 5 Things to Know About Machine Learning
5 Things to Know About Machine Learning
 5 Things to Know About Machine Learning
5 Things to Know About Machine LearningThis post will point out 5 thing to know about machine learning, 5 things which you may not know, may not have been aware of, or may have once known and now forgotten.
There is always something new to learn on any fast-evolving topic, and machine learning is no exception. This post will point out 5 things to know about machine learning, 5 things which you may not know, may not have been aware of, or may have once known and now forgotten.
Note that the title of this post is not "The 5 Most Important Things..." or "Top 5 Things..." to know about machine learning; it's just "5 Things." It's not authoritative or exhaustive, but rather a collection of 5 things that may be of use.
1. Data preparation is 80% of machine learning, so...
It's fairly well-discussed that data preparation takes a disproportionate amount of time in a machine learning task. Or, at least, a seemingly disproportionate amount of time.
What is commonly lacking in these discussions, beyond the specifics of performing data preparation and the reasons for its importance, is why you should care about performing data preparation. And I don't mean just to have conforming data, but more like a philosophical diatribe as to why you should embrace the data preparation. Live the data preparation. Be one with the data preparation.
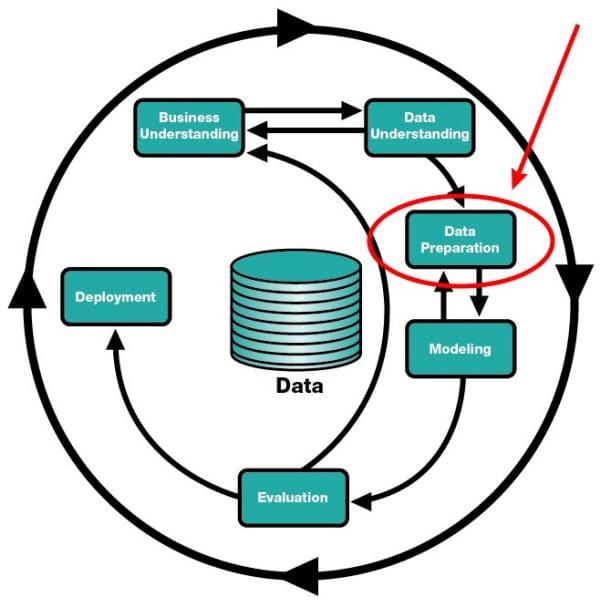
Data preparation in the CRISP-DM model.
Some of the best machine learning advice that I can think of is that since you are ultimately destined to spend so much of your time on preparing data for The Big Show, being determined to be the very best data preparation professional around is a pretty good goal. Since it's not only time-consuming but of great importance to the steps which follow (garbage in, garbage out), having a reputation as a bad-ass data preparer wouldn't be the worst thing in the world.
So yeah, while data preparation might take a while to perform and master, that's really not a bad thing. There is opportunity in this necessity, both to stand out in your role, as well as the intrinsic value of knowing you're good at your job.
For some more practical insight into data preparation, here are a couple of places to start out:
- 7 Steps to Mastering Data Preparation with Python
- Machine Learning Workflows in Python from Scratch Part 1: Data Preparation
2. The value of a performance baseline
So you have modeled some data with a particular algorithm, spent time tuning your hyperparameters, performed some feature engineering and/or selection, and you're happy that you have squeezed out a training accuracy of, say, 75%. You pat yourself on the back for all of your hard work.
But what are you comparing your results to? If you don't have a baseline -- a simple sanity check consists of comparing one’s estimator against simple rules of thumb -- then you are literally comparing that hard work to nothing. It's reasonable to assume that almost any accuracy could be considered back pat-worthy without something with which to compare it.
Random guessing isn't the best strategy for a baseline; instead, accepted methods exist for determining a baseline accuracy for comparison. Scikit-learn, for example, provides a series of baseline classifiers in its DummyClassifier class:
stratifiedgenerates random predictions by respecting the training set class distribution.most_frequentalways predicts the most frequent label in the training set.prioralways predicts the class that maximizes the class prior (likemost_frequent`) and ``predict_probareturns the class prior.uniformgenerates predictions uniformly at random.constantalways predicts a constant label that is provided by the user.
Baselines aren't just for classifiers, either; statistical methods exist for baselining regression tasks, for example.
After exploratory data analysis and data preparation and preprocessing, establishing a baseline is a logical next step in your machine learning workflow.
3. Validation: Beyond training and testing
When we build machine learning models, we train them using training data. When we test the resulting models, we use testing data. So where does validation come in?
Rachel Thomas of fast.ai recently wrote a solid treatment of how and why to create good validation sets. In it, she covered these 3 types of data as follows:
- the training set is used to train a given model
- the validation set is used to choose between models (for instance, does a random forest or a neural net work better for your problem? do you want a random forest with 40 trees or 50 trees?)
- the test set tells you how you’ve done. If you’ve tried out a lot of different models, you may get one that does well on your validation set just by chance, and having a test set helps make sure that is not the case.

Source: Andrew Ng's Machine Learning class at Stanford
So, is randomly splitting your data into test, train, and validation sets always a good idea? As it turns out, no. Rachel addresses this in the context of time series data:
Kaggle currently has a competition to predict the sales in a chain of Ecuadorian grocery stores. Kaggle’s “training data” runs from Jan 1 2013 to Aug 15 2017 and the test data spans Aug 16 2017 to Aug 31 2017. A good approach would be to use Aug 1 to Aug 15 2017 as your validation set, and all the earlier data as your training set.
Much of the rest of the post relates dataset splitting to Kaggle competition data, which is practical information, as well as roping cross-validation into the discussion, which I will leave for you to seek out yourself.
Other times, random splits of data will be useful; it depends on further factors such as the state of the data when you get it (is it split into train/test already?), as well as what type of data it is (see the time series excerpt above).
For when random splits are feasible, Scikit-learn may not have a train_validate_test_split method, but you can leverage standard Python libraries to create your own, such as that which is found here.
4. There is more to ensembles than a bunch of trees
Algorithm selection can be challenging for machine learning newcomers. Often when building classifiers, especially for beginners, an approach is adopted to problem solving which considers single instances of single algorithms.
However, in a given scenario, it may prove more useful to chain or group classifiers together, using the techniques of voting, weighting, and combination to pursue the most accurate classifier possible. Ensemble learners are classifiers which provide this functionality in a variety of ways.
Random Forests is a very prominent example of an ensemble learner, which uses numerous decision trees in a single predictive model. Random Forests have been applied to problems with great success, and are celebrated accordingly. But they are not the only ensemble method which exists, and numerous others are also worthy of a look.
Bagging operates by simple concept: build a number of models, observe the results of these models, and settle on the majority result. I recently had an issue with the rear axle assembly in my car: I wasn't sold on the diagnosis of the dealership, and so I took it to 2 other garages, both of which agreed the issue was something different than the dealership suggested. Voila. Bagging in action. Random Forests are based on modified bagging techniques.
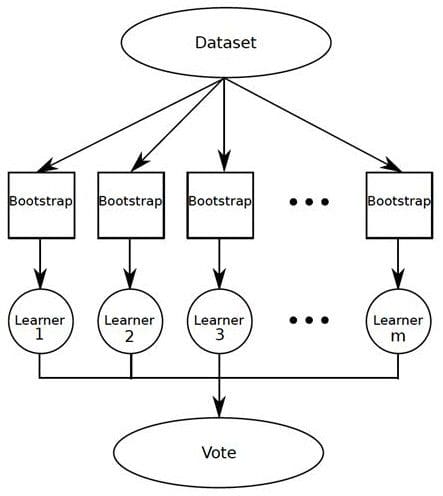
Bagging, or bootstrap aggregation.
Boosting is similar to bagging, but with one conceptual modification. Instead of assigning equal weighting to models, boosting assigns varying weights to classifiers, and derives its ultimate result based on weighted voting.
Thinking again of my car problem, perhaps I had been to one particular garage numerous times in the past, and trusted their diagnosis slightly more than others. Also suppose that I was not a fan of previous interactions with the dealership, and that I trusted their insight less. The weights I assigned would be reflective.
Stacking is a bit different from the previous 2 techniques as it trains multiple single classifiers, as opposed to various incarnations of the same learner. While bagging and boosting would use numerous models built using various instances of the same classification algorithm (eg. decision tree), stacking builds its models using different classification algorithms (perhaps decision trees, logistic regression, an ANNs, or some other combination).
A combiner algorithm is then trained to make ultimate predictions using the predictions of other algorithms. This combiner can be any ensemble technique, but logistic regression is often found to be an adequate and simple algorithm to perform this combining. Along with classification, stacking can also be employed in unsupervised learning tasks such as density estimation.
For some additional detail, read this introduction to ensemble learners. You can read more on implementing ensembles in Python in this very thorough tutorial.
5. Google Colab?
Finally, let's look at something more practical. Jupyter Notebooks have become a de facto data science development tool, with most people running notebooks locally or via some other configuration-heavy method such as in Docker containers, or in a virtual machine. Google's Colaboratory is an initiative which allows for Jupyter-style and -compatible notebooks to be run directly in your Google Drive, free of configuration.
Colaboratory is pre-configured with a number of the most popular Python libraries, and more can be installed within the notebooks themselves thanks to supported package management. For instance, TensorFlow is included, but Keras is not, yet installing Keras via pip takes a matter of seconds.
In what is likely the best news, if you are working with neural networks you can use GPU hardware acceleration in your training for free for up to 12 hours at a time. This isn't the panacea it may first seem to be, but it's an added bonus, and a good start to democratizing GPU access.
Read 3 Essential Google Colaboratory Tips & Tricks for more information on how to take advantage of Colaboratory's notebooks in the cloud.
Related:
- 5 Things You Need To Know About Data Science
- 7 Steps to Mastering Machine Learning With Python
- 4 Things You Probably Didn’t Know Machine Learning and AI was used for