Fast Big Data: Apache Flink vs Apache Spark for Streaming Data
Real-time stream processing has been gaining momentum in recent past, and major tools which are enabling it are Apache Spark and Apache Flink. Learn with the help of a case study about Data processing, Data Flow, Data management using these tools.
Memory Management
Flink can automatically adapt to varied datasets but Spark needs to optimize and adjust its jobs manually to individual datasets. Also Spark does manual partitioning and caching. So, expect some delay in processing.
Data Flow
Flink is able to provide intermediate results on its data processing whenever required. While Spark follows a procedural programming system, Flink follows a distributed data flow approach. So, whenever intermediate results are required, broadcast variables are used to distribute the pre-calculated results through to all the worker nodes.
Data Visualization
Flink provides a web interface to submit and execute all jobs. Both Spark and Flink are integrated with Apache Zeppelin and provide data ingestion, data analytics, discovery, collaboration and visualization. Apache Zeppelin also provides a multi-language backend that allows you to submit and execute Flink programs.
Processing Time
The paragraphs below provide a comparison between the time taken by Flink and Spark in different jobs.
To make a fair comparison, both Flink and Spark were given the same resources in the form of machine specifications and node configurations.

As shown in the image above, the image highlighted in red indicates the machine specifications for a Flink processor while the one beside it shows that of a Spark processor.
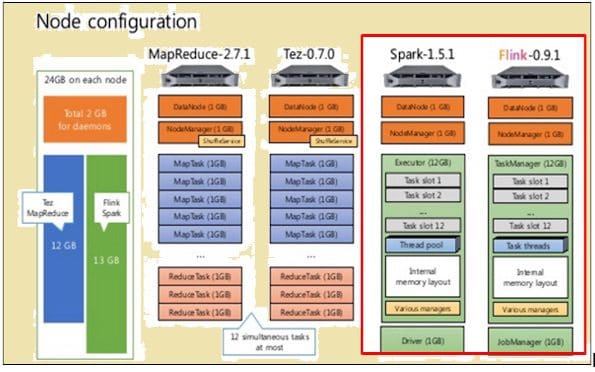
As shown in the image above, the area highlighted in red indicates the node configuration for a Flink processor and a Spark processor.
Flink processed faster because of its pipelined execution. To process data, Spark took 2171 seconds while Flink took 1490 seconds.
When TeraSort with various data sizes were performed, following were the results:
- For 10 GB data, Flink took 157 seconds compared to Spark’s 387 seconds.
- For 160 GB data, Flink took 3127 seconds compared to Spark’s 4927 seconds.
Batch-based or Streaming Data — which process is better?
Both processes have advantages and are suited for different situations. Though many are claiming that batch-based tools are going out of favor, it is not going to happen anytime soon. To understand their relative advantages, see the following comparison:
| Streaming | Batching |
| Data or inputs arrive in the form of records in a specific sequence. | Data or inputs are divided into batches based on the number of records or time. |
| Output is required as soon as is possible but not sooner than the time that is required to verify the sequence. | Inputs are given based on requirements but a certain number of batches are retained. |
| Output does not need to be modified after it is written. | A new state and the details of all the rows of the output are recorded. |
| Can also do batch processing of data | Is unable to do batch processing of data |
There are individual situations in which both Flink and Batch processing are useful. Take the use case of computing rolling monthly sales at daily intervals. In this activity, what is needed is to compute the daily sales total and then make a cumulative sum. In a use case like this, streaming processing of data may not be required. Batch processing of data can take care of the individual batches of sales figures based on dates and then add them. In this case, even if there is some data latency, which can always be made up later when that latent data is added to later batches.
There are similarly use cases which require streaming processing. Take the use case of calculating the rolling monthly time each visitor spends on a website. In case of a website, the number of visits may be updated, hourly, minute-wise or even daily. But the problem in this case is defining the session. It may be difficult to define the starting and ending of a session. Also, it is difficult to calculate or identify the periods of inactivity. So, in this case, there can be no reasonable boundaries for defining sessions or even periods of inactivity. In situations like these, streaming data processing on a real time basis is required.
Summary
Though Spark has a lot of advantages when it comes to batch data processing and it still has a lot of use cases it caters to, it appears that Flink is fast gaining commercial traction. The fact that Flink can also do batch processing seems to be a huge thing in its favor. Of course, this need to be accounted for that the batch processing capabilities of Flink may not be in the same league as that of Spark. So, Spark still has some time.
Bio: Kaushik Pal (www.techalpine.com) has 16 years of experience as a technical architect and software consultant in enterprise application and product development. He has interest in new technology and innovation area along with technical writing. His main focuses are on web architecture, web technologies, java/j2ee, Open source, big data and semantic technologies.
Related