 The Rise of GPU Databases
The Rise of GPU Databases
 The Rise of GPU Databases
The Rise of GPU DatabasesThe recent but noticeable shift from CPUs to GPUs is mainly due to the unique benefits they bring to sectors like AdTech, finance, telco, retail, or security/IT . We examine where GPU databases shine.
By Ami Gal, CEO SQream.
You might not have realized it, but this year saw an important revolution in the way we design and use computing resources. The change? Many businesses and cloud providers began shifting from traditional central processing unit (CPU) processing to using a graphics processing unit (GPU). GPU databases are the latest development in this trend, and they have the potential to completely change the way databases operate.

Here’s how they change the game and where they’re best applied:
Benefits of a GPU Database
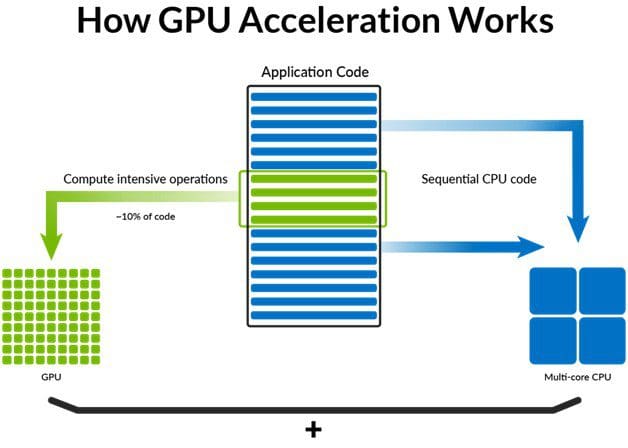
GPU databases offer significant improvements over the conventional CPU database when performing repetitive operations on large amounts of data. This is because GPUs can have thousands of cores and high bandwidth memory on each card.
The GPU offers many unique benefits;
- More rapid innovation. GPUs still conform to Amdahl’s law, typically increase in efficiency at twice the rate of CPUs with a much faster release cycle
- GPUs are typically 10x-100x faster at processing the same workloads, compared to CPUs
- GPUs are much smaller (6.5x – 20x smaller than a CPU.) Just 16 GPU-accelerated servers could perform as well as a 1000 CPU cluster
- The ability to visualize and process data in real time. Since the data is on a powerful graphics rendering engine anyway, the results are displayed at lightning speed!
- Very fast data ingestion rates
- Near real-time data exploration – Real-time data exploration and fast ingest rate typically mean data scientists and machine learning algorithms really benefit a lot from using the GPU.
Where GPU Databases shine
Just a year or two ago, many in the database world dismissed GPU databases as a fad, perhaps only applicable in small niches alongside in-memory databases. They said that traditional databases were still the way to go.
However, some innovative companies didn’t see it that way. Very quickly, the use of GPU databases has dramatically expanded, with installations across all verticals – including finance, telecoms and even the notoriously late-blooming government sector. Why? Put simply, GPU databases shine when used for analytics, and with a fraction of the investment.
GPU databases are a perfect complement for Hadoop which was never designed for relational data analytics. One can look at the U.S. Postal service, which is now using a rack of GPU servers, to understand the advantage. The USPS covers 154 million addresses spread over 200,000 delivery routes, and analyzes each carrier’s location data. So, you can imagine they’ve got a large database.
With this data, they can estimate delivery times, provide real-time notifications to supervisors, and optimize ad-hoc routes. Thanks to their GPU database, they can process these complex queries in the time it takes to load a web page. That’s pretty impressive.
GPU databases represent a tremendous opportunity for AdTech, finance, telco, retail, security/IT, and even the energy industry. They’ve also seen extensive usage in the defense-intelligence complex.
Who Benefits from GPU databases?
While it may seem trivial that all parts of the business may benefit from faster querying, faster ingests and reduced IT costs, it is really the data scientists who benefit the most from GPU databases.
Lightening fast ingest and querying means that typical cycles of data science work are reduced from days to hours. Other workloads may be reduced from hours to minutes or even seconds. Shortening these cycles for these business-critical data science and machine learning workloads, elevates data scientists from common “second-class” database users, to the primary beneficiaries of the GPU databases.
How are GPU Database projects implemented?
- Most GPU databases run on the cloud with environments ranging from IBM Bluemix to Amazon AWS. However, on premise databases and hybrid setups are possible as well. Once the database is set up, standard SQL is used to query data using industry standard drivers including:
- JDBC, ODBC
- Python, Jupyter, sklearn…
- R and other ML libraries
After that, scaling up is typically as easy as adding another GPU to the box. Since each GPU features so much computing power, adding a new box is less common. In fact, with some GPU databases, up to 100TB of raw data can be stored and queried in a standard 2U server.
The whole setup process for most GPU databases is usually incredibly simple, requiring little data modeling and no new/expensive development and usage skills. Most GPU databases are often compatible with your ecosystem as well. They play nice with your existing data sources, data acquisition tools, and even your BI, reporting, analytics, and visualization tools
Final Thoughts
Given that the volume of data is now doubling every two years, storage systems are predicted to hold around 17.6 Trillion gigabytes of data by the end of the year. But, big data is only as useful as its rate of analysis. With fast analysis, your data will add value to your organization in ways you can’t yet imagine.
If your business is dependent on a traditional database you should already be thinking about the kind of GPU database that would be right for you. After all, the demands on your system are only going to continue to increase.
Bio: Ami Gal is CEO & Co-founder at SQream.
Related: