Smart Data Platform – The Future of Big Data Technology
Data processing and analytical modelling are major bottlenecks in today’s big data world, due to need of human intelligence to decide relationships between data, required data engineering tasks, analytical models and it’s parameters. This article talks about Smart Data Platform to help to solve such problems.
By Xiatian Zhang, TalkingData.
The concept of big data has been in vogue for about 5 years now. Judging by Google Trends, big data was consistently and rapidly gaining increasing visibility from 2011 to 2015, after which its trendiness gradually flat-lined. The truth is that big data has moved beyond the “visionary” stage of development. People are now waiting for big data to be applied to numerous industries and generate a tremendous amount of value. TalkingData has being cultivating the field of big data in China for 5 years now. Having experienced rapid growth, we lead the big data apps industry for many traditional sectors. However, our growth has brought tremendous demands on our R&D, consulting, and data science resources. In order to ensure optimal service quality, we have had to turn away many potential clients. That’s because the value-realization process is extremely expensive. Aside from basic hardware and software investments, the biggest cost comes from human resources. A great deal of manpower is needed to build and maintain such applications. When we want to modify these apps’ goals, each change also requires further resources.
For the medium/small-sized businesses and traditional sector actors, what they really need is a relatively cheap and fancy-free version of big data—in other words, a big data platform that drastically lowers the entry requirement. Smart Data Platform is such a platform. It will drastically reduce a business’ cost to build, operate, and maintain their data platform. Businesses will be able to make their core businesses more efficient with minimal marginal cost; what’s more, they will be able to bolster their earnings from small cases and small scenarios without incurring prohibitively high expenses.
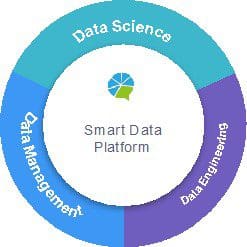
Fig. 1 Smart Data Platform
The idea of Smart Data Platform encompasses Data management, Data engineering, and data science. Right now big data’s biggest bottlenecks are data processing and analytical modelling. TalkingData have been working a solution to these two problems, and here we want to talk about their future outlook.
Currently data processing is almost entirely reliant on individual human minds. Humans are needed to decide how to cleanse, correct, standardize, and aggregate similar data—not to mention identifying data relationships. Before the arrival of big data, few regarded this as a problem. However, there have been a whopping 204 papers about data processing submitted to conferences (such as VLDB and SIGMOD) since big data became “hot” in 2012. However we are only beginning to tackle the problem of smart data processing, and there is no mature open source project or business product available. Drawing on our practical experience with and follow-up research on this topic, TalkingData has divided smart data processing into two phases—data relationship identification and data item aggregation.
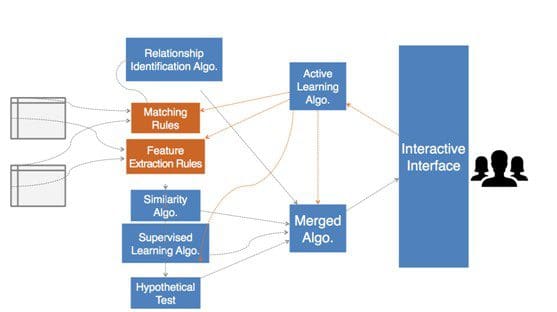
Fig. 2 Data Relationship
Data relationship identification involves first identifying all the metadata in a set of tables/files, then using the relationship between the metadata to identify the relationship between the tables/files themselves. If we are to automate this process, we must first tackle three problems.
First and the simplest of three is that how would we directly identify metadata. This can be achieved by establishing rules based on human experience. For example, if we want to identify cell phone number fields, we can establish rules based on how cell phone number are usually named. Of course, it is unrealistic to expect that pre-established rules can cover all the scenarios, and here is where active learning comes in. When the case is uncertain, the user can intervene and make a decision—which the computer will use to establish new rules.
Secondly, sometimes the metadata name do not carry any meaning, or the metadata is altogether lost. In these cases, it is impossible to judge based on the metadata alone, and we must try to identify the field’s meaning by identifying the field value’s peculiarities. To use cell phone numbers again as an example, 11-digit numbers starting with 13, 15, 18, or 17 are very likely to be cell phone numbers. If all the values in a given field match these conditions, then this field is very likely to be cell phone numbers. Similarly, we can use the combination of pre-established rules + active learning to achieve the same results. However, there is a third scenario, and this is the one that presents us with the most difficulty: We cannot identify whether a relationship exists using either of the two aforementioned methods. In this case, we need to first establish a machine learning model that will recognize common field relations, one that will decide if two fields are the one and the same by looking at their respective field values. Using this method, a machine can identify possible table/file relationships. Of course, given the AI’s limitation, it is impossible for the machine to get it 100% right. But by this procedure, humans will only need to provide occasional consulting and make the final decision. This will make data processing much more efficient.
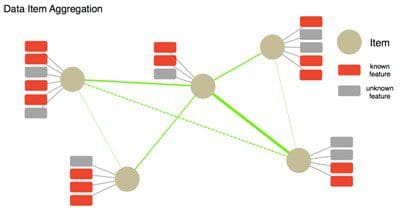
Fig. 3 Data item aggregation
Data item aggregation or similarity join is another challenging task. Due to different writing conventions and habits, the same set of data (such as names of people, places, or countries) might be written differently. When the variation is slight, similarity measure in combination with locality sensitive hashing can significantly speed up the matching process. TalkingData has achieved automatic package merging by taking into account application name, package name string similarity, application description text similarity, and deep-learning based image comparison. However, when faced with the more difficult problems, such as full name vs. abbreviation, synonyms, antonyms, or even names in different languages, we need knowledge graphs to achieve better solutions.
A major difficulty in data analysis and modelling, one that has long plagued data scientists, is how to choose models and parameters. In order to solve this problem, some data science platform companies have offered products that can automatically choose models and parameters. The idea is to try out every single possible model and its parameter space (though it’s possible they are using heuristic methods to prune the search space). This method is fine for small data sets, but it will never work for big data due to the sheer amount of computation needed. TalkingData has been working on this issue, and in Fregata (a large-scale machine learning library that will soon be open-source) we have realized several classic algorithms that do not need adjustments (Logistic Regression, Combine Features Logistic Regression, SoftMax). This way the algorithms can be integrated into the data processing cycle as intrinsic operators. Now that data scientists no longer have to adjust their parameters on a case-by-case basis, big data modelling efficiency will shoot through the roof.
Our company’s smart data platform’s short-term goals are to find solutions for the two problems discussed above. Smart data processing and smart analytical modelling will greatly increase big data apps’ efficiency and bring down their costs, make it possible for big data to be profitable for small cases and small scenarios. In this way, medium/small-sized internet companies and traditional sector companies will enjoy big data’s boon. By endowing machine with intelligence, we will be able to deal with data more efficiently than ever before, and we will achieve what is beyond our wildest dreams.
Bio: TalkingData is China’s largest, independent Big Data service platform that focuses on the mobile app marketplace. TalkingData provides best-in-class Big Data products and services, such as mobile app analytics, mobile ad tracking, mobile game analytics, mobile market intelligence, DMP (Data Management Platform), and industry consulting.
Related: