Laying the Foundation for a Data Team
Admittedly, there is a lot more to building a successful data team, and we would be lying if we pretended we have it all figured out. But hopefully focusing on the elements in this post is a good start.
By Dimitri Masin, Head of Analytics & Data, Monzo.
After a hugely popular post by Oliver, our Head of Engineering, ‘Building a Modern Bank Backend’ (which you should definitely check out), I wanted to write about how we’re building our data team.
At Monzo, we want to build the best bank account in the world. Today, more than ever before, data is central to creating wonderful customer experiences and efficient internal operations. Wouldn’t it be magical if we could predict the issue somebody is facing even before they contact us? Or are there better ways to assess someone’s loan eligibility than just relying on out-of-date credit scores?
We want to build a data team which can support the whole company in making data-driven decisions and products, and which contributes to making us operationally 10x more efficient than banks of the past. By doing so, we want to keep the team as lean and highly-leveraged as possible. Here is our story on that journey so far.
Three core principles guide our data work. They were not all part of one big ‘master plan’ but rather evolved over time based on what we had already tried and experimented with.
- Autonomy We believe that people reach their full potential when you remove all the operational obstacles out of their way and let them run with their ideas. Every data team member gets full access to our sanitised (filtered for sensitive personal information) data and analytics infrastructure and is empowered to do anything from decision analyses, ETL and feature engineering to model deployment themselves.
- Cutting-edge managed analytics infrastructure We use fully managed infrastructure for analytics, so we don’t need to spend our time configuring or maintaining it. It also allows us to cleanly separate analytics from our critical production infrastructure. This way we can focus on what we do best, which is a key element that enables autonomy in the first place!
- Automation We automate as much as we can, make analysis easily updatable and enable everyone in the company to access data through self-serve platforms.
Admittedly, there is a lot more to building a successful data team, and we would be lying if we pretended we have it all figured out. But hopefully focusing on these three elements is a good start.
Autonomy
Companies regularly find themselves in a situation where data engineering and data science are two distinct roles. The former work on infrastructure, ETL (Extract Transform Load operations) and maybe feature extraction while the latter are building shiny models. And for some companies, it might work fine – after all, specialisation happens for a reason.
However, there is an inherent motivational problem in structuring a team this way. Depending on the task, up to 80% of the time to produce a machine learning model is spent on data munging and feature engineering. Good features often have a greater impact on the model than the model selection itself. But if that’s true, why transfer the responsibility for feature extraction to somebody else? In the worst case, one person spends the majority of the time building something and the other person trains a shiny model on top of it and receives all the recognition. When you rely on another person to produce something which is critical to complete your own project and the interests or motivations are not aligned, it often leads to frustration.
I’m sure many of you have experienced similar issues (in particular in bigger companies) and know how crippling this dynamic can be for a team. Here is a great thought-provoking post which goes into this issue in a lot more detail: ‘Engineers Shouldn’t Write ETL’.
What if one person was actually responsible for the whole process, i.e. building the data pipeline, model training, deployment, and more? If somebody has a brilliant idea on how to solve a problem they can just go and try it out. On the same day. With no obstacles.
Up until fairly recently, this would not have been possible because it’s simply too broad a range of skills for one person. Managed infrastructure brings us closer to this goal by eliminating the DevOps and platform engineering skills requirements. Interestingly, the current commoditisation trend in machine learning makes the required skill-set even narrower and reduces the pressure to find magical unicorns that are expected to be able to do everything.
We believe you will hear the autonomy argument a lot more often as more and more companies take advantage of a fully managed analytics infrastructure and are able to empower their data scientists to do the best they can by removing all the operational friction.
Cutting edge managed analytics infrastructure
One year ago we decided to go with BigQuery (BQ) as our data warehouse and have never looked back. Our 150+ microservices run on Kubernetes and use Cassandra as the transactional database (all on AWS). This setup makes it impossible to create snapshots of the production database and make it available for analytics (something you would usually do in a relational database environment).
Instead, we record all the messages (events) that our microservices, apps and the website emit. A separate analytics service enriches and sanitises those events and then stores them in one gigantic BQ table. This table is the source of truth for all analytics and reporting tasks. Event payloads are recorded in a JSON blob column which enables adding new types of events very easily. For the same reason, it’s simple to integrate third-party data like Stripe or Intercom webhook events.
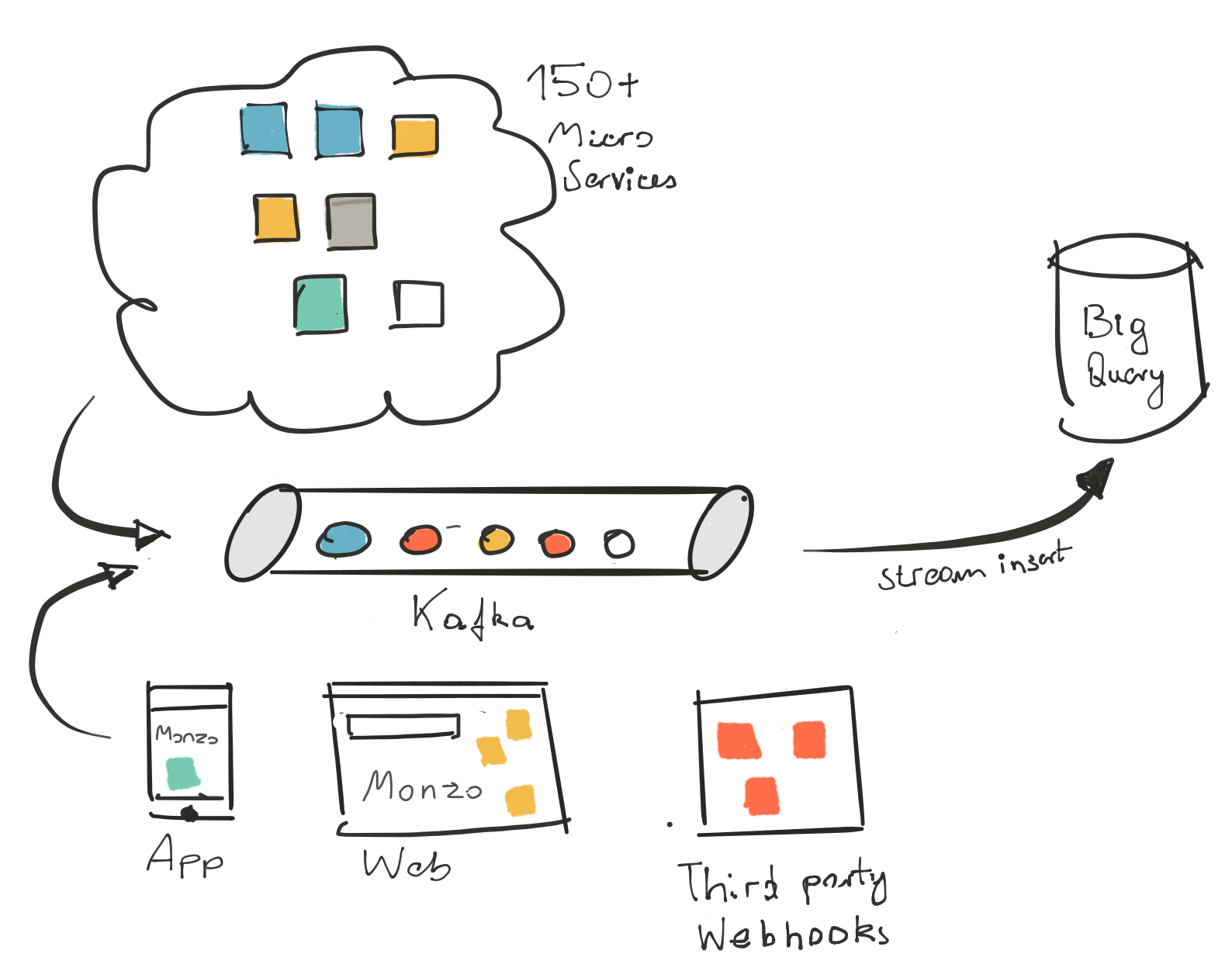
BigQuery is a natural fit for such a use case:
- It’s cheap to store masses of data (reading it afterwards can be more expensive if you are careless).
- Support for streaming inserts with basic deduplication functionality. As compared to Redshift, we don’t need to save data on S3 or Google Cloud Storage first which avoids one unnecessary step.
- Fully managed, just throw everything you can at it.
- Data is available in real-time! No nightly batches (well, at least not for the loading part)
Not everything is shiny with BQ, and we have experienced a couple of pain points so far.
- It’s a bit slow for smaller queries, with a general overhead of 2-3 seconds. Larger queries seem to be relatively fast for the volume and the compute amount that they involve. The majority of queries on Looker (our dashboarding platform) finish in 3-10 seconds. Those execution times make interactive exploration of data feel quite sluggish. We are thinking about deploying a fast serving layer with sub-second response time in the medium term. EXASOL could be an interesting in-memory analytics database to trial.
- It’s not possible to define custom partitioning keys (insertion date is the only one possible). This makes the reading of large tables expensive, even if you are only interested in a small part of it. You can partially make up for the lack of custom partitioning by creating separate tables.
- syntax and missing functions. For example, the lack of the window function last (column, exclude_null = True) to fill rows with the last non-null value, makes our scripts twice as long as they should be. I could go on about those small annoyances, but luckily Google has introduced standard SQL syntax which fixes lots of the idiosyncrasies.
With all its pros and cons, one particular thing has become apparent over time. Once the data is in BQ, it’s amazingly easy to use the rest of Google’s technology stack (even for a ‘non-hardcore’ engineer like me). It’s no surprise that one year later we use all of the following technologies:
- Dataflow, which provides a unified programming model for stream and batch processing. This means that the same code can operate in both modes with no need to write batch and stream processing pipelines separately. We use Dataflow to extract features for our fraud machine learning model. For now, it’s running in a batch mode, because its Python API does not support streaming yet
- Datastore is Google’s fully managed NoSQL transactional database. We use it in conjunction with Dataflow to extract and store features for our fraud model in real-time.
- Pub/Sub, Google’s messaging service. We’re not really actively using it now but eventually we will once streaming is an option in the Dataflow Python API.
- Cloud Machine Learning. Our fraud prediction model is built in Tensorflow, and this API is something we’re particularly excited about. We are in the early testing stage, but the initial results look promising. It took us 3 weeks to train the original model locally on a laptop! With ML API it’s almost just a matter of choosing the number of machines you want to run the training on. No DevOps skills required to setup clusters etc.
In summary, we have to deal with some limitations that come with fully managed services. However, the benefits of reduced complexity and the increased autonomy are well worth it. It lets our data team focus on things where they can add the biggest value.
Automation
Automation is obviously a broad term and is applicable almost everywhere. Here I’m referring explicitly to automation in analytics. Many analysts have a tendency to think about analytics as a collection of one-off tasks. When you do a small analysis, you write a quick one-off query or even worse, use Excel for data manipulation. Spreadsheets can be a powerful tool for modelling purposes, but often they are misused for data analytics. The problem with spreadsheets for analytics is that it’s tough to repeat, update or build robust enough transformations which don’t break every time (and consequently waste your time)
There are enough good articles out there arguing about the importance of automation and reproducibility in analytics, so I won’t dwell on it for too long. Automation makes a huge difference for Monzo by embracing one fundamental assumption. Every analysis or data pull that we do, we will need to update or repeat eventually. Be it for an investor deck or a colleague asking you for it because she wants to do a similar type of analysis.
Accepting this simple assumption as true every time you approach a problem will help you to be a lot more efficient in what you do in the medium term. If you spend 1 day extracting some data and cleaning it, why not spend 1 additional hour to make it available for everyone or for future you in the form of a dataset? Similarly with analyses, in 80% of the cases SQL + bar/line/scatter plot are enough to visualise something. So why not put it into a simple dashboard? It will be a lot easier to share, update and extend it later on. We invested early on in setting up Looker as our dashboarding solution. It gives us the ability to keep everything data related in one central hub which is documented and automated.
Sometimes you will need to use R or Python for your analyses. But also in those cases there are best practices of making your code reproducible and valuable for other analysts (see Stripe’s great article on reproducible research). Don’t accumulate dead Jupyter notebooks on your laptop
Join our team!
The combination of high autonomy, managed infrastructure, automation and a very talented engineering team have made it possible so far to support our small bank in most of our data needs as a one person team. However, we’ve reached the point now where a second person could make a significant difference. We’re therefore looking for a curious and talented Data Scientist to come work with us in London and make Monzo even more awesome.
I am keen to hear your feedback. This post should hopefully provoke some thoughts and ultimately should give some inspiration to those who are currently going through similar company building phases. Let us know what you think via Twitter (@dimitrimasin) or our community forum.
Bio: Dimitri Masin is the Head of Analytics & Data at Monzo.
Original. Reposted with permission.
Related: