Do We Need Balanced Sampling?
Resampling is a solution which is very popular in dealing with class imbalance. Our research on churn prediction shows that balanced sampling is unnecessary.
By Bing Zhu (Sichuan University), Bart Baesens (KU Leuven) & Seppe vanden Broucke (KU Leuven).
In many real-world classification tasks such as churn prediction and fraud detection, we often encounter the class imbalance problem, which means one class is significantly outnumbered by the other class. The class imbalance problem brings great challenges to standard classification learning algorithms. Most of them tend to misclassify the minority instances more often than the majority instances on imbalanced data sets. For example, when a model is trained on a data set with 1% of instances from the minority class, a 99% accuracy rate can be achieved simply by classifying all instances as belonging to the majority class. Indeed, the problem of learning on imbalanced data sets is considered to be one of the ten challenging problems in data mining research.

In order to solve the problem of learning from imbalanced data sets, many solutions have been proposed in the past few years. Resampling approaches try to solve the problem by resampling the data and act as a preprocessing phase. Their usage is assumed to be independent of the classifier and can be applied to any learning algorithm. Hence, resampling solutions are very popular in practice. One important question when we use resampling is whether we actually need a perfectly balanced data set. Our research on churn prediction shows that a balanced sampling is unnecessary.
We used 11 real-world data sets from the telecommunication industry in our experiments. Seven sampling methods were considered, which include random over-sampling, random under-sampling SMOTE sampling and so on. We consider three different settings for the class ratios: 1:3, 2:3 and 1:1 (minority vs majority). Four benchmark classifiers are used in the experiments: logistic regression, C4.5 decision tree, support vector machine (SVM) and random forests (RF), which are widely used in churn prediction. The following table shows part of the results by using a 5 × 2 cross-validation experimental setup, where each entry represents the mean performance of each sampling rate across different classifiers and sampling methods. Beside the AUC measure, we also consider the maximum profit measure, which measures the profit produced by a retention campaign (Verbraken et al., 2013).
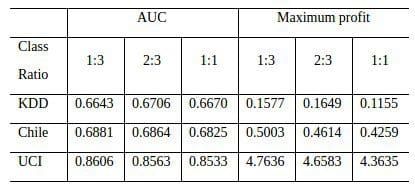
As the table shows, the ratio of 1:3 is the best on two data sets and the ratio of 2:3 ranks the first on two data sets. The balanced class ratio never reaches the top position. The results definitely show there is no need to produce balanced data sets after sampling and the less balanced strategy (1:3) would be our recommendation due to its relatively good performance. The complete results and more discussions can be found in our recent paper “Benchmarking sampling techniques for imbalance learning in churn prediction” published in JORS.
References:
- H. He, E. Garcia, Learning from imbalanced data, IEEE Transactions on Knowledge and Data Engineering, 2009, 21(9): 1263-1284.
- W. Verbeke, K. Dejaeger, D. Martens, J. Hur, B. Baesens, New insights into churn prediction in the telecommunication sector: A profit driven data mining approach, European Journal of Operational Research, 2012, 218(1): 211 -229.
- T. Verbraken, W. Verbeke, B. Baesens., A Novel Profit Maximizing Metric for Measuring Classification Performance of Customer Churn Prediction Models, IEEE Transactions on Knowledge and Data Engineering, 2013, 25(5), 961-973, 2013.
- B. Zhu, B. Baesens, A. Backiel, S. vanden Broucke. Benchmarking sampling techniques for imbalance learning in churn prediction, Journal of the Operational Society, 2017.
Bing Zhu is an associate professor at the Business School of Sichuan University in China. His main research interests include churn prediction and fraud detection.
Bart Baesens is a professor of Big Data and Analytics at KU Leuven (Belgium). He has done extensive research on Big Data and Analytics. His findings have been published in well-known international journals and presented at international top conferences.
Seppe vanden Broucke is working as an assistant professor at the department of Decision Sciences and Information Management at KU Leuven. Seppe's research interests include business data mining and analytics, machine learning, process management, process mining.
Related: