5 reasons data analytics are falling short
When it comes to big data, possession is not enough. Comprehensive intelligence is the key. But traditional data analytics paradigms simply cannot deliver on the promise of data-driven insights. Here’s why.
By Ami Gal, CEO SQream
“Possession is nine-tenths of the law,” goes the adage, which was traditionally applied to land rights, among other areas. The idea is that ownership was easier to enforce if you already had possession. Possession, thus, was valuable in and of itself.
But in the realm of big data, possession means far, far less than comprehension. Because while you might be able to make a living raising cows and chickens on 40 acres of land, 40 petabytes of data are next to worthless unless you can derive valuable insights from them.
And this is the crux: today, you really can’t derive insights of significant value from your big data using solutions from a different data era - at least not within a timeframe appropriate to the speed of business, or a budget that suits… well, your budget.
This means that even though a majority of companies are now trying to use big data to drive decision-making, big data analytics are falling short. The promise of real-time data-driven insights at scale, that truly impact the bottom line, is still far from a reality. Here’s why:
PROBLEM #1 – Too much data
This is the mother of all problems and it trickles down to everything else. The world is simply creating too much data – so much that Amazon is literally shipping it in trucks. A recent IDC report projects overall worldwide daily data creation to grow from 44 billion GB in 2016 to 463 billion GB in 2025. Organizations worldwide are suffering from data overload, and the data is still streaming in - from IoT, the connected world, websites, digital support centers, and more. Spoiler alert: market estimates show that as little as 1% of this data is currently being analyzed (see below).
PROBLEM #2 – Restrictive data pre-modeling
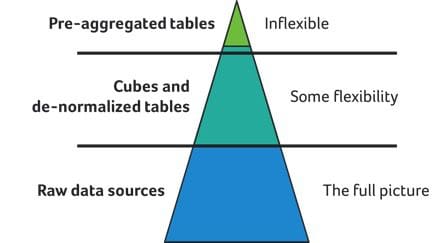
One of the key functions of data scientists today is creating effective data models. The problem is, to handle big data, some data models presuppose answers. De-normalizing, pre-aggregations, and cubing mean that you can only query the models you created, and you can't query the actual raw, underlying data. The reduced granularity stymies curiosity. So, while your data scientists can analyze some parts of the data, other parts remain hidden behind pre-aggregated tables and views. In fact, data consumers are highly aware of the restrictive modeling problem and are taking matters into their own hands. Gartner recently predicted that by 2019, self-service analytics and hands-on BI users will actually analyze more data than data scientists.
PROBLEM #3 – The price tag
In terms of storage and processing power, big data analytics costs big. How big? According to last year’s IDC Worldwide Semiannual Big Data and Analytics Spending Guide, overall spending on big data and data analytics services, tools, and applications will reach over $187 billion in 2019.
But more crucial than actual cost is cost-effectiveness. Because even as budgets for big data analytics increase, efficiency decreases. It’s a simple equation: if you’re paying to store and process 100% of data produced but you are only able to cost, or time-effectively use 1%, there’s something very wrong.
PROBLEM #4 – Time-to-results
Speed of analysis is a direct derivative of data quantity and processing power. Given the budgetary imperatives discussed above and the inherent limitations of older data generation storage and processing paradigms, speed of analysis has become a huge impediment to big data analytics. We’ve met many companies whose mission-critical queries can take days or weeks, even as their business moves in increments of minutes.
PROBLEM #5 - How much big data is actually used
If you read the spoiler above, you already know the answer. But let’s drill down to this point more deeply.
In a report issued in 2016, McKinsey claimed that although 90% of data worldwide had been generated since 2014, only 1% of that data was being analyzed. Even if we generously hypothesize that improvements in BI and analytics tools have boosted that number to 10%, this still means that up to 90% of data churns in data lakes - untouched, unleveraged, and wholly unexamined by companies not doing big data analytics.
So the relevant question is, given current big data analytics paradigms - how much data can companies actually use in decision-making today? Today's CIOs are making decisions based on the data they can query, but what about the data they can’t analyze?
The Bottom Line
Having big data is one thing but understanding it is a whole other ball game. Deficiencies in today’s big data analytics paradigms result in missed opportunities. Companies operate without a comprehensive understanding of the business intelligence available to them and can’t fully identify, understand or react to market and business trends. Organizations that learn to turn data into actionable insights – to comprehend and not just possess – are the ones in true possession of value and business advancing competitive advantage.
Bio: Ami Gal is CEO & Co-founder at SQream , making a very fast Big SQL Database powered by GPUs at SQream Technologies, crunching all the way from a few Terabytes to Petabytes with high performance.
Related: