 Key Takeaways from Strata + Hadoop World 2017 San Jose, Day 1
Key Takeaways from Strata + Hadoop World 2017 San Jose, Day 1
 Key Takeaways from Strata + Hadoop World 2017 San Jose, Day 1
Key Takeaways from Strata + Hadoop World 2017 San Jose, Day 1The focus is increasingly shifting from storing and processing Big Data in an efficient way, to applying traditional and new machine learning techniques to drive higher value from the data at hand.
Last week the Data Science community had a major event – Strata + Hadoop World 2017 at San Jose. The over-arching theme across all talks and the expo was that the focus is increasingly shifting from storing and processing Big Data in an efficient way, to applying traditional and new machine learning techniques to drive higher value from the data at hand. Even as the limelight shifts from Big Data to Machine Learning (and more advanced aspects like Deep Learning), from an implementation perspective, distributed and scalable processing stays dominant as most of the popular ML models have an insatiable appetite for input data and compute power.
Here are the key takeaways from Day 1 (Wednesday, March 15, 2017):
Mike Olson, CSO and Chairman, Cloudera talked about “The machine-learning renaissance“. Most of the fundamental techniques for ML and AI were invented in 1960s and 1970s. Back then, it created a lot of hype about the potential of this field. However, all those hopes came crashing down as it hit the reality of insufficient data to feed those data models and expensive compute power to process them. We are now witnessing the ML renaissance as the key requirements (lots of data, cheaper compute) are becoming more and more affordable (thanks to the Big Data revolution).
While Map-Reduce is still relevant, most of the excitement now is directed towards the scale-out ML applications enabled by Apache Spark.
Referring to the failure of an IBM Watson project to deliver on ML promises at MD Anderson Cancer Center of Texas, he pointed out that it’s important to differentiate ML’s technological promise from the hype creating by some marketing units (including terms such as “cognitive computing”).
He introduced Cloudera Data Science Workbench as a self-service data science tool for the enterprise. He said that the Workbench will act as a bridge between the Data Science research (coded mainly in R, Python, etc.) and operationalization (coded mainly in C++ or Java for high performance execution).
Daphne Koller, Co-founder, Coursera gave an insightful talk on “Applying data and machine learning to scale education“. Since its launch in 2012, Coursera has now grown to 25 million learners (75% of them outside the U.S.) and over 2,000 courses (across 180 specializations). Such growth makes it challenging to connect a user with the course best suited to her needs.
Coursera is applying data science and machine learning to solve the content discovery problem and generate relevant course recommendations. This is done through a 2-level classifier. At the highest level, courses are clustered into 100 clusters using t-SNE embedding on course co-enrollment matrix. The second classifier is used to identify a specific course within the cluster to be recommended to the user.
A hierarchical structure is created from the content based on careful human curation and analytics, in order to map the courses to the skills (what users are actually interested in) they offer. The recommendation results are further enhanced through crowdsourcing – feedback surveys asking for objective as well as subjective responses.
She mentioned that the field of education is lacking far behind in using data science for improvement and effectiveness.
Ted Dunning, Chief Application Architect, MapR Technologies talked about “Turning the internet upside down: Driving big data right to the edge”. As of today, the internet infrastructure is based on a small number of large servers serving a large number of consumers. The total investment is dominated by the last mile i.e. the consumer base. However, the cost is driven by the other end – servers, where bit density as well as dollar density are high.
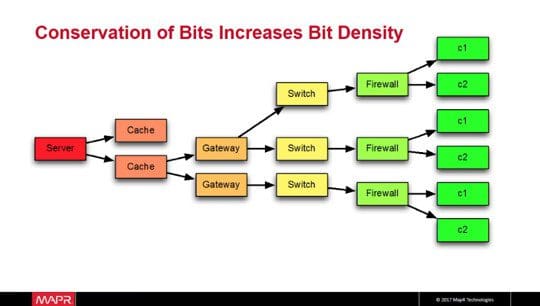
In the Internet-of-Things paradigm, the infrastructure design gets flipped. There are billions of machines collecting and processing data, and they pass on some metrics to the servers. In such a model, the cost is driven by the large number of machines (individual nodes or small clusters), whereas revenue is driven by the server and other platform devices, which can do more valuables tasks due to lower bit density.
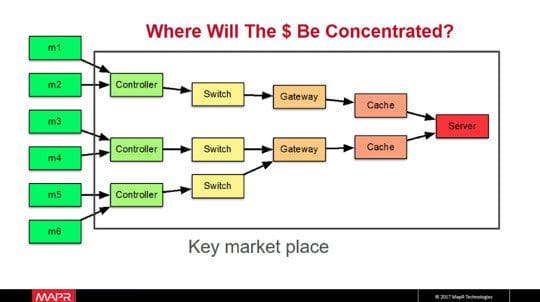
He introduced MapR Edge, a platform specifically designed for Internet-of-Things, which would capture, process and analyze IoT data close to the source, while sharing key metrics with a centralized server.
In an interview with Beau Cronin (Lead Developer, Embedding.js), Phil Keslin (CTO, Niantic) talked about the experience of launching Pokemon GO. Phil mentioned that the Keyhole (acquired by Google in 2004) experience helped gain a solid understanding of the planet, which played a key role in conceptualizing a geospatial game. At Keyhole, his team primarily used satellite data from 1990s and it was huge (for those years) – 7 TBs compressed. Phil confessed that he had never expected Pokemon GO to become such a big success so soon. It was only after a few days of its first launch in Australia and New Zealand, he realized that after global launch it would be way more popular than initially expected.
The entire distributed infrastructure of Pokemon GO was built by 4 core server engineers. The team started with a strong architecture, did some experiments with Ingress, and prepared well for scaling up when needed. He mentioned that enabling Pokemon GO was more of a “big compute” challenge than a “big data” challenge.
Talking about things that could have been done better, Phil said they could have spent some more time understanding performance characteristics of third party software (including open source). Lastly, he shared an advice that one should be absolutely clear about what problem one is solving and stay focused on it, in order to succeed.
Rajiv Maheswaran, Co-founder and CEO, Second Spectrum gave a very interesting talk on “When machines understand sports”. He mentioned that initially it was quite challenging to convince coaches that analytics can help their players get better at the game. Visualization (specifically designed for its non analytics-savvy audience) was a key component of convincing coaches and players to include data analytics into their practice strategy. Today, almost every major NBA team is using data analytics in their game strategy on and off the field.
Second Spectrum has so far developed analytics applications for basketball and soccer. Rajiv concluded by sharing the grand vision that one day every sport will leverage analytics to enable each player to reach their best potential.
Jure Leskovec, Chief Scientist, Pinterest (and Professor at Stanford University), explained the mechanism behind “Recommending 1B+ items to 100M+ users in real time: Harnessing the structure of the user-to-object graph to extract ranking signals at scale”. The modern recommender system (called Pixie) deployed at Pinterest works in two phases – candidate generation and ranking. Candidate generation takes the input of user query and the candidate pool (1B+ items such as pins, boards, etc.), and shortlists 1K candidates. Then, a machine learning based Ranking module processes these 1K candidates to generate a sorted list of recommendations. The Ranking module implements Personalized PageRank via RandomWalks (similar to what PageRank does for Google Search).

In order to achieve real time speed, the Pinterest graph needs to be loaded entirely into memory, which is nearly impossible given that it has +100B edges. So, several pruning strategies are used to condense the graph to highly popular items. This enables the graph to fit in about 100GB RAM. Jure explained how this architecture can serve various business use cases towards enabling responsive radical personalization. One of the key achievements of this recommender system was that the recommendation results do include relevant pins even if they are unpopular, thereby, leveraging the “dark” content.

Robert Grossman, Faculty and Senior Fellow, University of Chicago delivered a talk on “The dangers of statistical significance when studying weak effects in Big Data: From natural experiments to p-hacking”. Through case studies, he highlighted the importance of disclosing the entire data analysis work (including negative results); making data, code, and computing environment available to other researchers; and working collaboratively with peers so that the data from discipline is available for harmonized processing and a meta-analysis. He recommended the following 5 principles for data analysis:

Related: