Sibyl: Google’s system for Large Scale Machine Learning
A review of 2014 keynote talk about Sibyl, Google system for large scale machine learning. Parallel Boosting algorithm and several design principles are introduced.
Our lives are experiencing more and more benefits of machine learning. Take Google as an example, Google’s search autocomplete always saves my time. YouTube recommends a potential video list we may watch later, and Gmail spam detection system helps us filter spam emails although it makes mistake sometimes.
I have always been curious how Google deals with so much data.
Sibyl is one of the largest machine learning platforms at Google and is widely used in ranking and scoring of Google products like YouTube, Android app, Gmail, and Google+. Last month, Tushar Chandra, a Principal Engineer at Google Research, talked about how Sibyl is being used at IEEE/IFIP International Conference on Dependable Systems and Networks (DSN 2014).
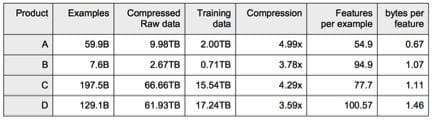 The table above may give you an idea of the scale of problems Sibyl is dealing with. The number of “Features per example” shown in the table is actually “Active Features per example”. The number of original features per example will be around 1B. As long as each example is sparse, Sibyl can handle over 100B examples in 100B dimensions. However, it will take years to process entire data if using simple iterative algorithms like stochastic gradient descent, or even Vowpal Wabbit.
The table above may give you an idea of the scale of problems Sibyl is dealing with. The number of “Features per example” shown in the table is actually “Active Features per example”. The number of original features per example will be around 1B. As long as each example is sparse, Sibyl can handle over 100B examples in 100B dimensions. However, it will take years to process entire data if using simple iterative algorithms like stochastic gradient descent, or even Vowpal Wabbit.
On the other hand, accuracy is a big deal. Machine learning typically generates 10+% improvements, which is becoming an industry “best practice”. For Google, 1% improvement of accuracy means millions of dollars. So people are putting a lot of efforts to improve machine learning solutions. In fact, Sibyl is using Parallel Boosting Algorithm running on multiple machines.
 The scheme showed above is the core of Sibyl system where each step can be done in parallel. I am going to skip the details. People interested in the algorithm may read the paper by Collins, Schapire and Singer.
The scheme showed above is the core of Sibyl system where each step can be done in parallel. I am going to skip the details. People interested in the algorithm may read the paper by Collins, Schapire and Singer.
As Tushar said, Sibyl is the only large scale machine learning system without distributed system built inside. MapReduce and Google File System provide what they need for a distributed system. Parallel Boosting Algorithm made it possible since it is very well suited for MapReduce and GFS.
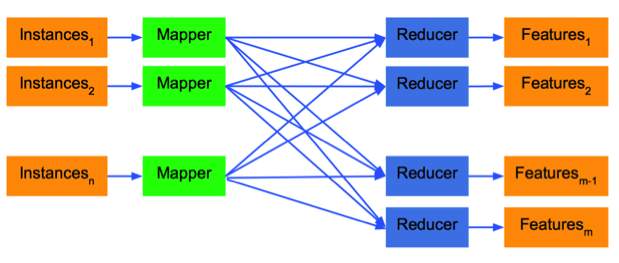
They feed the instances in the Mapper and each feature is assigned to one of the Reducers. Between Mapper and Reducer, Parallel Boosting Algorithm is used.
It would normally take 10-50 iterations to converge.
Tushar also introduced a couple of design principles, like using GFS for communication, column-oriented data store, using a dictionary of features, storing model and stats in RAM, and optimizing for multi-core, which I would not enumerate in my post.
Sibyl would be faster and more efficient designed with these principles. For example, as the first table shows, the system is designed to improve efficiency by compressing training data as much as 80 percent by using column-oriented data storage. Bytes per feature could be as small as 0.67 with features integerization.
You may find more details in the video
DSN 2014 Keynote: “Sibyl: A System for Large Scale Machine Learning at Google”.
Ran Bi is a master student in Data Science program at New York University. She has done several projects in machine learning, deep learning and also big data analytics during her study at NYU.
Related: