Viewpoint: Why your company should NOT use “Big Data”
Hardcore analytics (and Big Data) can add value, but only marginally and only for companies that have already mastered using the data they already have. The ‘obvious’ information from your own data can get you 90%+ of the total impact, so start there. The hard part is executing the basic insights across the organization.
Guest post by Edward Nevraumont, Jan 2014.
We have all heard the cliché of the 80/20 principle: 80% of impact comes from 20% of effort (or 20% of your customers provide 80% of your revenue. In actual practice everywhere I’ve looked it is usually closer to the “70/30 principle”, but the concept still applies). Regardless of the actual numbers, the principle is rarely applied to marketing activities.
The latest trend is “Big Data”. The original concept of Big Data was the concept of using all of the information a company collect that was being thrown away due to costs and capacity constraints. With the rapidly declining cost of storage and retrieval, combined with machine learning, we should be able to find insights in all that ‘garbage data’ and use it to make better decisions in the core business. At least that’s the theory. As far as the basic theory goes it’s all true, but it’s not the full story.
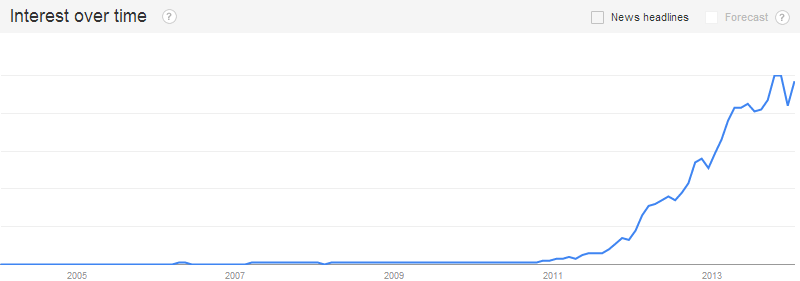
Like a lot of trends, the drive to mastering Big Data has gone a little overboard. Google searches for the term “Big Data” has grown from practically nothing in 2010 to almost 200,000 searches a month by the end of 2013 [see chart from Google Trends below], and people selling products and services have caught on (The suggested Paid Search Bid for the term “Big Data” is now over $9 per click. To put into perspective the term “Las Vegas Hotels” only has a suggested bid of $3.71, and that term is far more action oriented than the generic “Big Data”). Products or services that were once described as analytic or database or statistical four years ago has suddenly morphed into “Big Data Solutions” (I’ve heard Nate Silver’s work been described as “Big Data”. Mr. Silver does straightforward statistical analysis and communicates it in a compelling way. But he is not, at least in his popular blog, doing “Big Data”). Consulting firms pitch their ability to help companies “leverage” their “Big Data”. It has become so ingrained in company cultures that to say you don’t want to use Big Data is a bit like saying you are against data-driven decision making. It would be career suicide to say Big Data is a waste of company time and resources.
But that’s exactly what I am going to do.
I am not going to argue that Big Data when done properly cannot create value. What I will argue is that if you are not already dominating your field and mastered all of the basics, then any dive into Big Data is just chasing a trend and a waste of your team’s time.
I think the best way for me to drive home the argument is with a series of examples.
Why Sales Does Not Need Big Data
Recently the head of sales and marketing for Fortune 500 company asked me how he should best use the browsing history of his customers to determine the priority of sales follow-up calls. This is a classic example of Big Data – its data that was being collected (somewhere) and thrown away. And that data could definitely tell us something more than we know right now. Sounds like a no brainer, right? He thought so.
I told him not to bother.
There are three reasons why (As an alumni of McKinsey I have learned there are always exactly three reasons for just about everything):
Let’s start with #3.
Here is what I told him I would do if I was in his shoes:
First, understand what your current follow-up procedure is. Do you have a standardized follow-up protocol that has high compliance across your entire organization, or is every location doing it their own way? The answer was the latter. If you haven’t standardized the basic flow, then what are you going to do with the new information you get from the Big Data? Are you just going to share it with the field and hope they all use it the way you want them to? Are you going to take that data with a bunch of other stuff you have and try to change the way each location is operating.
I would imagine the hope is that you will find some insights and then find a way to implement them. But the issue is you haven’t proven that you can get a standardized program implemented now. What makes you think you can get a standardized method with Big Data implemented? If you can’t you have just wasted all the time you spent getting the data. You are left with an insight that doesn’t drive any impact.
Instead, Step One needs to be: Find out which parts of your sales organization are most effective. Really understand what they are doing. Then create a program to roll out that effective method across the entire organization.
This should be easy in theory, but it is hard in practice. Hard or easy though it is absolutely essential to get the program right before you start trying to do the hard theory on top of it.
OK. So now you’ve done that (or someone else did it before you came along). You have a well-functioning sales organization with standardized procedures that steals from your best 10% of sales people and apples it to your entire company. Now you are ready to apply Big Data, right?
Not yet.
The next step, before you go and get more data is to look at what you already have and see if you can find what the big drivers of performance are. They are there and they are almost always obvious. In this case the organization collected a wide variety of information from any given lead well before a sale happened. Someone in your organization should be able to do a series of simple logistical regressions to see which characteristics are most predictive of a sale.
Want to know what the magic bullets were for this company? Get your pen ready:
#1: How long has it been since the lead first came to the team.
It turns out that leads go stale over time. 90% of their sales came from leads that were less than 12 months old. 50% from leads less than 3 months old. This isn’t rocket science, but an easy first insight is: Stay in touch with, and put more effort into, your new leads.
#2: Is the lead’s budget for your product high enough to pay for the product you are selling?
If the lead says they can’t afford you, it turns out they (usually) can’t. Or to put another way, the lead who says he can afford you is more likely to buy your product.
#3: They answer “soon” to the question: “How soon do you plan on making a purchase?”
When people say they need to buy right away, not only do they often need to buy right away, but they are also more likely to buy ever.
You might have been able to guess all three of these (or one of your top sales people might) or you might not. But it doesn’t matter. You definitely don’t need big data to find these insights.
The next question is: Are you using those three insights now to manage your sales funnels?
In this case the answer was “No.”
So step two is: “Do that.”
Create a dynamic score for every lead and then use that score to weight how much time your sales people spend on each potential customer (that sounds hard, but remember, you just need to use those three facts above to create that dynamic score). Collect the data. Depending on the length of your sales cycle go back and see the impact. Run some regressions on the impact of speaking to a lead with a future sale (or any other interim activities that could predict a future sale). You should be able to determine the value of a phone call as a function of the predicted value of the lead. Now you can use that (along with the cost of your sales people) to determine if you are over- or under-invested in sales people as well as where the sales people should be spending their time.
“But wait Ed: won’t the customer browsing history help do all that even better?”
It might. But the fact is, right now, you don’t have that data. Take a look at what you do have that you are not using. If it turns out that you have a standardized sales process that utilizes the methods of your best sales people across your entire organization, and you are using the data you already have that is readily available to add quantitative rigor to that process, then come back and talk to me about going out and looking for more esoteric data.
Which brings me back to #1: Collecting all that browsing history is hard.
Actually collecting it is not that hard – but turning it into anything that is usable is hard. Let’s say for example you have a log-in process on your website (this company didn’t). In that case, you can tie the browsing information of someone who is logged-in with that person’s information in your CRM system (wait: Don’t have a CRM system that can do that? Maybe it’s harder that you think already). But what do you do about the computers visiting your site that are not logged in? Well there are solutions for that too. You can “cookie” the computer (drop a small piece of code on their browser that allows you to identify the computer if it comes back) and then tie it back to the last time that computer was logged in. Chances are this is the same person revisiting, but not bothering to log in this time. What if more than one account was logged in on this computer? Hm. Maybe use the last person to log-in. Or maybe use the person who was logged in most frequently. Maybe hold that data and wait for the next time the computer is logged in and assign it to that account? What if in the same session someone logs out and then browses and then logs back in with a different account. Was the first account really the second account that didn’t realize they were logged in as someone else? What about computers that continually switch between two different accounts? Getting complicated enough yet? And have you even talked to your IT team about how they are going to build the infrastructure to tie all these computer and account structures together? This is why people insist that marketing is hard – they are constantly running down these rabbit holes.
But wait. At least email is easy, right? You send someone an email, you know who that person is. So if a link from that email is clicked on, obviously that lead has re-engaged. Well, unless that lead forwarded your email to someone else and they clicked on it. Could that happen? (The answer to that question is, “Yes. All the time.” At APFM we get a significant number of new “leads” from our email program, even though we only send emails to people who are already leads.).
So collecting this data right is not easy. It’s not impossible by any stretch: Expedia had an entire team committed to doing it. But collecting it and putting it in usable form is hard. It is a significant investment and easy to get wrong.
Then what do you do once you have it? How much impact will it have?
This varies a lot. At the simplest level I would bet a dollar that leads that were lying dormant – they had no contact with sales – that started interacting with your website or opening/clicking on emails that you were otherwise going to ignore are worth something. It would likely be worth the time of your sales people to re-engage. Some of those leads would be false positives, but I’ll bet the program would be ROI positive based just off the incremental cost of making those additional phone calls.
But I also bet that after including the cost of building the infrastructure to do it (all that computer/account/CRM matching) and the cost of finding the insights (turns out people who can find great insights in data are not cheap) and the cost of the rollout of the program to your sales people it will stop being ROI positive at some point. Even if it doesn’t, the ROI will still be a LOT lower than getting those basics right.
I am basically saying that these Big Data solutions are likely valuable – but only marginally. And that there are a LOT of non-marginal value that is likely lying right in front of you. I challenge you to work your way through this book and make sure you have done all the “Easy” stuff before you dive headlong into the sexy new things like Big Data. Even a company like Amazon, which from the outside sure looks like they have the basics in order, has gaps. I met the head of their Paid Search technology and after asking a few questions we both came away realizing they had a significant gap. I’ll talk about that specific gap more when I get to the Paid Search Channel.
Before I leave the world of Big Data I want to give you a few other examples of places where “The Basics” get you 90% of the way to the final solution and intense analytics add value – but only marginally. I hope these example drive home the point that you are much better off getting the basics launched than you are waiting for the final perfect solution. Execution trumps the perfect answer almost every time.
Sort Order
It turns out being at the top of a list matters. A lot. Online, the most watched sporting event in the 2012 Olympics wasn’t track or beach volleyball or diving or soccer or any of the sports you would think of. It was Archery. Archery is first in the alphabet and someone at the station decided to list the sports alphabetically so archery became the big winner. People choose the stuff that is at the top of the list.
At Expedia we had a team dedicated to sort order. Since the hotels at the top were selected most often and Expedia wanted to maximize its profits they wanted to make sure the hotels at the top both had high margin and a high likelihood to convert into sales. Their algorithms were very sophisticated and were constantly A/B tested against new ones. But here is the thing: The best algorithms were only a little better (~10%) than a random sort order at generating profit for Expedia. 10% is a lot, but random is a pretty terrible bar. If instead you ranked the hotels by their historical conversion rates times their margin – about the simplest reasonable model one could come up with – the fancy models only did a tiny tiny amount better. Their incremental improvement was so small in fact that management decided not to use it. It was better to use the simple method and then modify it based on the choices of the Market Managers (the people on the ground working with the hotels). It was more effective to use sort order as a negotiation tool than it was to use it directly to “maximize” profit. Again: Simple beats out complex. Hard loses to Easy.
Paid Search and Quality Score
When you advertise with Paid Search on Google you get a “Quality Score”. The score is supposed to represent how good your advertisement is. What you end up paying is a function of what you bid in an auction and the “quality” of your ad. But here’s the thing: Google has an advanced algorithm for Quality Score, but, when you are trying to reverse engineer that algorithm it turns out that you can match it almost exactly just by looking at Click Through Rate. Basically CTR = QS = Quality of the ad. Google has the resources to build a “perfect” algorithm that gets basically the same answer as a simple one. Do you have the profit margins and limitless resources of Google to get a perfect answer when the East one will do?
Collaborative Filtering
Collaborative Filtering was the “Big Data” of eight to ten years ago. The idea was you could take any individual customer and try to find other customers that were similar to them (based on demographics, but most importantly historical behavior). After you matched a customer to others you could send targeted offers to him or her based on what their matches ended up buying. The most common example of this is Amazon’s Recommended Purchases (I believe Amazon is best in the world for this right now and getting better all the time). This works for Amazon because they have a TON of data on a TON of customers. Most importantly they have a TON of purchase data on each individual customer (as opposed to just browsing history). This vast number of relevant data points lets them avoid the missteps that can happen when the dataset is sparser. Even with all of these advantages and incredible investment in the technology, Amazon still makes a ton of mistakes. Order a baby book for a friend and forget to mark it as a gift and you will be getting Richard Scary recommendations for months.
