Learn Generalized Linear Models (GLM) using R
In this article, we aim to discuss various GLMs that are widely used in the industry. We focus on: a) log-linear regression b) interpreting log-transformations and c) binary logistic regression.
By Chaitanya Sagar, Perceptive Analytics.
Editor's note: Data files discussed below can be acquired here:
Generalized Linear Model (GLM) helps represent the dependent variable as a linear combination of independent variables. Simple linear regression is the traditional form of GLM. Simple linear regression works well when the dependent variable is normally distributed. The assumption of normally distributed dependent variable is often violated in real situations. For example, consider a case where dependent variable can take only positive values and has fat tail. The dependent variable is number of coffee sold and the independent variable is the temperature.
Let's assume that we have modeled a linear relationship between the variables. The expected number of coffee sold decreases by 10 units as temperature increases by 1 degree. The problem with this kind of model is that it can give meaningless results. There will be situation when a increase of 1 degree in temperature would force the model to output negative number for number of coffee sold. GLM comes in handy in these types of situations. GLM is widely used to model situations where the independent variable has arbitrary distributions i.e. distributions other than normal distribution. The basic intuition behind GLM is to not model dependent variable as a linear combination of independent variable but model a function of dependent variable as a linear combination of dependent variable. This function used to transform independent variable is known as link function. In the above example the distribution of number of coffee sold will not be normal but poisson and the log transformation (log will be the link function in this case) of the variable before regression would lead to a logical model. The ability of GLM to transform data with arbitrary distribution to fit a meaningful linear model makes it a powerful tool.
In this article, we aim to discuss various GLMs that are widely used in the industry. We focus on: a) log-linear regression b) interpreting log-transformations and c) binary logistic regression. We also review the underlying distributions and the applicable link functions. However, we start the article with a brief discussion on the traditional form of GLM, simple linear regression. Along with the detailed explanation of the above model, we provide the steps and the commented R script to implement the modeling technique on R statistical software. For the purpose of illustration on R, we use sample datasets. We hope that you find the article useful.
Linear Regression
Linear regression is the most basic form of GLM. Linear regression models a linear relationship between the dependent variable, without any transformation, and the independent variable. The model assumes that the variables are normally distributed. It is represent in the form Yi= α+ βXi [Eq. 1]. The coefficients are computed using the Ordinary Least Square (OLS) method. For a detailed explanation on linear regression and OLS, please refer to our earlier article at https://www.kdnuggets.com/2017/03/building-regression-models-support-vector-regression.html. The article provides explanation and an example of linear regression. We hope that now you are comfortable with the idea of linear regression.
Now, with the objective of showing limitation of linear regression, we will implement the linear model on R using a not so perfect case. The data consists of two variables - Temperature and Coca-Cola sales in a university campus. Please click here to download. Let us visualize the data and fit a linear model to predict sales of coca cola based on given temperature. The R code is below:
## Prepare scatter plot
#Read data from .csv file
data = read.csv("Cola.csv", header = T)
head(data)
#Scatter Plot
plot(data, main = "Scatter Plot")
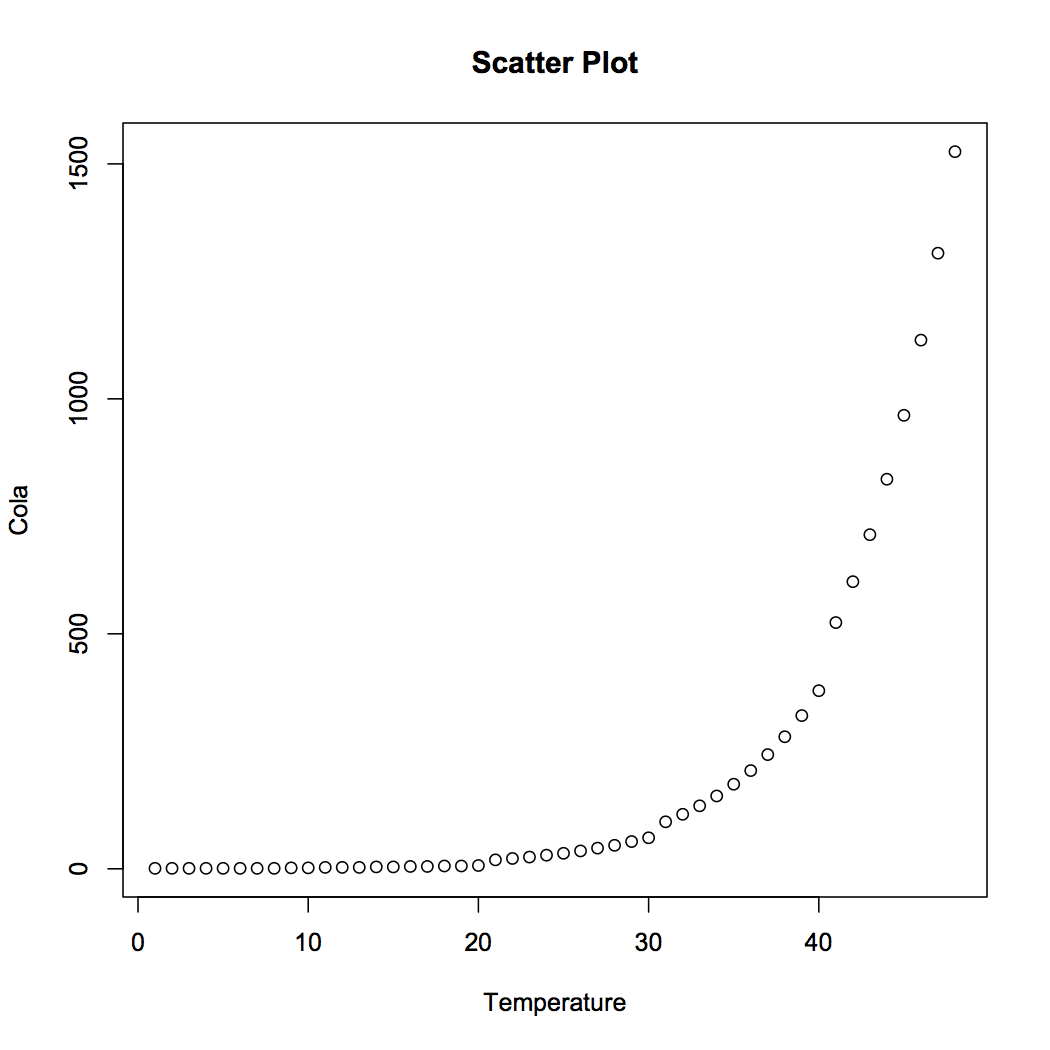
Figure 1 visualizes the data to provide us with a better understanding of the relationship between Temperature and Coca-Cola sales. We observe that sales increase exponentially with increase in temperature.
## Add best-fit line to the scatter plot
#Install Package
install.packages("hydroGOF")
library("hydroGOF")
#Fit linear model using OLS
model = lm(Cola ~ Temperature, data)
#Overlay best-fit line on scatter plot
abline(model)
#Calculate RMSE
PredCola = predict(model, data)
RMSE = rmse(PredCola, data$Cola)
The relationship between Temperature and Cola Sales is represented in Equation [2]. The Root Mean Square Error for the model is pretty high at 241.49. The values of cola sales can be obtained by plugging the temperature in the equation.
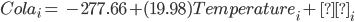 [2]
[2]
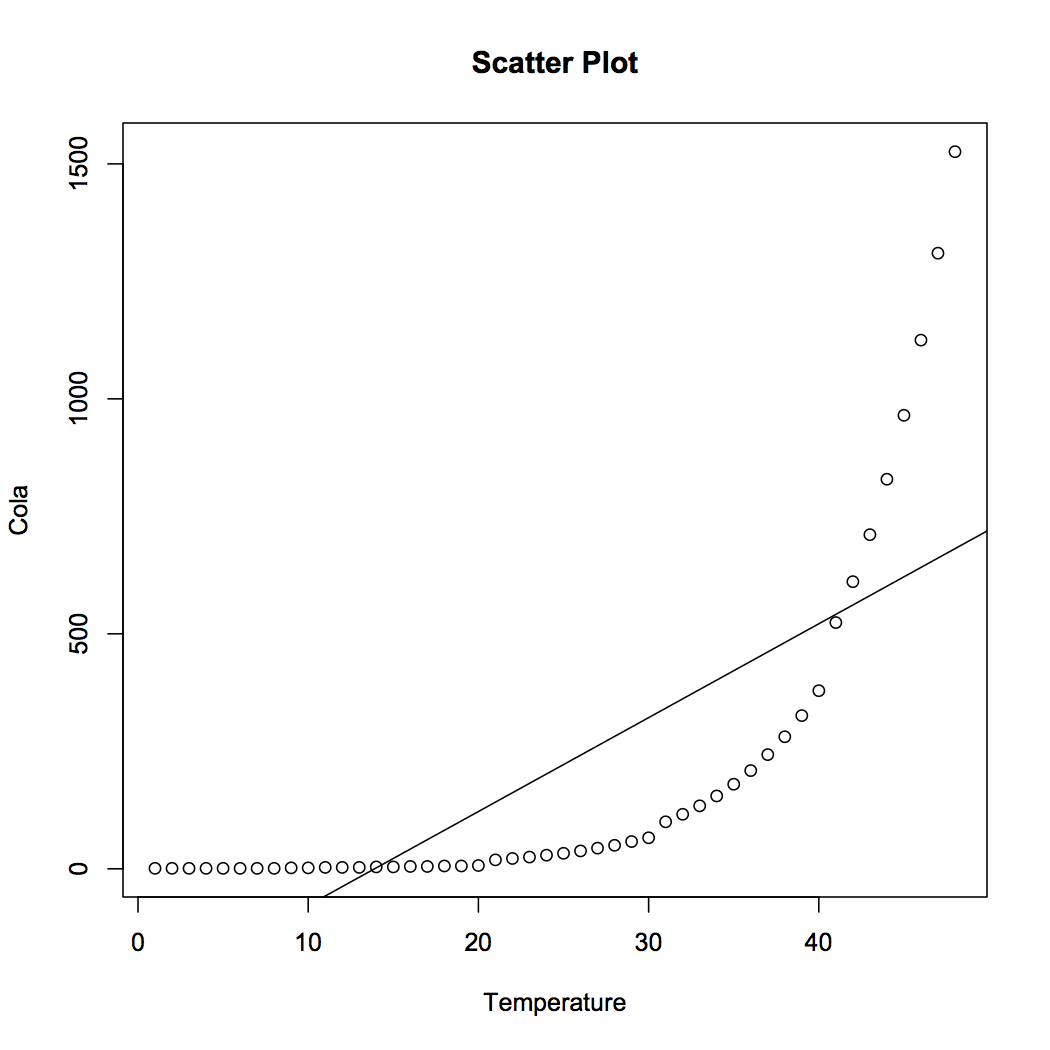
Figure 2 shows the best-fit line as per the simple linear regression. The fit is bad and leads to absurd predictions. As per the model the Cola sales will be negative for temperature below 10 units. There are two ways to deal with the situation. First, fit a non-linear model. Second, transform the data to fit a linear model. In the next section we will discuss the second method.
Log-Linear Regression
Log-linear regression becomes a useful tool when the dependent and independent variable follow an exponential relationship. It means that Y does not change linearly with a unit change in X but Y changes by a constant percentage with unit change in X. For example, the amount due, in case of compound interest, follows an exponential relationship with time, T. As T increases by one unit, the amount due increases by a certain percentage i.e. interest rate. Another example can be that of expected salary and education. Expected salary does not follow a linear relationship with level of education. It grows exponentially with level of education. Such growth models depict a variety of real life situations and can be modeled using log-linear regression. Apart from exponential relationship, log transformation on dependent variable is also used when dependent variable follows: a) log-normal distribution - log-normal distribution is distribution of a random variable whose log follows normal distribution. Thus, taking log of a log-normal random variable makes the variable normally distributed and fit for linear regression. b) Poisson distribution - Poisson distribution is the distribution of random variable that results from a Poisson experiment. For example, the number of successes or failures in a time period T follows Poisson distribution.
In this article we focus on the exponential relationship, which is expressed as Y=a(b)X [Eq. 2]. In this case, a log transformation would make the relationship linear. We can represent log(Y) as a linear combination on Xs. Taking log on both sides in the equation, we get log (Y)=log(a)+log(b)X. Now we can estimate the model using OLS. Please note that this equation is very similar to Eq. 1, log(a) and log(b) are equivalent to α and β respectively. Now we will look into interpretation of log linear models. log(a) is the constant term and log(b) is the growth rate with which Y grows for a unit change in X. A negative value of log(b) would indicate that Y decreases by a certain percentage for unit increase in X. Now we will implement the model on R using the Coca-Cola sales data. The R code is below.
## Fitting Log-linear model # Transform the dependent variable data$LCola = log(data$Cola, base = exp(1)) #Scatter Plot plot(LCola ~ Temperature, data = data , main = "Scatter Plot") #Fit the best line in log-linear model model1 = lm(LCola ~ Temperature, data) abline(model1) #Calculate RMSE PredCola1 = predict(model1, data) RMSE = rmse(PredCola1, data$LCola)
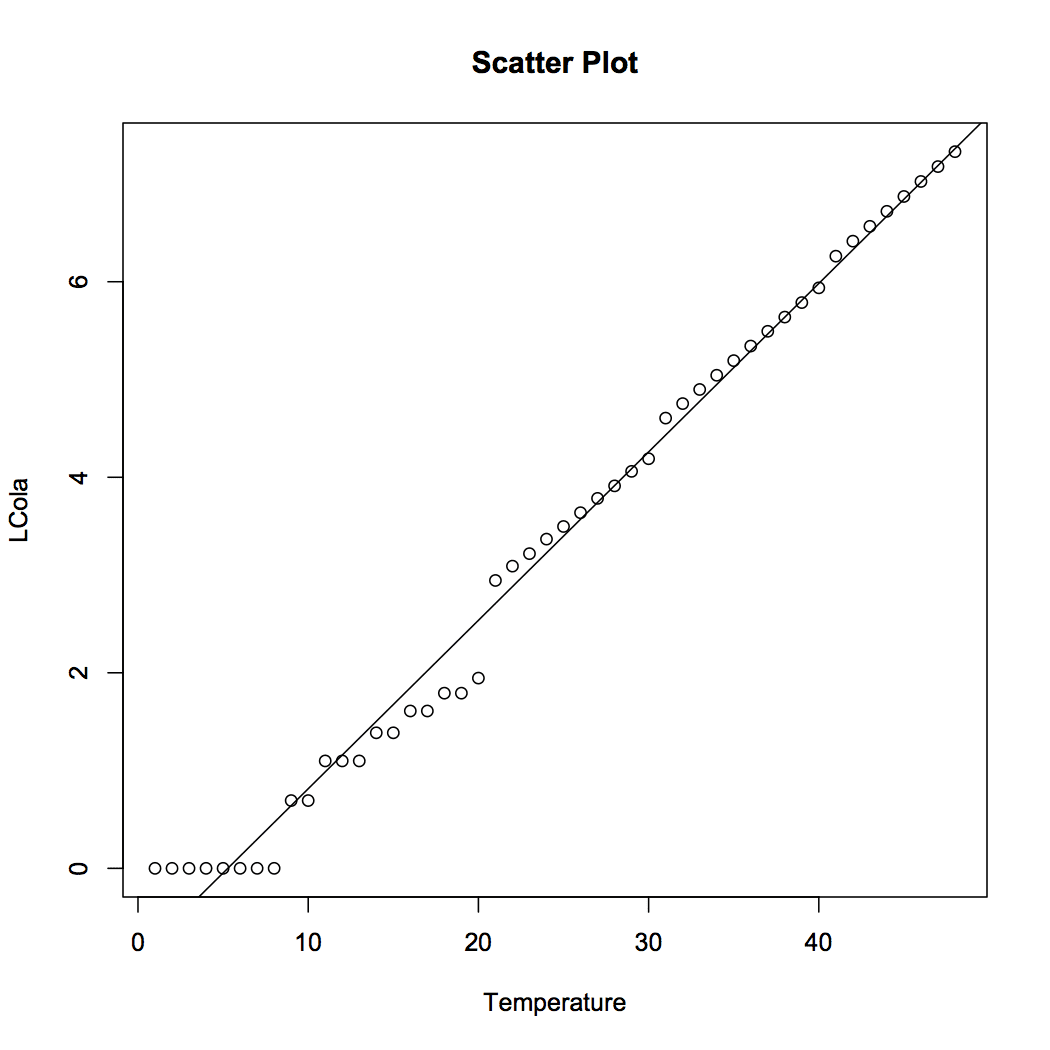
Figure 3 displays the best-fit line using log-linear regression. We can look at it as a two-step process i.e. data transformation by taking log on both sides and then using simple linear regression on the transformed data. The computed model is as follows:
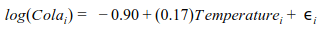 [3]
[3]
The Cola sales can be predicted by plugging the values of temperature in Equation [3]. We observe that the fit has greatly improved over the simple linear regression. The RMSE for the transformed model is 0.24 only. Please note that log-linear regression has also solved the issue of absurd negative values for cola sales. For no value of temperature we get a negative value of cola sales. A simple log transformation helps us to deal with the absurdity. In the next section we will discuss other log transformations that come handy in various situations.