10 Data Acquisition Strategies for Startups
An interesting discussion of the myriad methods in which startups may choose to acquire data, often the most overlooked and important aspect of a startup's success (or failure).
By Moritz Mueller-Freitag, Eleven Strategy.
The “unreasonable effectiveness” of data for machine-learning applications has been widely debated over the years (see here, here and here). It has also been suggested that many major breakthroughs in the field of Artificial Intelligence have not been constrained by algorithmic advances but by the availability of high-quality datasets (see here). The common thread running through these discussions is that data is a vital component in doing state-of-the-art machine learning.
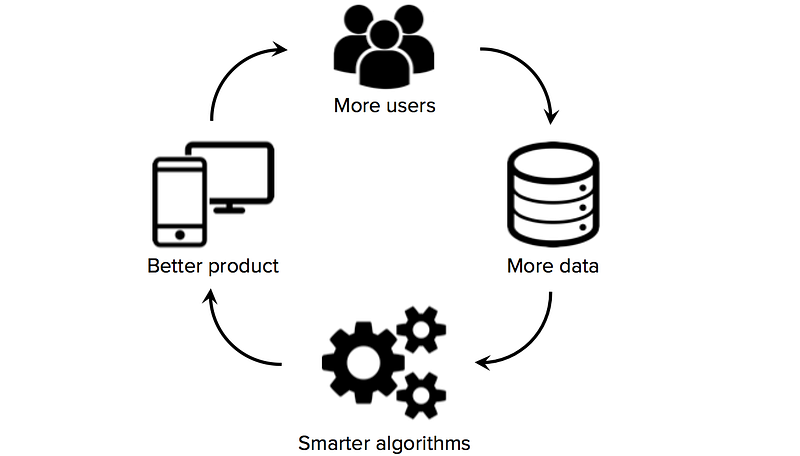
Access to high-quality training data is critical for startups that use machine learning as the core technology of their business. While many algorithms and software tools are open sourced and shared across the research community, good datasets are usually proprietary and hard to build. Owning a large, domain-specific dataset can therefore become a significant source of competitive advantage, especially if startups can jumpstart data network effects (a situation where more users → more data → smarter algorithms → better product → more users).
Consequently, one of the key strategic decisions that machine learning startups have to make is how to build high-quality datasets to train their learning algorithms. Unfortunately, startups often have limited or no labeled data in the beginning, a situation that precludes founders from making significant progress on building a data-driven product. It is therefore worth exploring data acquisition strategies from the outset, before hiring the data science team or building up a costly core infrastructure.
Startups can overcome the cold start problem of data acquisition in numerous ways. The choice of data strategy/source usually goes hand-in-hand with the choice of business model, a startup’s focus (consumer or enterprise, horizontal or vertical, etc.) and the funding situation. The following list of strategies, while neither exhaustive nor mutually exclusive, gives a sense for the broad range of approaches available.
Strategy #1: Manual work
Building a good proprietary dataset from scratch almost always means putting a lot of up-front, human effort into data acquisition and performing manual tasks that don’t scale. Examples of startups that have used brute force in the beginning are plentiful. For instance, many chatbot startups employ human “AI trainers” who manually create or verify the predictions their virtual agents make (with varying degrees of success and a high employee turnover rate). Even the tech giants resort to this strategy: all responses by Facebook M are reviewed and edited by a team of contractors.

Using brute force to manually label data points can be a successful strategy as long as data network effects kick in at some point so that humans no longer scale at an equal pace with the customer base. As soon as the AI system is improving fast enough, unspecified outliers become less frequent and the number of humans who perform manual labeling can be decreased or held constant.
Interesting for: More or less every machine learning startup
Examples:
Strategy #2: Narrow the domain
Most startups will try to collect data directly from users. The challenge is to convince early adopters to use the product before the benefits of machine learning fully kick in (because data is needed in the first place to train and fine-tune the algorithms). One way around this catch-22 is to drastically narrow the problem domain (and expand the scope later if needed). As Chris Dixon says: “The amount of data you need is relative to the breadth of the problem you are trying to solve.”
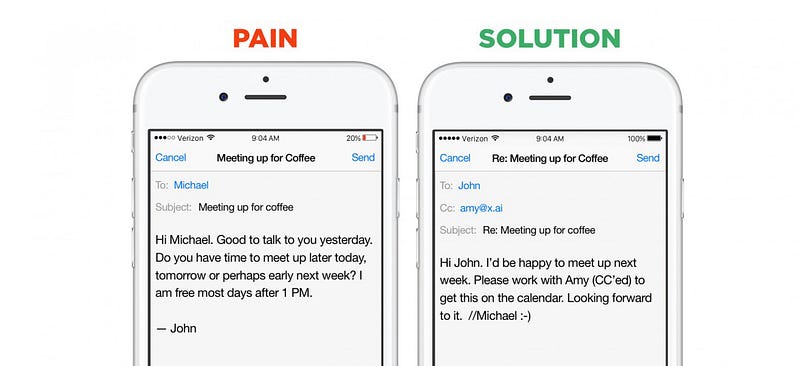
Good examples of the benefits of a narrow domain are again chatbots. Startups in this segment can choose between two go-to-market strategies: They can build horizontal assistants — bots that can help with a very large number of questions and immediate requests (examples are Viv, Magic,Awesome, Maluuba and Jam). Or they can create vertical assistants — bots that try to perform one specific, well-defined job extremely well (examples are x.ai, Clara, DigitalGenius, Kasisto, Meekan — and more recentlyGoButler/Angel.ai). While both approaches are valid, data collection is dramatically easier for startups that tackle closed-domain problems.
Interesting for: Vertically integrated businesses
Examples:
- Highly-specialized vertical chatbots (such as x.ai, Clara or GoButler)
- Deep Genomics (uses deep learning to classify/interpret genetic variants)
- Quantified Skin (uses customer selfies to analyze a person’s skin)
Strategy #3: Crowdsourcing / Outsourcing
Instead of using qualified employees (or interns) to manually collect or label data, startups can also crowdsource the process. Platforms like Amazon Mechanical Turk or CrowdFlower offer a way to clean up messy and incomplete data using an online workforce of millions of people. For example, VocalIQ (acquired by Apple in 2015) used Amazon’s Mechanical Turk to feed its digital assistant thousands of user queries. Workers can also be outsourced by employing other independent contractors (as done byClara or Facebook M). The necessary condition for using this approach is that the task can be clearly explained and is not too long/boring.

Another tactic is to incentivize the public to voluntarily contribute data. An example is Snips, a Paris-based AI startup that uses this approach to get its hands on a certain type of data (confirmation emails for restaurants, hotels and airlines). Like other startups, Snips uses a gamified system where users are ranked on a leaderboard.
Interesting for: Use cases where quality control can be easily enforced
Examples:
Strategy #4: User-in-the-loop
A crowdsourcing strategy that deserves its own category is user-in-the-loop.This approach involves designing products that provide the right incentives for users to give data back to the system. Two classic examples of companies that have used this approach for many of their products are Google(autocomplete in search, Google Translate, spam filters, etc.) and Facebook(users tagging friends in photos). Users are often unaware that they provide these companies with labeled data for free.
Many startups in the machine learning space have drawn inspiration from Google and Facebook by creating products with a fault-tolerant UX that explicitly encourage users to correct machine errors. Particularly notable arereCAPTCHA and Duolingo (both founded by Luis von Ahn). Other examples include Unbabel, Wit.ai and Mapillary.
Interesting for: Consumer-centric startups with constant user interaction
Examples:
Strategy #5: Side business
A strategy that seems to be particularly popular among computer vision startups is to offer a free, domain-specific mobile app that targets consumers. Clarifai, HyperVerge and Madbits (acquired by Twitter in 2014) have all pursued this strategy by offering photo apps that gather additional image data for their core business.
This strategy is not completely without risk (after all, it costs time and money to successfully develop and promote an app). Startups must also ensure that they create a strong enough use case that compels users to give up their data, even if the service lacks the benefits of data network effects in the beginning.
Interesting for: Enterprise startups/horizontal platforms
Examples:
- Clarifai (Forevery, photo discovery app)
- HyperVerge (Silver, photo organization app)
- Madbits (Momentsia, photo collage app)