An opinionated Data Science Toolbox in R from Hadley Wickham, tidyverse
Get your productivity boosted with Hadley Wickham's powerful R package, tidyverse. It has all you need to start developing your own data science workflows.
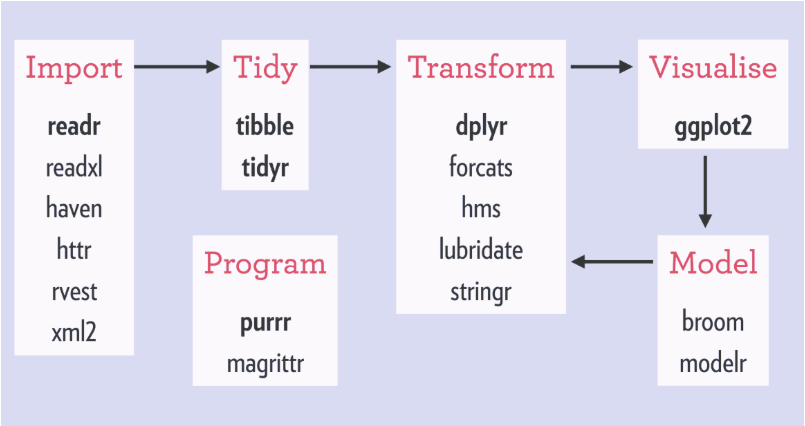
In this post, we will make a summary of tidyverse, a set of R packages that share a common data representation and API design for harmony and fluency in the data science workflow, designed for better consistency, and easy to install. It can be considered as the data science and data management toolbox in R as it was built for guiding its users through workflows that improve reproducibility and communication.
With this package loaded into your project, you can easily perform the fundamental data science tasks like importing, plotting, wrangling and modeling data as well as functional programming for new developments. The bone marrow of this super package is comprised of a robust array of R packages as ggplot2, dplyr, tidyr, readr, purr, and tibble among others. We will go into the details of each of these packages further along as we will show some basic examples to get you started with this amazing toolbox. This package is intended to be a harmonious and compatible set of tools and commands that bring to life the by-the-book definition of an effective data science workflow.
First, the history of tidyverse, how it came to be and who is the mastermind behind it. This ‘package of packages’ was developed by Hadley Wickham, Chief Scientist at RStudio and co-author of the amazing O’Reilly series book “R for Data Science”; he is also in charge of maintaining it to its best. You may already be familiar with Hadley as he developed previous R packages like reshape, reshape2, and plyr; which in turn, were building blocks of tidyverse as a product of several experiments and versions. It was created for statisticians and data scientists with the sole purpose of boosting their productivity and as an attempt to reproduce and abstract the Canonical Data Science Workflow (figure) into an actual product. This is an extremely versatile and consistent package as its powerful features range from productivity and workflow enhancement to new data science software development and data science education.

It is important to expand a bit more on the general features of this package, so we can see it in action later in our practical example. Its consistency is deeply rooted in the fact that variables, functions, and operators follow regular patterns and syntax. For example, the first argument of every function will be a tidy data frame (one row per observation, one column per variable, one entry by cell). To perform operations, one can intuitively connect a sequence of commands, base functions, and operators to create a tidy pipeline. The way in which the core packages are organized, the coding style and testing procedures comprise a second, lower-level degree of consistency, so when we say the word “consistent”, it should not be taken lightly. Finally, because there is a one-to-one relationship between the analysis workflow processes and the different tidyverse sub-packages, it is extremely easy to establish effective end-to-end workflows that respond to specific analytic purposes and utilize several types of data.
It is therefore not a surprise to see an increasing popularity among its users, both experienced and beginners. In fact, those looking to learn R in Data Science should definitely start with tidyverse as it has a friendly, low-steep learning curve that allows an early-career professional to clean and tackle nontrivial datasets in short time.
Now, let’s dig deeper into each of the core packages so we can have an overview of the fluency and consistency we mentioned. You may look at the documentation linked below for further information on the additional packages that are loaded when using tidyverse.
- Import your data: The main package here is readr. It is a friendly and fast way of reading rectangular data and its flexibility allows parsing different data types. Additional to readr, secondary packages will be loaded as well, such as readxl and haven among others. You may find more information here.
- Clean your data: The packages of choice are tibble and tidyr.
- tibble is an optimized way of storing data. Think of a tibble as a reimagined version of an R data frame, although quite stubborn and sluggish. However, this is not a limitation but a good thing as it requires that you tackle issues early in the pipeline, which will lead to a more elegant code. For more information visit this link.
- tidyr allows you to create tidy data, i.e., one column for each variable; one row for each observation and one value per cell. With its new functions gather() and spread() you can perform the classic “cast” and “melt” from previous R packages so you can go from wide to long and vice versa easily and effectively. More information on tidyr here.
- Transform your data: The core package is dplyr, one of the most popular in the R language. It is a set of grammatically consistent verbs for data manipulation and it is incredibly intuitive and powerful. Its primary functions are mutate(), filter(), select(), summarise(), and arrange(). These can be used to perform operations by group by using the command group_by(). More information on tidyr here.
- Visualize your data: For this task use ggplot2, a powerful and elegant way to create data visualizations based on the Grammar of Graphics. You simply input your data, declare your aesthetics with the variables and choose the type of geometry, ggplot2 will take handle the rest. More information on tidyr here.
- Program your analysis: purrr. If now you want to use R’s functional programming you may use the family of map() functions from this package. It allows you to iterate over your data in a clear and concise manner. Visit this link for more information.
Now, let’s get started. For this example, we will be using the Titanic dataset from the Kaggle competition, which you may easily download here. The purpose of our example is to run you through some common operations you can perform in tidyverse and show a bit more the syntax and the power of the consistency of this super R package. I hope you enjoy reproducing this code yourself. I encourage you to go through the documentation so you can come up with your own tidyverse recipes for data analysis.
Note: You will see a particular this symbol (‘%>%’) very often throughout the example. This is called the pipe operator and it is very useful when scripting as it allows you to keep track of the logic of your analysis. Think of it in the following way: The function f(x) is now expressed as x %>% f.
For more documentation on tidyverse go to the Official site and see additional examples.
If you are starting out with R and would like to learn more about the usage of tidyverse, the book “R for Data Science” by Hadley Wickham is the best resource out there.
Also, for another great summary on tidyverse and its features, this post from R Views is an amazing reference.
Related: