Robust Word2Vec Models with Gensim & Applying Word2Vec Features for Machine Learning Tasks
The gensim framework, created by Radim Řehůřek consists of a robust, efficient and scalable implementation of the Word2Vec model.
Editor's note: This post is only one part of a far more thorough and in-depth original, found here, which covers much more than what is included here.
Robust Word2Vec Models with Gensim
While our implementations are decent enough, they are not optimized enough to work well on large corpora. The gensim framework, created by Radim Řehůřek consists of a robust, efficient and scalable implementation of the Word2Vec model. We will leverage the same on our Bible corpus. In our workflow, we will tokenize our normalized corpus and then focus on the following four parameters in the Word2Vec model to build it.
size: The word embedding dimensionalitywindow: The context window sizemin_count: The minimum word countsample: The downsample setting for frequent words
After building our model, we will use our words of interest to see the top similar words for each of them.

The similar words here definitely are more related to our words of interest and this is expected given that we ran this model for more number of iterations which must have yield better and more contextual embeddings. Do you notice any interesting associations?

Noah’s sons come up as the most contextually similar entities from our model!
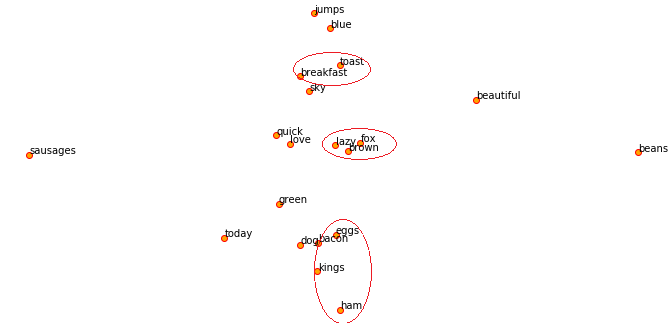
Let’s also visualize the words of interest and their similar words using their embedding vectors after reducing their dimensions to a 2-D space with t-SNE.

Visualizing our word2vec word embeddings using t-SNE
The red circles have been drawn by me to point out some interesting associations which I found out. We can clearly see based on what I depicted earlier that noah and his sons are quite close to each other based on the word embeddings from our model!
Applying Word2Vec features for Machine Learning Tasks
If you remember reading the previous article Part-3: Traditional Methods for Text Data you might have seen me using features for some actual machine learning tasks like clustering. Let’s leverage our other top corpus and try to achieve the same. To start with, we will build a simple Word2Vec model on the corpus and visualize the embeddings.
Visualizing word2vec word embeddings on our toy corpus
Remember that our corpus is extremely small so to get meaninful word embeddings and for the model to get more context and semantics, more data helps. Now what is a word embedding in this scenario? It’s typically a dense vector for each word as depicted in the following example for the word sky.
w2v_model.wv['sky'] Output ------ array([ 0.04576328, 0.02328374, -0.04483001, 0.0086611 , 0.05173225, 0.00953358, -0.04087641, -0.00427487, -0.0456274 , 0.02155695], dtype=float32)
Now suppose we wanted to cluster the eight documents from our toy corpus, we would need to get the document level embeddings from each of the words present in each document. One strategy would be to average out the word embeddings for each word in a document. This is an extremely useful strategy and you can adopt the same for your own problems. Let’s apply this now on our corpus to get features for each document.
Document level embeddings
Now that we have our features for each document, let’s cluster these documents using the Affinity Propagation algorithm, which is a clustering algorithm based on the concept of “message passing” between data points and does not need the number of clusters as an explicit input which is often required by partition-based clustering algorithms.

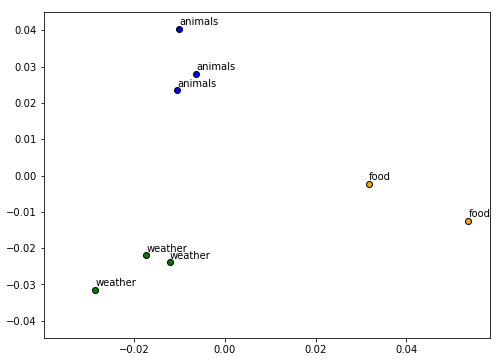
Clusters assigned based on our document features from word2vec
We can see that our algorithm has clustered each document into the right group based on our Word2Vec features. Pretty neat! We can also visualize how each document in positioned in each cluster by using Principal Component Analysis (PCA) to reduce the feature dimensions to 2-D and then visualizing the same (by color coding each cluster).
Visualizing our document clusters
Everything looks to be in order as documents in each cluster are closer to each other and far apart from other clusters.
Bio: Dipanjan Sarkar is a Data Scientist @Intel, an author, a mentor @Springboard, a writer, and a sports and sitcom addict.
Original. Reposted with permission.
Related:
- Text Data Preprocessing: A Walkthrough in Python
- A General Approach to Preprocessing Text Data
- A Framework for Approaching Textual Data Science Tasks