How to do Machine Learning Efficiently
I now believe that there is an art, or craftsmanship, to structuring machine learning work and none of the math heavy books I tended to binge on seem to mention this.
By Radek Osmulski, Self-taught Developer
I have just come out of a project where 80% into it I felt I had very little. I invested a lot of time and in the end it was a total fiasco.
The math that I know or do not know, my ability to write code — all of this has been secondary. The way I approached the project was what was broken.
I now believe that there is an art, or craftsmanship, to structuring machine learning work and none of the math heavy books I tended to binge on seem to mention this.
I did a bit of soul searching and went back to what Jeremy Howard mentioned in the wonderful Practical Deep Learning for Coders MOOC by fast.ai and that is how this post was born.
The 10 second rule
We sit in front of a computer to do things. To make a dent in the universe. To lower the cost of our predictions or decrease the run time of our model.
The key word here is doing. That entails moving code around. Renaming variables. Visualizing data. Smashing away on your keyboard.
But staring blankly at a computer screen for two minutes while it performs calculations so that we can run them again and again but with slightly modified parameters is not doing.
This also leaves us open to the greatest bane of machine learning work — the curse of the extra browser tab. So easy to press ctrl+t, so easy to lose track of what we have been doing.
The solution might sound ridiculous but it works. Do not ever allow calculations to exceed 10 seconds while you work on a problem.
But how can I tune my parameters then? How can I learn anything meaningful about the problem?
All it takes is to subset your data in a way that can create a representative sample. This can be done for any domain and in most cases requires nothing more than randomly choosing some percentage of examples to work with.
Once you subset your data work becomes interactive. You enter a flow state of uninterrupted attention. You keep running experiments and figuring out what works and what doesn’t. Your fingers never leave your keyboard.
Time stretches and the hour of work that you do is not equal to the hour of work you would have done, not even 5 hours of work, had you allowed yourself to be distracted.
How to structure your code to facilitate this workflow? Make it very simple to switch to running on the full dataset.
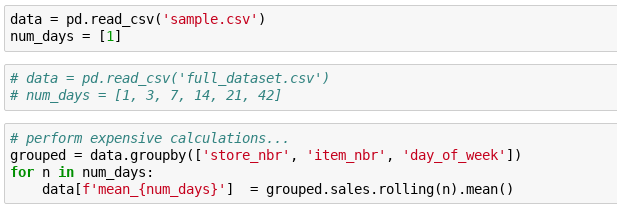
When about to finish your coding session, uncomment the cell and run all.
Be a time spammer
This supplements the above. But it is also so much more.
There are orders of magnitude of gains in performance that can be attained based on how you structure your code. It is good to know how long something runs and how long it will run if you make this or that change. You can then try to figure out why the difference and it will immediately make you a better programmer.
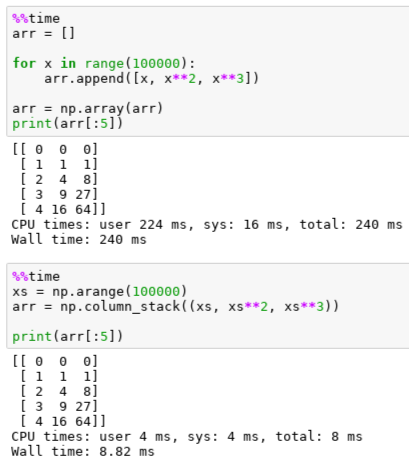
On top of that, this goes hand in hand with the commitment to never run anything that takes more than 10 seconds.
Test yourself
Once you make a mistake in your data processing pipeline and it goes unnoticed, it is nearly impossible to recover. To a large extent this also applies to model construction (particularly if you develop your own components such as layers, etc).
The key is to inspect the data as you go along. Look at it before and after transformation. Summarize it. If you know there should be no NAs after a merge, check that there indeed are not.
Test everything.
The only way to maintain your sanity in the long run is to be paranoid in the short run.
Rush to success
What is the very second thing you should focus on when working on a problem (I will speak to the first thing to do in just a second)? Create any model, any end to end data manipulation pipeline, that is better than random chance.
It can and should be the simplest model you can think off. Very often this will mean a linear combination. But you want to start getting a feel for the problem. You want to start forming a baseline of what is possible.
Say you spend 3 days on constructing a super elaborate model and it doesn’t work at all, or doesn’t work remotely as well as you suspected it should. What do you do?
You know nothing at this point. You do not know if you made a mistake with processing your data, you do not know if your data is garbage. You have no clue if maybe there is something wrong with your model. Good luck untangling this mess without having components you can rely on.
Also, getting a simple model in place will allow you to get a bird’s eye view of the situation. Maybe there is missing data? Maybe the classes are imbalanced? Maybe the data is not properly labeled?
It is good to have this information before starting to work on your more complex model. Otherwise you risk building something very elaborate that might objectively be great while at the same time being completely unsuited to the problem at hand.
Don’t tune the parameters, tune the architecture
“Oh if I just maybe add this single linear layer, I’m sure the model will sing to me”
“Maybe adding 0.00000001 more dropout will help, seems like we are fitting our train set a little bit too well here”
Especially early on, it is absolutely counter productive to tune hyperparameters. Yet it is beyond tempting to do so.
It requires little to no work, it is fun. You get to see numbers on your computer screen change and it feels like you are learning something and making progress.
This is a mirage. Worse yet, you might be overfitting your validation set. Every time you run your model and make changes based on validation loss, you incur a penalty on your model’s ability to generalize.
Your time is better invested in exploring architectures. You learn more. Suddenly ensembling becomes a possibility.
Free the mice
How long are you planning on using the computer? Even if I were to accidentally become well off to the point where I don’t have to work another day, I would still use the computer daily.
If you play tennis, you practice each move. You might even go as far as paying someone to tell you how to position your wrist for a specific shot!
But realistically, you will only play this many hours of tennis. Why not be similarly conscious about how you use the computer?
Using the mouse is unnatural. It is slow. It requires complex and precise movements. From any context you can only access a limited set of actions.
Using the keyboard sets you free. And I will be honest with you — I do not know why it makes such a difference. But it does.

A person working on their computer without using the mouse.
Last but not least
Nothing that you do will have any meaning unless you have a good validation set.
May I refer you to the ultimate resource on this. An article that holds no punches and that is based in practice.
How (and why) to create a good validation set by Rachel Thomas.
If you found this article interesting and would like to stay in touch, you can find me on Twitter here.
Bio: Radek Osmulski is a self-taught developer who is passionate about machine learning. He is a Fast.ai International Fellow and an active student of the field. You can connect with him on Twitter here.
Original. Reposted with permission.
Related:
- 5 Things to Know About Machine Learning
- A Tour of The Top 10 Algorithms for Machine Learning Newbies
- 7 Steps to Mastering Machine Learning with Python