Automatic Statistician and the Profoundly Desired Automation for Data Science
The Automatic Statistician project by Univ. of Cambridge and MIT is pushing ahead the frontiers of automation for the selection and evaluation of machine learning models. In general, what does automation mean to Data Science?
 Can Data Science be automated? This billion dollar question is greatly interesting and greatly unsurprising at the same moment. The immense scope of advancement possible through automation of data science activities such as data model selection, optimization, inference, etc. has led to great interest in this idea. Meanwhile, the fact that we live in Big Data era implies that there is no way the manual approach to Data Science can keep pace with the rapid increase in volume, velocity and variety of data. So, automation is inevitable for sustainable progress. However, how soon we will reach there is still debatable.
Can Data Science be automated? This billion dollar question is greatly interesting and greatly unsurprising at the same moment. The immense scope of advancement possible through automation of data science activities such as data model selection, optimization, inference, etc. has led to great interest in this idea. Meanwhile, the fact that we live in Big Data era implies that there is no way the manual approach to Data Science can keep pace with the rapid increase in volume, velocity and variety of data. So, automation is inevitable for sustainable progress. However, how soon we will reach there is still debatable.
There is no denying that a good amount of work in Data Science is mundane. Trying a variety of machine learning models and selecting the best combination of model and predictor variables is extremely time consuming and not remotely as interesting as it might sound in theory. If the underlying data was perfect, we could have been able to decide the best model from theory itself. But, in real life, data comes along with a lot of imperfections - errors, missing values, different scales/units, etc. With such varying data characteristics, one needs a lot of experimentation to determine which Machine Learning (ML) model would represent it the best. Today, we have a considerable number of ML models, each having a lot of inherent minor variations which are better suited to particular situations. Selecting a model goes hand-in-hand with selecting predictor variables, which is no less daunting considering the highly multi-dimensional nature of the data we are dealing with. So, choosing the right model is the same as looking for a needle in haystack.
It's important to understand that the problem with manual approach is not just how many man-hours are required but also the mandatory skills required for the task. So, essentially there are two solutions (assuming that automation is yet not feasible): recruit more people with the mandatory skills (i.e. data scientists) or through use of innovative technology eradicate the need for those specialized skills, thus, enabling almost everyone in the organization to understand and perform those Data Science tasks. The latter is the focus of the Automatic Statistician project led by Prof. Zoubin Ghahramani at the University of Cambridge.
The primary challenge here is not software development, but the advanced machine learning required in the areas of automated inference, model construction & comparison, and data visualization & interpretation. For any input dataset, the Automatic Statistician refers to an open-ended language of models to search (greedy approach) and evaluate the models that are potential candidates for selection. The selected model and other data inferences are then explained in a 10-15 page report that can be understood by non-experts.
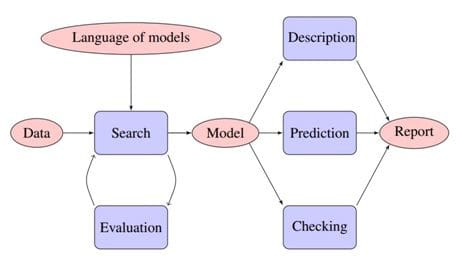
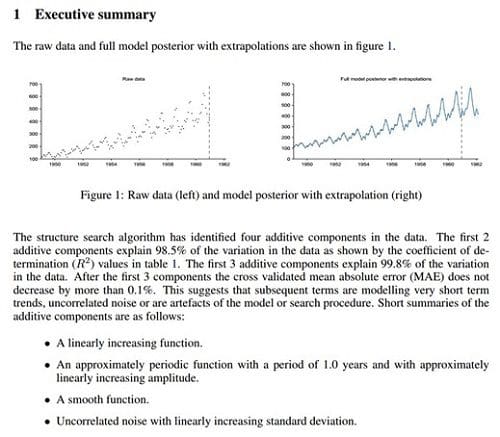
One of the remarkable features of Automatic Statistician is the simplicity of its report which is targeted at non-experts. The conversion of insights from statistical representation to human-interpretable form plays a crucial role in widespread understanding and application of Analytics. Here is an excerpt from the report generated for airline passenger volume data set demonstrating non-stationary periodicity:
Yet another notable feature is the model criticism included in its report. This criticism answers key questions (for example, does the data match the assumptions of the model?) and includes the results of posterior predictive checks, dependence tests and residual tests.
The project is currently in early phase. Almost a year ago, Automatic Statistician project won $750,000 Google Focused Research Award.
The first problem is that current ML methods still require considerable human expertise in devising appropriate features and models. The second problem is that the output of current methods, while accurate, is often hard to understand, which makes it hard to trust. The “automatic statistician” project from Cambridge aims to address both problems, by using Bayesian model selection strategies to automatically choose good models/ features, and to interpret the resulting fit in easy-to-understand ways, in terms of human readable, automatically generated reports.
- Kevin Murphy, Senior Research Scientist at Google
(Source: UC ML Group News)
For successful transition to industry, the project will have to address various challenges such as reducing the computational complexity of searching through a large space of models and increasing the expressivity of language to describe sophisticated statistical inferences.
Attempts to automate Data Science are not limited to academia. Various startups such as Skytree and BigML have made significant strides in this direction. There are also a few startups such as Narrative Science offering services to turn numerical analytics results into readable reports.
Model selection and evaluation is not the only arena in Data Science where automation is keenly desired.
 In fact, for underlying data to reach this stage, it needs to first go through data cleaning (also known as “data wrangling”, “data munging” or “data janitor work”). KDnuggets poll suggested that data cleaning and preparation take up more than 60% of time on data mining projects. The goal of automatic data preparation is being chased by several startups including Paxata and Trifacta.
In fact, for underlying data to reach this stage, it needs to first go through data cleaning (also known as “data wrangling”, “data munging” or “data janitor work”). KDnuggets poll suggested that data cleaning and preparation take up more than 60% of time on data mining projects. The goal of automatic data preparation is being chased by several startups including Paxata and Trifacta.
Besides saving our data scientists from mundane work and enabling non-experts to perform data science tasks, automation also offers the key benefit of performing these crucial tasks with speed, scale and accuracy. This is a core requirement for sustainable analytics.
Will the increasing trend of automation adversely impact the data scientists and their job prospects? It depends. If you are a data scientist who treats his/her work as a typical 8am – 5pm job with well-defined tasks that need to be performed repetitively, you must be scared of automation. On the other hand, if you are a data scientist who loves his/her job, but is bored of non-challenging, repetitive tasks, you would certainly embrace automation.
Bottom-line: Love it or hate it, automation is here to stay and grow in Data Science arena.
Related: