5 Reasons Machine Learning Applications Need a Better Lambda Architecture
The Lambda Architecture enables a continuous processing of real-time data. It is a painful process that gets the job done, but at a great cost. Here is a simplified solution called as Lambda-R (ƛ-R) for the Relational Lambda.
By Monte Zweben, CEO Splice Machine.
Lambda architectures are ubiquitous in machine learning and data science applications. The Lambda Architecture enables a continuous processing of real-time data without the traditional ETL lag that plagues traditional operational (OLTP) and analytical (OLAP) implementations. In traditional architectures, OLTP databases are normalized for performance and then extensive ETL pipelines de-normalize this data, typically into star schemas on OLAP engines. This process usually takes at least a day. The Lambda Architecture circumvents this lag. In its purist form, the Lambda Architecture sends data down two paths: a batch processing layer and a speed layer. The batch layer aggregates the raw data and trains models. The results of the batch layer are then transferred to a serving layer for the application to surface. The speed layer allows applications to access the most current data that “missed” the last batch processing window.
So how do companies implement this architecture? For the batch layer, they typically use a batch analytics processing engine on Hadoop, like MapReduce, Hive or Spark. For the serving layer, they use a NoSQL/Key-Value engine that performs well on batch imports and reads like ElephantDB and Voldemort. For the speed layer, they need a data store that supports fast reads and writes like Cassandra or HBase. At the front of this architecture, there typically is a queuing system like Kafka and a streaming system like Storm, Spark or even Flink to break continuous data into chunks for processing.
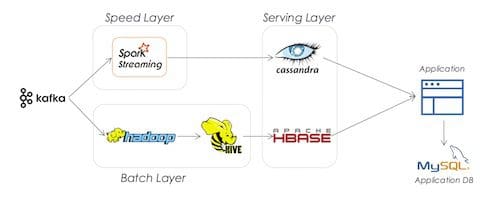
Enterprises keep this architecture working with what I like to call enterprise duct tape. It is a painful process that gets the job done, but at a great cost. Here are the five reasons we need a better Lambda architecture:
- Simplify Operational Complexity – It is very expensive to keep these systems synchronized based on versions and tuned for performance. It requires expertise in too many technologies
- Eliminate Need For Specialized Coding Skills – Developers have to be able to write pretty low-level code to handle basic operations like joins, aggregations, sorts, and groupings, let alone applying analytics. They have to write batch programs to cleanse and filter individual records
- Provide Access to Standard Tools – 99% of data scientists know SQL and have used BI visualization tools. Why would we throw away these powerful tools, now that they don’t have the same performance and flexibility issues that the first generation of databases had?
- Minimize Storage – Lambda typically requires at least duplicating the data in multiple engines
- Support Integrated Applications – The modern application does not have application logic separated from analytical logic. These workloads need to co-mingle. You want to be able to use the operational raw data for business applications in the moment, use it to perform feature engineering and train models, and be able to visualize it — all concurrently. This requires the ACID properties of traditional databases, the ingestion capabilities of NoSQL and the scale-out capabilities of the Hadoop/Spark engines
So what is a better solution? We call it Lambda-R (ƛ-R) for the Relational Lambda. With the new scale-out RDBMS systems, you can now get all the benefits of Lambda with a much simpler architecture.

Here’s how a machine learning application can use ƛ-R :
- Batch file ingestion – Imports of raw data files are directly inserted into sharded tables in parallel with indexes that are atomically updated with the data for fast access
- Real-time stream ingestion – Stored procedures continuously ingest streams with standard SQL and auto-shards
- Data cleansing – Use standard SQL, with constraints and triggers, to clean up small subsets of data as well as entire data sets efficiently, without big batch runs or file explosions
- Feature engineering and extensive ETL – Execute complex aggregations, joins, sorts, and groupings with efficient SQL that is automatically parallelized and optimized without writing code at the application level
- Model training – Stored procedures execute analytics directly on the data, for example, using built-in functions like ResultSetToRDD that take SQL results and treat them as Spark RDDs or execute R and Python libraries directly on database result sets.
- Application logic – ACID semantics enable the architecture to power concurrent CRUD applications without additional moving parts
- Model execution – Stored procedures and user-defined functions wrap models
- Reporting and data visualization – Use Tableau, Domo, MicroStrategy and other ODBC/JDBC tools turnkey
One scale out RDBMS that can do this is Splice Machine. Splice Machine is a dual-engine RDBMS that is built on Hadoop and Spark.
The Splice Machine RDBMS provides:
- ANSI SQL – Splice Machine provides ANSI SQL-99 coverage, including full DDL and DML
- ACID Transactions – Splice Machine provides fully ACID transactions with Snapshot Isolation semantics, which scale both to very small operational queries and large analytics
- In-Place Updates – Updates in Splice Machine scale from a single row to millions of rows with a single transaction
- Secondary Indexing – Splice Machine supports true secondary indices on data, in both unique and non-unique forms
- Referential Integrity – Referential integrity, such as Primary and Foreign key constraints, can be enforced without requiring any behavior from the underlying application
- Joins – Splice Machine supports inner, outer, cross and natural joins using join algorithms such as broadcast, merge, merge sort, batch nested loop, and nested loop joins
- Resource Isolation The cost-based optimizer chooses a dataflow engine based on the estimation of the query plan – OLTP runs on HBase and OLAP runs on Spark
In summary, by centralizing on a ƛ-R architecture, teams can build ML applications very quickly, maintain them with standard operational personnel, and be able to tightly integrate ML into the application without extensive use of “Enterprise Duct Tape”.
Related: