A General Approach to Preprocessing Text Data
Recently we had a look at a framework for textual data science tasks in their totality. Now we focus on putting together a generalized approach to attacking text data preprocessing, regardless of the specific textual data science task you have in mind.
Recently we looked at a framework for approaching textual data science tasks. We kept said framework sufficiently general such that it could be useful and applicable to any text mining and/or natural language processing task.
The high-level steps for the framework were as follows:
- Data Collection or Assembly
- Data Preprocessing
- Data Exploration & Visualization
- Model Building
- Model Evaluation
Though such a framework would, by nature, be iterative, we originally demonstrated it visually as a rather linear process. This update should put its true nature in perspective (with an obvious nod to the KDD Process):
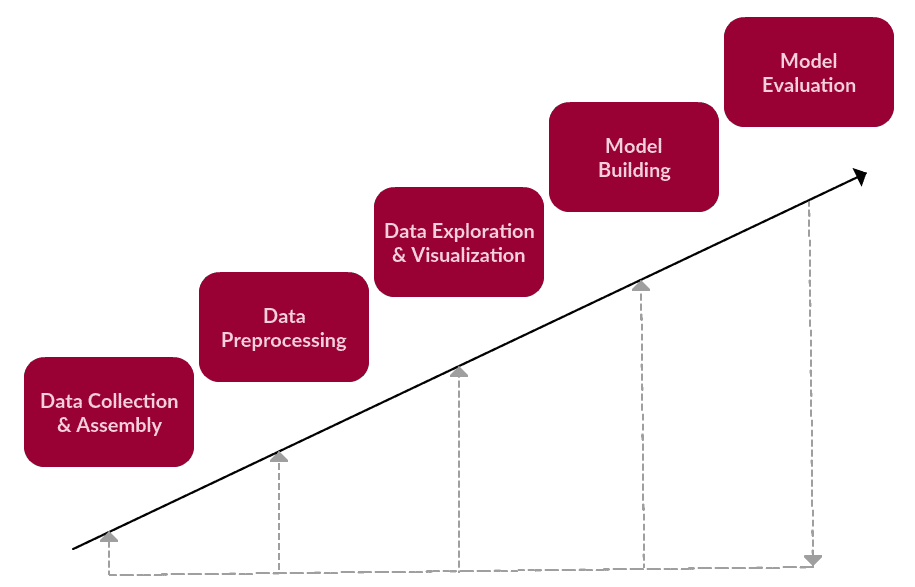
A revised (but still simple) textual data task framework.
Clearly, any framework focused on the preprocessing of textual data would have to be synonymous with step number 2. Expanding upon this step, specifically, we had the following to say about what this step would likely entail:
- Perform the preparation tasks on the raw text corpus in anticipation of text mining or NLP task
- Data preprocessing consists of a number of steps, any number of which may or not apply to a given task, but generally fall under the broad categories of tokenization, normalization, and substitution
More generally, we are interested in taking some predetermined body of text and performing upon it some basic analysis and transformations, in order to be left with artefacts which will be much more useful for performing some further, more meaningful analytic task afterward. This further task would be our core text mining or natural language processing work.
So, as mentioned above, it seems as though there are 3 main components of text preprocessing:
- tokenization
- normalization
- subsitution
As we lay out a framework for approaching preprocessing, we should keep these high-level concepts in mind.
Text Preprocessing Framework
We will introduce this framework conceptually, independent of tools. We will then followup with a practical implementation of these steps next time, in order to see how they would be carried out in the Python ecosystem.
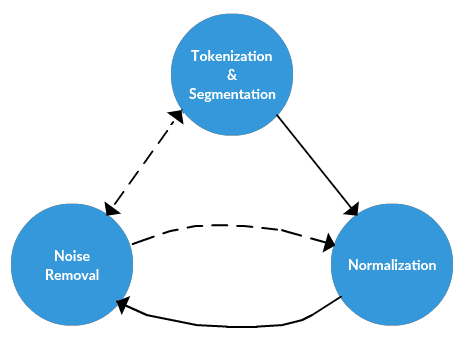
The text data preprocessing framework.
1 - Tokenization
Tokenization is a step which splits longer strings of text into smaller pieces, or tokens. Larger chunks of text can be tokenized into sentences, sentences can be tokenized into words, etc. Further processing is generally performed after a piece of text has been appropriately tokenized. Tokenization is also referred to as text segmentation or lexical analysis. Sometimes segmentation is used to refer to the breakdown of a large chunk of text into pieces larger than words (e.g. paragraphs or sentences), while tokenization is reserved for the breakdown process which results exclusively in words.
This may sound like a straightforward process, but it is anything but. How are sentences identified within larger bodies of text? Off the top of your head you probably say "sentence-ending punctuation," and may even, just for a second, think that such a statement is unambiguous.
Sure, this sentence is easily identified with some basic segmentation rules:
The quick brown fox jumps over the lazy dog.
But what about this one:
Dr. Ford did not ask Col. Mustard the name of Mr. Smith's dog.
Or this one:
"What is all the fuss about?" asked Mr. Peters.
And that's just sentences. What about words? Easy, right? Right?
This full-time student isn't living in on-campus housing, and she's not wanting to visit Hawai'i.
It should be intuitive that there are varying strategies not only for identifying segment boundaries, but also what to do when boundaries are reached. For example, we might employ a segmentation strategy which (correctly) identifies a particular boundary between word tokens as the apostrophe in the word she's (a strategy tokenizing on whitespace alone would not be sufficient to recognize this). But we could then choose between competing strategies such as keeping the punctuation with one part of the word, or discarding it altogether. One of these approaches just seems correct, and does not seem to pose a real problem. But just think of all the other special cases in just the English language we would have to take into account.
Consideration: when we segment text chunks into sentences, should we preserve sentence-ending delimiters? Are we interested in remembering where sentences ended?
2 - Normalization
Before further processing, text needs to be normalized. Normalization generally refers to a series of related tasks meant to put all text on a level playing field: converting all text to the same case (upper or lower), removing punctuation, converting numbers to their word equivalents, and so on. Normalization puts all words on equal footing, and allows processing to proceed uniformly.
Normalizing text can mean performing a number of tasks, but for our framework we will approach normalization in 3 distinct steps: (1) stemming, (2) lemmatization, and (3) everything else.
Stemming
Stemming is the process of eliminating affixes (suffixed, prefixes, infixes, circumfixes) from a word in order to obtain a word stem.
Lemmatization
Lemmatization is related to stemming, differing in that lemmatization is able to capture canonical forms based on a word's lemma.
For example, stemming the word "better" would fail to return its citation form (another word for lemma); however, lemmatization would result in the following:
It should be easy to see why the implementation of a stemmer would be the less difficult feat of the two.
Everything else
A clever catch-all, right? Stemming and lemmatization are major parts of a text preprocessing endeavor, and as such they need to be treated with the respect they deserve. These aren't simple text manipulation; they rely on detailed and nuanced understanding of grammatical rules and norms.
There are, however, numerous other steps that can be taken to help put all text on equal footing, many of which involve the comparatively simple ideas of substitution or removal. They are, however, no less important to the overall process. These include:
- set all characters to lowercase
- remove numbers (or convert numbers to textual representations)
- remove punctuation (generally part of tokenization, but still worth keeping in mind at this stage, even as confirmation)
- strip white space (also generally part of tokenization)
- remove default stop words (general English stop words)
Stop words are those words which are filtered out before further processing of text, since these words contribute little to overall meaning, given that they are generally the most common words in a language. For instance, "the," "and," and "a," while all required words in a particular passage, don't generally contribute greatly to one's understanding of content. As a simple example, the following panagram is just as legible if the stop words are removed:
- remove given (task-specific) stop words
- remove sparse terms (not always necessary or helpful, though!)
A this point, it should be clear that text preprocessing relies heavily on pre-built dictionaries, databases, and rules. You will be relieved to find that when we undertake a practical text preprocessing task in the Python ecosystem in our next article that these pre-built support tools are readily available for our use; there is no need to be inventing our own wheels.
3 - Noise Removal
Noise removal continues the substitution tasks of the framework. While the first 2 major steps of our framework (tokenization and normalization) were generally applicable as-is to nearly any text chunk or project (barring the decision of which exact implementation was to be employed, or skipping certain optional steps, such as sparse term removal, which simply does not apply to every project), noise removal is a much more task-specific section of the framework.
Keep in mind again that we are not dealing with a linear process, the steps of which must exclusively be applied in a specified order. Noise removal, therefore, can occur before or after the previously-outlined sections, or at some point between).
How about something more concrete. Let's assume we obtained a corpus from the world wide web, and that it is housed in a raw web format. We can, then, assume that there is a high chance our text could be wrapped in HTML or XML tags. While this accounting for metadata can take place as part of the text collection or assembly process (step 1 of our textual data task framework), it depends on how the data was acquired and assembled. This previous post outlines a simple process for obtaining raw Wikipedia data and building a corpus from it. As we have control of this data collection and assembly process, dealing with this noise (in a reproducible manner) at this time makes sense.
But this is not always the case. If the corpus you happen to be using is noisy, you have to deal with it. Recall that analytics tasks are often talked about as being 80% data preparation!
The good thing is that pattern matching can be your friend here, as can existing software tools built to deal with just such pattern matching tasks.
- remove text file headers, footers
- remove HTML, XML, etc. markup and metadata
- extract valuable data from other formats, such as JSON, or from within databases
- if you fear regular expressions, this could potentially be the part of text preprocessing in which your worst fears are realized
As you can imagine, the boundary between noise removal and data collection and assembly is a fuzzy one, and as such some noise removal must take place before other preprocessing steps. For example, any text required from a JSON structure would obviously need to be removed prior to tokenization.
In our next post, we will undertake a practical hands-on text preprocessing task, and the presence of task-specific noise will become evident... and will be dealt with.
Related:
- A Framework for Approaching Textual Data Science Tasks
- Building a Wikipedia Text Corpus for Natural Language Processing
- Natural Language Processing Key Terms, Explained