What’s the alternative?
I’ll give you two:
Step one: Start with Random.
Chances are your company, unlike Amazon, doesn’t sell everything. Chances are your products or services or content already has some similarities. Try making recommendations for other products randomly. I guarantee it will do better than not making recommendations at all. If you aren’t doing this, don’t even think of developing a collaborative filtering tool.
Step two: Recommend your best selling products (or best-selling services. Or most read content). Take one more step and recommend the best-selling that the customer hasn’t already purchased.
Step three: Take a single product (service/content) view. This is super-simple collaborative filtering. Look at every customer who bought that product (read that content). What was the second most common product purchased? Recommend that.
I’ll bet you find that you make a ton of impact implementing step one. Then you get a small amount of more impact by launching step two. Then you get hardly any impact at all from doing step three. There are huge diminishing returns from getting better and better at this stuff. If Amazon can get better and make an additional 0.1% that’s amazing for them, but you likely have bigger fish to fry.
Buying More Data
There are companies that make a living selling you data about your own customers. Their entire pitch is to help you target your customers better. If only you knew that some of your customers owned homes or had high income or subscribed to Entertainment Weekly, maybe you could do a better job targeting them with your segmentation programs. By now I hope you can guess what I’m going to say next…
There is nothing wrong with adding this data on top of your internal data, but only if you are already using your own data and using it really really well. This does not apply to many companies on the planet, so be very sure your company is killing it before you jump into buying more. Obviously the vendors selling you this extra data will never tell you that – their businesses would stop functioning if they only sold data to the companies that could really take advantage of it. The consultants that want you to employ them to implement the data won’t tell you that. The gurus who want to talk about the power of Big Data won’t tell you that. Effectively the companies that can’t use the data are subsidizing the price for companies that can.
The three sentence version
Hardcore analytics (and Big Data) can add value, but only marginally and only for companies that have already mastered using the data they already have. The ‘obvious’ information from your own data can get you 90%+of the total impact you will get from insights. The hard part is executing the basic insights across the organization – so start there before you go looking for more intellectual stimulation.
Originally posted at http://marketingiseasy.com/big-data//
Edward Nevraumont can be reached through http://www.linkedin.com/in/edwardn.
We have all heard the cliché of the 80/20 principle: 80% of impact comes from 20% of effort (or 20% of your customers provide 80% of your revenue. In actual practice everywhere I’ve looked it is usually closer to the “70/30 principle”, but the concept still applies). Regardless of the actual numbers, the principle is rarely applied to marketing activities.
The latest trend is “Big Data”. The original concept of Big Data was the concept of using all of the information a company collect that was being thrown away due to costs and capacity constraints. With the rapidly declining cost of storage and retrieval, combined with machine learning, we should be able to find insights in all that ‘garbage data’ and use it to make better decisions in the core business. At least that’s the theory. As far as the basic theory goes it’s all true, but it’s not the full story.
Like a lot of trends, the drive to mastering Big Data has gone a little overboard. Google searches for the term “Big Data” has grown from practically nothing in 2010 to almost 200,000 searches a month by the end of 2013 [see chart from Google Trends below], and people selling products and services have caught on (The suggested Paid Search Bid for the term “Big Data” is now over $9 per click. To put into perspective the term “Las Vegas Hotels” only has a suggested bid of $3.71, and that term is far more action oriented than the generic “Big Data”). Products or services that were once described as analytic or database or statistical four years ago has suddenly morphed into “Big Data Solutions” (I’ve heard Nate Silver’s work been described as “Big Data”. Mr. Silver does straightforward statistical analysis and communicates it in a compelling way. But he is not, at least in his popular blog, doing “Big Data”). Consulting firms pitch their ability to help companies “leverage” their “Big Data”. It has become so ingrained in company cultures that to say you don’t want to use Big Data is a bit like saying you are against data-driven decision making. It would be career suicide to say Big Data is a waste of company time and resources.
But that’s exactly what I am going to do.
I am not going to argue that Big Data when done properly cannot create value. What I will argue is that if you are not already dominating your field and mastered all of the basics, then any dive into Big Data is just chasing a trend and a waste of your team’s time.
I think the best way for me to drive home the argument is with a series of examples.
Why Sales Does Not Need Big Data
Recently the head of sales and marketing for Fortune 500 company asked me how he should best use the browsing history of his customers to determine the priority of sales follow-up calls. This is a classic example of Big Data – its data that was being collected (somewhere) and thrown away. And that data could definitely tell us something more than we know right now. Sounds like a no brainer, right? He thought so.
I told him not to bother.
There are three reasons why (As an alumni of McKinsey I have learned there are always exactly three reasons for just about everything):
- Using this data is much much harder than it first looks
- The impact you will get is much much lower than you think it will be; and
- You can achieve significantly more impact if you do a few other things that you aren’t doing now
Let’s start with #3.
Here is what I told him I would do if I was in his shoes:
First, understand what your current follow-up procedure is. Do you have a standardized follow-up protocol that has high compliance across your entire organization, or is every location doing it their own way? The answer was the latter. If you haven’t standardized the basic flow, then what are you going to do with the new information you get from the Big Data? Are you just going to share it with the field and hope they all use it the way you want them to? Are you going to take that data with a bunch of other stuff you have and try to change the way each location is operating.
I would imagine the hope is that you will find some insights and then find a way to implement them. But the issue is you haven’t proven that you can get a standardized program implemented now. What makes you think you can get a standardized method with Big Data implemented? If you can’t you have just wasted all the time you spent getting the data. You are left with an insight that doesn’t drive any impact.
Instead, Step One needs to be: Find out which parts of your sales organization are most effective. Really understand what they are doing. Then create a program to roll out that effective method across the entire organization.
This should be easy in theory, but it is hard in practice. Hard or easy though it is absolutely essential to get the program right before you start trying to do the hard theory on top of it.
OK. So now you’ve done that (or someone else did it before you came along). You have a well-functioning sales organization with standardized procedures that steals from your best 10% of sales people and apples it to your entire company. Now you are ready to apply Big Data, right?
Not yet.
The next step, before you go and get more data is to look at what you already have and see if you can find what the big drivers of performance are. They are there and they are almost always obvious. In this case the organization collected a wide variety of information from any given lead well before a sale happened. Someone in your organization should be able to do a series of simple logistical regressions to see which characteristics are most predictive of a sale.
Want to know what the magic bullets were for this company? Get your pen ready:
#1: How long has it been since the lead first came to the team.
It turns out that leads go stale over time. 90% of their sales came from leads that were less than 12 months old. 50% from leads less than 3 months old. This isn’t rocket science, but an easy first insight is: Stay in touch with, and put more effort into, your new leads.
#2: Is the lead’s budget for your product high enough to pay for the product you are selling?
If the lead says they can’t afford you, it turns out they (usually) can’t. Or to put another way, the lead who says he can afford you is more likely to buy your product.
#3: They answer “soon” to the question: “How soon do you plan on making a purchase?”
When people say they need to buy right away, not only do they often need to buy right away, but they are also more likely to buy ever.
You might have been able to guess all three of these (or one of your top sales people might) or you might not. But it doesn’t matter. You definitely don’t need big data to find these insights.
The next question is: Are you using those three insights now to manage your sales funnels?
In this case the answer was “No.”
So step two is: “Do that.”
Create a dynamic score for every lead and then use that score to weight how much time your sales people spend on each potential customer (that sounds hard, but remember, you just need to use those three facts above to create that dynamic score). Collect the data. Depending on the length of your sales cycle go back and see the impact. Run some regressions on the impact of speaking to a lead with a future sale (or any other interim activities that could predict a future sale). You should be able to determine the value of a phone call as a function of the predicted value of the lead. Now you can use that (along with the cost of your sales people) to determine if you are over- or under-invested in sales people as well as where the sales people should be spending their time.
“But wait Ed: won’t the customer browsing history help do all that even better?”
It might. But the fact is, right now, you don’t have that data. Take a look at what you do have that you are not using. If it turns out that you have a standardized sales process that utilizes the methods of your best sales people across your entire organization, and you are using the data you already have that is readily available to add quantitative rigor to that process, then come back and talk to me about going out and looking for more esoteric data.
Which brings me back to #1: Collecting all that browsing history is hard.
Actually collecting it is not that hard – but turning it into anything that is usable is hard. Let’s say for example you have a log-in process on your website (this company didn’t). In that case, you can tie the browsing information of someone who is logged-in with that person’s information in your CRM system (wait: Don’t have a CRM system that can do that? Maybe it’s harder that you think already). But what do you do about the computers visiting your site that are not logged in? Well there are solutions for that too. You can “cookie” the computer (drop a small piece of code on their browser that allows you to identify the computer if it comes back) and then tie it back to the last time that computer was logged in. Chances are this is the same person revisiting, but not bothering to log in this time. What if more than one account was logged in on this computer? Hm. Maybe use the last person to log-in. Or maybe use the person who was logged in most frequently. Maybe hold that data and wait for the next time the computer is logged in and assign it to that account? What if in the same session someone logs out and then browses and then logs back in with a different account. Was the first account really the second account that didn’t realize they were logged in as someone else? What about computers that continually switch between two different accounts? Getting complicated enough yet? And have you even talked to your IT team about how they are going to build the infrastructure to tie all these computer and account structures together? This is why people insist that marketing is hard – they are constantly running down these rabbit holes.
But wait. At least email is easy, right? You send someone an email, you know who that person is. So if a link from that email is clicked on, obviously that lead has re-engaged. Well, unless that lead forwarded your email to someone else and they clicked on it. Could that happen? (The answer to that question is, “Yes. All the time.” At APFM we get a significant number of new “leads” from our email program, even though we only send emails to people who are already leads.).
So collecting this data right is not easy. It’s not impossible by any stretch: Expedia had an entire team committed to doing it. But collecting it and putting it in usable form is hard. It is a significant investment and easy to get wrong.
Then what do you do once you have it? How much impact will it have?
This varies a lot. At the simplest level I would bet a dollar that leads that were lying dormant – they had no contact with sales – that started interacting with your website or opening/clicking on emails that you were otherwise going to ignore are worth something. It would likely be worth the time of your sales people to re-engage. Some of those leads would be false positives, but I’ll bet the program would be ROI positive based just off the incremental cost of making those additional phone calls.
But I also bet that after including the cost of building the infrastructure to do it (all that computer/account/CRM matching) and the cost of finding the insights (turns out people who can find great insights in data are not cheap) and the cost of the rollout of the program to your sales people it will stop being ROI positive at some point. Even if it doesn’t, the ROI will still be a LOT lower than getting those basics right.
I am basically saying that these Big Data solutions are likely valuable – but only marginally. And that there are a LOT of non-marginal value that is likely lying right in front of you. I challenge you to work your way through this book and make sure you have done all the “Easy” stuff before you dive headlong into the sexy new things like Big Data. Even a company like Amazon, which from the outside sure looks like they have the basics in order, has gaps. I met the head of their Paid Search technology and after asking a few questions we both came away realizing they had a significant gap. I’ll talk about that specific gap more when I get to the Paid Search Channel.
Before I leave the world of Big Data I want to give you a few other examples of places where “The Basics” get you 90% of the way to the final solution and intense analytics add value – but only marginally. I hope these example drive home the point that you are much better off getting the basics launched than you are waiting for the final perfect solution. Execution trumps the perfect answer almost every time.
Sort Order
It turns out being at the top of a list matters. A lot. Online, the most watched sporting event in the 2012 Olympics wasn’t track or beach volleyball or diving or soccer or any of the sports you would think of. It was Archery. Archery is first in the alphabet and someone at the station decided to list the sports alphabetically so archery became the big winner. People choose the stuff that is at the top of the list.
At Expedia we had a team dedicated to sort order. Since the hotels at the top were selected most often and Expedia wanted to maximize its profits they wanted to make sure the hotels at the top both had high margin and a high likelihood to convert into sales. Their algorithms were very sophisticated and were constantly A/B tested against new ones. But here is the thing: The best algorithms were only a little better (~10%) than a random sort order at generating profit for Expedia. 10% is a lot, but random is a pretty terrible bar. If instead you ranked the hotels by their historical conversion rates times their margin – about the simplest reasonable model one could come up with – the fancy models only did a tiny tiny amount better. Their incremental improvement was so small in fact that management decided not to use it. It was better to use the simple method and then modify it based on the choices of the Market Managers (the people on the ground working with the hotels). It was more effective to use sort order as a negotiation tool than it was to use it directly to “maximize” profit. Again: Simple beats out complex. Hard loses to Easy.
Paid Search and Quality Score
When you advertise with Paid Search on Google you get a “Quality Score”. The score is supposed to represent how good your advertisement is. What you end up paying is a function of what you bid in an auction and the “quality” of your ad. But here’s the thing: Google has an advanced algorithm for Quality Score, but, when you are trying to reverse engineer that algorithm it turns out that you can match it almost exactly just by looking at Click Through Rate. Basically CTR = QS = Quality of the ad. Google has the resources to build a “perfect” algorithm that gets basically the same answer as a simple one. Do you have the profit margins and limitless resources of Google to get a perfect answer when the East one will do?
Collaborative Filtering
Collaborative Filtering was the “Big Data” of eight to ten years ago. The idea was you could take any individual customer and try to find other customers that were similar to them (based on demographics, but most importantly historical behavior). After you matched a customer to others you could send targeted offers to him or her based on what their matches ended up buying. The most common example of this is Amazon’s Recommended Purchases (I believe Amazon is best in the world for this right now and getting better all the time). This works for Amazon because they have a TON of data on a TON of customers. Most importantly they have a TON of purchase data on each individual customer (as opposed to just browsing history). This vast number of relevant data points lets them avoid the missteps that can happen when the dataset is sparser. Even with all of these advantages and incredible investment in the technology, Amazon still makes a ton of mistakes. Order a baby book for a friend and forget to mark it as a gift and you will be getting Richard Scary recommendations for months.
What’s the alternative?
I’ll give you two:
Step one: Start with Random.
Chances are your company, unlike Amazon, doesn’t sell everything. Chances are your products or services or content already has some similarities. Try making recommendations for other products randomly. I guarantee it will do better than not making recommendations at all. If you aren’t doing this, don’t even think of developing a collaborative filtering tool.
Step two: Recommend your best selling products (or best-selling services. Or most read content). Take one more step and recommend the best-selling that the customer hasn’t already purchased.
Step three: Take a single product (service/content) view. This is super-simple collaborative filtering. Look at every customer who bought that product (read that content). What was the second most common product purchased? Recommend that.
I’ll bet you find that you make a ton of impact implementing step one. Then you get a small amount of more impact by launching step two. Then you get hardly any impact at all from doing step three. There are huge diminishing returns from getting better and better at this stuff. If Amazon can get better and make an additional 0.1% that’s amazing for them, but you likely have bigger fish to fry.
Buying More Data
There are companies that make a living selling you data about your own customers. Their entire pitch is to help you target your customers better. If only you knew that some of your customers owned homes or had high income or subscribed to Entertainment Weekly, maybe you could do a better job targeting them with your segmentation programs. By now I hope you can guess what I’m going to say next…
There is nothing wrong with adding this data on top of your internal data, but only if you are already using your own data and using it really really well. This does not apply to many companies on the planet, so be very sure your company is killing it before you jump into buying more. Obviously the vendors selling you this extra data will never tell you that – their businesses would stop functioning if they only sold data to the companies that could really take advantage of it. The consultants that want you to employ them to implement the data won’t tell you that. The gurus who want to talk about the power of Big Data won’t tell you that. Effectively the companies that can’t use the data are subsidizing the price for companies that can.
The three sentence version
Hardcore analytics (and Big Data) can add value, but only marginally and only for companies that have already mastered using the data they already have. The ‘obvious’ information from your own data can get you 90%+of the total impact you will get from insights. The hard part is executing the basic insights across the organization – so start there before you go looking for more intellectual stimulation.
Originally posted at http://marketingiseasy.com/big-data//
Edward Nevraumont can be reached through http://www.linkedin.com/in/edwardn.