Data is Ugly – Tales of Data Cleaning
Whether you want to do business analytics or build the deep learning models, getting correct data and cleansing it appropriately remains the major task. Find out experts opinions on how you can make efficient data cleansing and collection efforts.
By Sally Hadidi (import.io).
For data scientists this is an all too well know fact. Data is rarely as simple or as beautiful as we would like it to be. Big Data is supposed to help us to make informed decisions and change the way we do business, right? That’s the promise of the data-driven enterprise movement: making business decisions based on the data.

But before we can find any of these interesting nuggets of information or predict trends, we have to do a lot of cleaning. The problem with Big Data is that it is inherently a big, ugly mess that data scientists have to spend hours or days unraveling and putting in order before they can do anything meaningful.
So how can we make data less ugly for more beautiful insights?
Ahead of Extract Conf, 30 October in San Francisco, here is how data experts from all different industries answered this question at last year data festival.
Smarter data collection
The best place to start is at the source. If you are collecting the data internally, you can work with your engineers to devise better ways of collecting and organizing data into a system that will require less post-processing. As Ryan Orban, Chief Data Wrangler at Zipfian stated, it’s essential that your data science and engineering teams know how to work together. Each team should have at least a base understanding of what the other does so that they understand, and can help mitigate, the pain points of the other.
If you’re collecting data from outside your organization, data collection tools like import.io, diffbot and ScraperWiki allow you to specify exactly what data you collect (so you don’t end up having to regex out the entire website just to find the price) and label it in the correct form (ie text, number, currency, etc) when you are building the API. Alternatively, if you’ve got a budget, you can buy process ready data sets that are custom built to your specifications.
Creative data cleaning
Depending on your industry and your data, you may run into unique challenges with cleaning and normalising your data beyond what a standard python script can do. Eddie Bell, Head Data Science at Lyst, gave a talk at Extract London earlier this year on their issues with color. Color is a highly subjective spectrum that is incredibly difficult for machines to identify, so the team at Lyst developed a new system (python color map) to identify colors programmatically.

Of course if you can’t create your own internal program to solve your unique data cleaning issue, you may have to get even more creative. In his talk on How to Take the Best Selfie, import.io CDO Andrew Fogg showcased the use of crowdsourced data identification by using Amazon’s Mechanical Turk system – in which you empoly an army of people to sort and categorize your data.
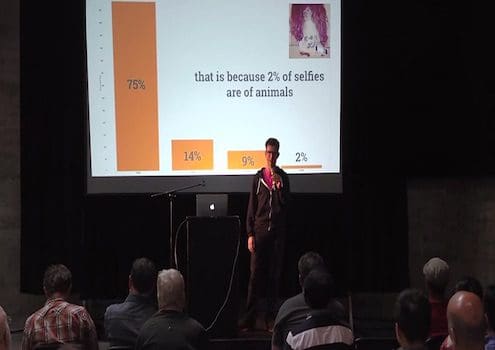
Easy to use systems
If you’re going to have people working with your data and creating reports with it, you need to make sure that their methods are reproducible. Both so that you can replicate their findings with new data and so that they can be verified for accuracy.
The only way to do this is to invest in internal tooling systems that make it easy for data scientists (or anyone else in the organization) to work with data in a systematic way. Daniel Frank from Stripe talked at Extract San Francisco last year about how they were able to make their data accessible to everyone in the company by creating an easy to use publishing environment for anyone trying to run data reports. Their efforts led to a marked increase in data reports that were highly accurate and more in-depth.
Common sense
No matter how well you do it, analyzing ugly data can sometimes lead you to get answers that aren’t correct. As the great statistician David Spiegelhalter said,
in data science it’s not enough to be good at statistics, you need to use your brain.
If the data is telling you something that doesn’t make sense, investigate. Every data scientist should strive to be a subject matter expert in their business field as well as in statistics and modeling.
Extract is a day-long conference that gathers the coolest minds in data to share hand-crafted, data-drive stories. You can purchase tickets for their San Francisco conference on October 30th at DogPatch Studios.
KDnuggets readers can claim a special 10% discount until the end of August using the code: Extract-Nuggets
Related: