 Text Data Preprocessing: A Walkthrough in Python
Text Data Preprocessing: A Walkthrough in Python
 Text Data Preprocessing: A Walkthrough in Python
Text Data Preprocessing: A Walkthrough in PythonThis post will serve as a practical walkthrough of a text data preprocessing task using some common Python tools.
In a pair of previous posts, we first discussed a framework for approaching textual data science tasks, and followed that up with a discussion on a general approach to preprocessing text data. This post will serve as a practical walkthrough of a text data preprocessing task using some common Python tools.
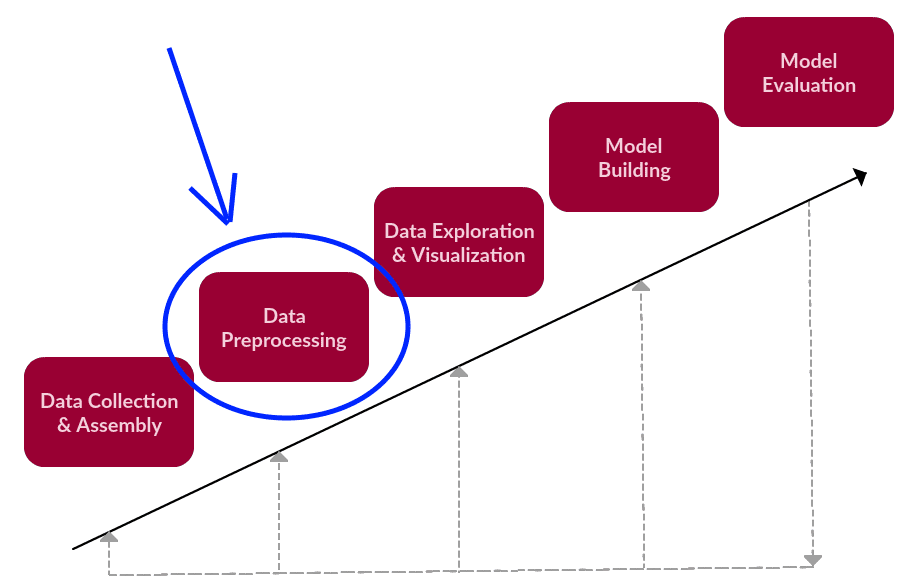
Preprocessing, in the context of the textual data science framework.
Our goal is to go from what we will describe as a chunk of text (not to be confused with text chunking), a lengthy, unprocessed single string, and end up with a list (or several lists) of cleaned tokens that would be useful for further text mining and/or natural language processing tasks.
First we start with our imports.
Beyond the standard Python libraries, we are also using the following:
- NLTK - The Natural Language ToolKit is one of the best-known and most-used NLP libraries in the Python ecosystem, useful for all sorts of tasks from tokenization, to stemming, to part of speech tagging, and beyond
- BeautifulSoup - BeautifulSoup is a useful library for extracting data from HTML and XML documents
- Inflect - This is a simple library for accomplishing the natural language related tasks of generating plurals, singular nouns, ordinals, and indefinite articles, and (of most interest to us) converting numbers to words
- Contractions - Another simple library, solely for expanding contractions
If you have NLTK installed, yet require the download of its any additional data, see here.
We need some sample text. We'll start with something very small and artificial in order to easily see the results of what we are doing step by step.
A toy dataset indeed, but make no mistake; the steps we are taking here to preprocessing this data are fully transferable.
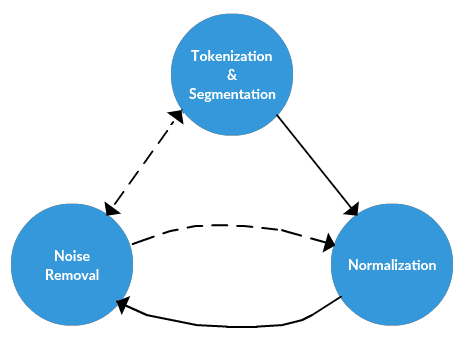
The text data preprocessing framework.
Noise Removal
Let's loosely define noise removal as text-specific normalization tasks which often take place prior to tokenization. I would argue that, while the other 2 major steps of the preprocessing framework (tokenization and normalization) are basically task-independent, noise removal is much more task-specific.
Sample noise removal tasks could include:
- removing text file headers, footers
- removing HTML, XML, etc. markup and metadata
- extracting valuable data from other formats, such as JSON
As you can imagine, the boundary between noise removal and data collection and assembly, on the one hand, is a fuzzy one, while the line between noise removal and normalization is blurred on the other. Given its close relationship with specific texts and their collection and assembly, many denoising tasks, such as parsing a JSON structure, would obviously need to be implemented prior to tokenization.
In our data preprocessing pipeline, we will strip away HTML markup with the help of the BeautifulSoup library, and use regular expressions to remove open and close double brackets and anything in between them (we assume this is necessary based on our sample text).
While not mandatory to do at this stage prior to tokenization (you'll find that this statement is the norm for the relatively flexible ordering of text data preprocessing tasks), replacing contractions with their expansions can be beneficial at this point, since our word tokenizer will split words like "didn't" into "did" and "n't." It's not impossible to remedy this tokenization at a later stage, but doing so prior makes it easier and more straightforward.
And here is the result of de-noising on our sample text.
Title Goes Here
Bolded Text
Italicized Text
But this will still be here!
I run. He ran. She is running. Will they stop running?
I talked. She was talking. They talked to them about running. Who ran to the talking runner?
¡Sebastián, Nicolás, Alejandro and Jéronimo are going to the store tomorrow morning!
something... is! wrong() with.,; this :: sentence.
I cannot do this anymore. I did not know them. Why could not you have dinner at the restaurant?
My favorite movie franchises, in order: Indiana Jones; Marvel Cinematic Universe; Star Wars; Back to the Future; Harry Potter.
do not do it.... Just do not. Billy! I know what you are doing. This is a great little house you have got here.
John: "Well, well, well."
James: "There, there. There, there."
There are a lot of reasons not to do this. There are 101 reasons not to do it. 1000000 reasons, actually.
I have to go get 2 tutus from 2 different stores, too.
22 45 1067 445
{{Here is some stuff inside of double curly braces.}}
{Here is more stuff in single curly braces.}
Tokenization
Tokenization is a step which splits longer strings of text into smaller pieces, or tokens. Larger chunks of text can be tokenized into sentences, sentences can be tokenized into words, etc. Further processing is generally performed after a piece of text has been appropriately tokenized. Tokenization is also referred to as text segmentation or lexical analysis. Sometimes segmentation is used to refer to the breakdown of a large chunk of text into pieces larger than words (e.g. paragraphs or sentences), while tokenization is reserved for the breakdown process which results exclusively in words.
For our task, we will tokenize our sample text into a list of words. This is done using NTLK's word_tokenize() function.
And here are our word tokens:
['Title', 'Goes', 'Here', 'Bolded', 'Text', 'Italicized', 'Text', 'But', 'this', 'will', 'still',
'be', 'here', '!', 'I', 'run', '.', 'He', 'ran', '.', 'She', 'is', 'running', '.', 'Will', 'they',
'stop', 'running', '?', 'I', 'talked', '.', 'She', 'was', 'talking', '.', 'They', 'talked', 'to', 'them',
'about', 'running', '.', 'Who', 'ran', 'to', 'the', 'talking', 'runner', '?', '¡Sebastián', ',',
'Nicolás', ',', 'Alejandro', 'and', 'Jéronimo', 'are', 'going', 'tot', 'he', 'store', 'tomorrow',
'morning', '!', 'something', '...', 'is', '!', 'wrong', '(', ')', 'with.', ',', ';', 'this', ':', ':',
'sentence', '.', 'I', 'can', 'not', 'do', 'this', 'anymore', '.', 'I', 'did', 'not', 'know', 'them', '.',
'Why', 'could', 'not', 'you', 'have', 'dinner', 'at', 'the', 'restaurant', '?', 'My', 'favorite',
'movie', 'franchises', ',', 'in', 'order', ':', 'Indiana', 'Jones', ';', 'Star', 'Wars', ';', 'Marvel',
'Cinematic', 'Universe', ';', 'Back', 'to', 'the', 'Future', ';', 'Harry', 'Potter', '.', 'do', 'not',
'do', 'it', '...', '.', 'Just', 'do', 'not', '.', 'Billy', '!', 'I', 'know', 'what', 'you', 'are',
'doing', '.', 'This', 'is', 'a', 'great', 'little', 'house', 'you', 'have', 'got', 'here', '.', 'John',
':', '``', 'Well', ',', 'well', ',', 'well', '.', "''", 'James', ':', '``', 'There', ',', 'there', '.',
'There', ',', 'there', '.', "''", 'There', 'are', 'a', 'lot', 'of', 'reasons', 'not', 'to', 'do', 'this',
'.', 'There', 'are', '101', 'reasons', 'not', 'to', 'do', 'it', '.', '1000000', 'reasons', ',',
'actually', '.', 'I', 'have', 'to', 'go', 'get', '2', 'tutus', 'from', '2', 'different', 'stores', ',',
'too', '.', '22', '45', '1067', '445', '{', '{', 'Here', 'is', 'some', 'stuff', 'inside', 'of', 'double',
'curly', 'braces', '.', '}', '}', '{', 'Here', 'is', 'more', 'stuff', 'in', 'single', 'curly', 'braces',
'.', '}']
Normalization
Normalization generally refers to a series of related tasks meant to put all text on a level playing field: converting all text to the same case (upper or lower), removing punctuation, converting numbers to their word equivalents, and so on. Normalization puts all words on equal footing, and allows processing to proceed uniformly.
Normalizing text can mean performing a number of tasks, but for our framework we will approach normalization in 3 distinct steps: (1) stemming, (2) lemmatization, and (3) everything else. For specifics on what these distinct steps may be, see this post.
Remember, after tokenization, we are no longer working at a text level, but now at a word level. Our normalization functions, shown below, reflect this. Function names and comments should provide the necessary insight into what each does.
After calling the normalization function:
['title', 'goes', 'bolded', 'text', 'italicized', 'text', 'still', 'run', 'ran', 'running', 'stop', 'running', 'talked', 'talking', 'talked', 'running', 'ran', 'talking', 'runner', 'sebastian', 'nicolas', 'alejandro', 'jeronimo', 'going', 'store', 'tomorrow', 'morning', 'something', 'wrong', 'sentence', 'anymore', 'know', 'could', 'dinner', 'restaurant', 'favorite', 'movie', 'franchises', 'order', 'indiana', 'jones', 'marvel', 'cinematic', 'universe', 'star', 'wars', 'back', 'future', 'harry', 'potter', 'billy', 'know', 'great', 'little', 'house', 'got', 'john', 'well', 'well', 'well', 'james', 'lot', 'reasons', 'one hundred and one', 'reasons', 'one million', 'reasons', 'actually', 'go', 'get', 'two', 'tutus', 'two', 'different', 'stores', 'twenty-two', 'forty-five', 'one thousand and sixty-seven', 'four hundred and forty-five', 'stuff', 'inside', 'double', 'curly', 'braces', 'stuff', 'single', 'curly', 'braces']
Calling the stemming and lemming functions are done as below:
This results in a return of 2 new lists: one of stemmed tokens, and another of lemmatized tokens with respect to verbs. Depending on your upcoming NLP task or preference, one of these may be more appropriate than the other. See here for a discussion on lemmatization vs. stemming.
Stemmed: ['titl', 'goe', 'bold', 'text', 'it', 'text', 'stil', 'run', 'ran', 'run', 'stop', 'run', 'talk', 'talk', 'talk', 'run', 'ran', 'talk', 'run', 'sebast', 'nicola', 'alejandro', 'jeronimo', 'going', 'stor', 'tomorrow', 'morn', 'someth', 'wrong', 'sent', 'anym', 'know', 'could', 'din', 'resta', 'favorit', 'movy', 'franch', 'ord', 'indian', 'jon', 'marvel', 'cinem', 'univers', 'star', 'war', 'back', 'fut', 'harry', 'pot', 'bil', 'know', 'gre', 'littl', 'hous', 'got', 'john', 'wel', 'wel', 'wel', 'jam', 'lot', 'reason', 'one hundred and on', 'reason', 'one million', 'reason', 'act', 'go', 'get', 'two', 'tut', 'two', 'diff', 'stor', 'twenty-two', 'forty-five', 'one thousand and sixty-seven', 'four hundred and forty-five', 'stuff', 'insid', 'doubl', 'cur', 'brac', 'stuff', 'singl', 'cur', 'brac'] Lemmatized: ['title', 'go', 'bolded', 'text', 'italicize', 'text', 'still', 'run', 'run', 'run', 'stop', 'run', 'talk', 'talk', 'talk', 'run', 'run', 'talk', 'runner', 'sebastian', 'nicolas', 'alejandro', 'jeronimo', 'go', 'store', 'tomorrow', 'morning', 'something', 'wrong', 'sentence', 'anymore', 'know', 'could', 'dinner', 'restaurant', 'favorite', 'movie', 'franchise', 'order', 'indiana', 'jones', 'marvel', 'cinematic', 'universe', 'star', 'war', 'back', 'future', 'harry', 'potter', 'billy', 'know', 'great', 'little', 'house', 'get', 'john', 'well', 'well', 'well', 'jam', 'lot', 'reason', 'one hundred and one', 'reason', 'one million', 'reason', 'actually', 'go', 'get', 'two', 'tutus', 'two', 'different', 'store', 'twenty-two', 'forty-five', 'one thousand and sixty-seven', 'four hundred and forty-five', 'stuff', 'inside', 'double', 'curly', 'brace', 'stuff', 'single', 'curly', 'brace']
And there you have a walkthrough of a simple text data preprocessing process using Python on a sample piece of text. I would encourage you to perform these tasks on some additional texts to verify the results. We will use this same process to clean the text data for our next task, in which we will undertake some actual NLP task, as opposed to spending time preparing our data for such an actual task.
Related:
- A General Approach to Preprocessing Text Data
- A Framework for Approaching Textual Data Science Tasks
- Natural Language Processing Key Terms, Explained