in the execution layer.
Automated learning of robust ranking models
Let’s focus now on the specific task of learning one good ranking model for a given campaign automatically. The specific challenges here are:
- Cold start. Targeting must perform well from the beginning of a campaign, even though there may be very little outcome data.
- Low base rate. Conversion rates can easily be below 1 in 100,000.
- Non-stationarity. Changes in behavior over time due to natural seasonality and campaign-specific external factors.
- Consistency and robustness. Unique models for each campaign must perform despite disparities in type of product, conversion rate and audience size.
Our current system addresses these issues with a number of different components, drawing from transfer, ensemble learning, adaptive regularization, and streaming updates.
Sampling, Transfer Learning & Stacking
Both the cold start and the low base rate are addressed by a number of adjustments to the sampling (see above) and definition of ‘positive’. In addition to trying to capitalize on each and every conversion event (purchase of a product, signup for a service) even without an impression, we use additional related events (visiting the homepage) as alternative target variables. These many different models for a given marketer are blended in an ensemble type model layer with much reduced dimensionality.3
Streaming and Stochastic Gradient Descent
Streaming model updates (using a last known good model and update based on the training data collected since the last training iteration) provides a great solution for non-stationarity and low data retention. Streaming is most easily implemented in parametric models like logistic/linear regression, using stochastic gradient descent (SGD). Another huge benefit of linear modeling in our context is the simplicity of transitioning models from training to production and high volume scoring. Recent developments in adaptive learning rate schedules and adaptive regularization allow for incremental training of linear models in millions of dimensions without exhaustive hyper-parameter searching. 4 Finally, the combination of gradient descent and penalty terms helps to avoid overfitting, provides robustness and avoids feature selection.
Hashing of Binary Indicators
One of the key challenges in automating both model training and scoring in a dynamic, high-dimensional environment is providing a consistent definition of the feature space. Many of our models are based on web history, and the set of URL’s in our event stream is constantly changing as new ones appear and others lose traffic. By hashing all URL’s into a space of fixed dimensionality, we allow our automated model-builders to operate in a static, consistent feature space even though the semantic meaning of a feature may change over time.
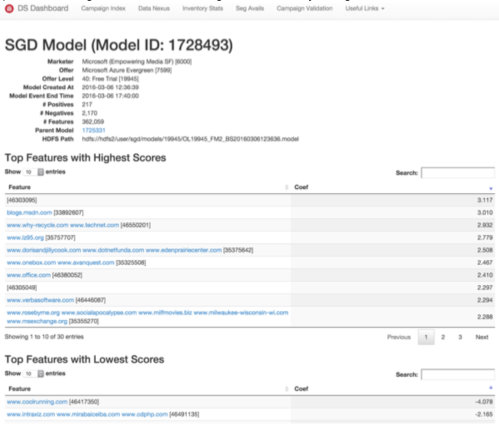
Whenever multiple URL’s are in a line the hash has caused a collision, whenever no URL is presented, the data was pre-hashed for privacy reasons.
Conclusion
Drawing from a number of techniques in machine learning and data engineering, it is possible to automate a full model creation, scoring, and execution framework. The outlined technology is supported by a 13-person data science team and enables the execution of hundreds of digital campaigns with high performance simultaneously.
References:
1 For a more detailed description of the system and the process used for building many models at scale see: Raeder, Troy, et al. "Design principles of massive, robust prediction systems." Proceedings of the 18th ACM SIGKDD international conference on knowledge discovery and data mining. ACM, 2012.
2 Details on the machine learning methods are described in the following section.
3 C. Perlich, B. Dalessandro, T. Raeder, O. Stitelman, and F. Provost. Machine learning for targeted display advertising: Transfer learning in action. Machine Learning, pages 1–25, 2013.
4 Brian Dalessandro, Daizhuo Chen, Troy Raeder, Claudia Perlich, Melinda Han Williams, and Foster Provost. 2014. Scalable hands-free transfer learning for online advertising. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining (KDD '14)
About: Dstillery is a data analytics company that uses machine learning and predictive modeling to provide intelligent solutions for brand marketing and other business challenges. Drawing from a unique 360 degree view of digital, physical and offline activity, we generate insights and predictions about the behaviors of individuals and discrete populations.
Related: